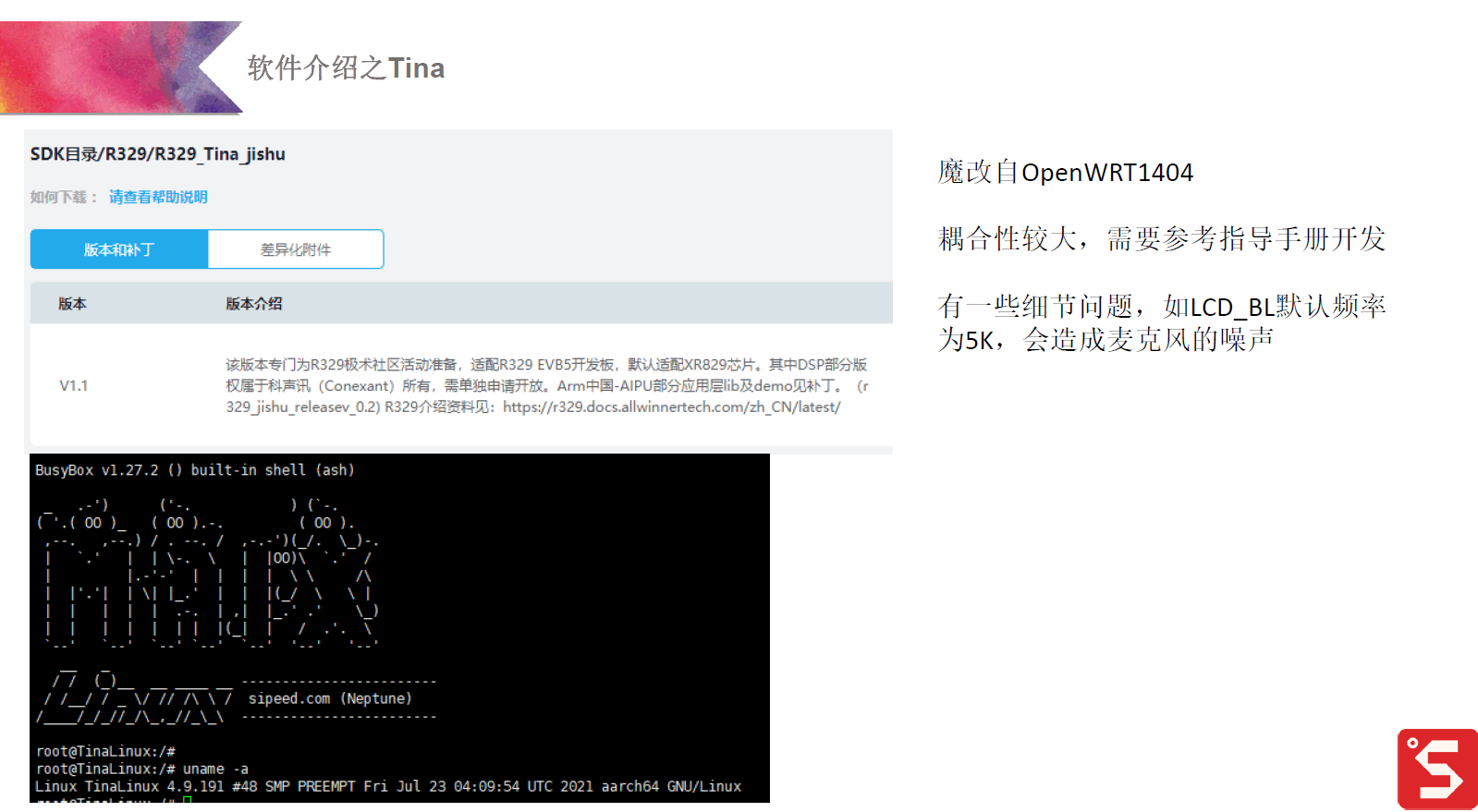
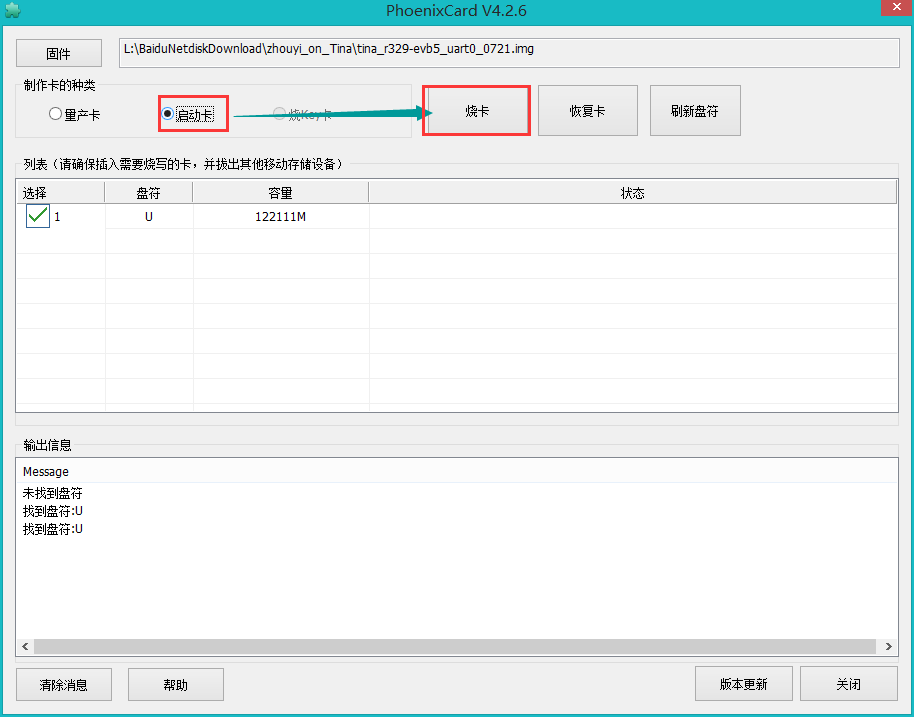
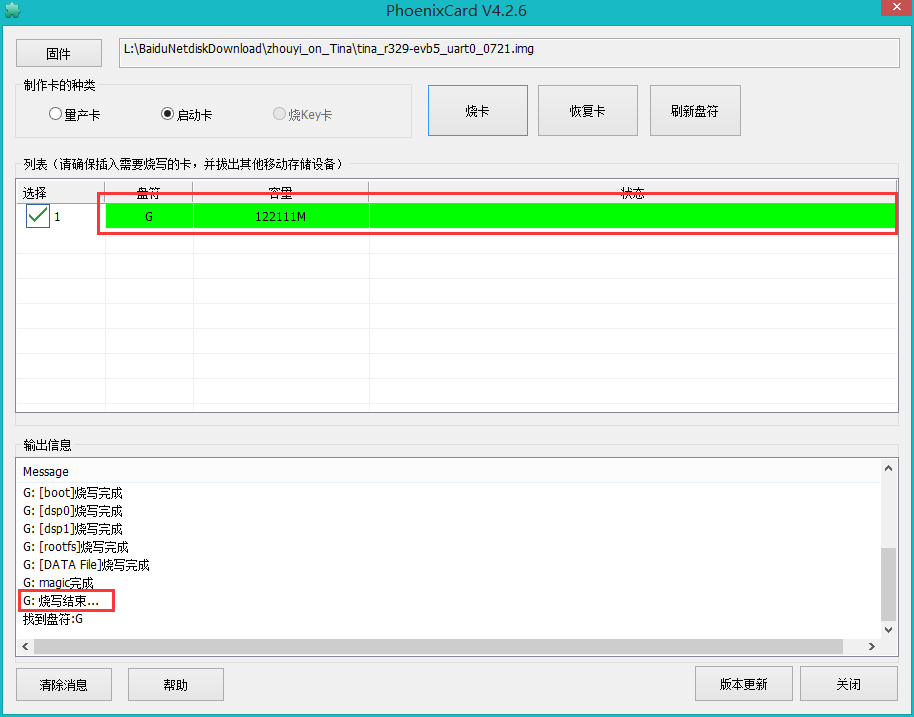
一、模型与算法
采用MIT开源的TSM算法,论文作者通过对特征进行shift操作,在不增加额外参数和算力的情况下进行时间建模,然后移植到了各种手机上进行了各种算法的对比。作者代码也移植到了jetson nano上能达到实时运行(没有使用CUDA),甚至在FPGA上也进行了移植,满满的工业风。
二、效果展示
模型backbone是mobileV2,然而运行只有18FPS,不应该啊,看了直播才知道,初代AIPU对分组卷积不太友好,ok好吧。我也尝试了在R329 CPU上运行,只有3FPS。模型在笔记本i7 cpu下TF pb模型能有65FPS,ONNX 120FPS。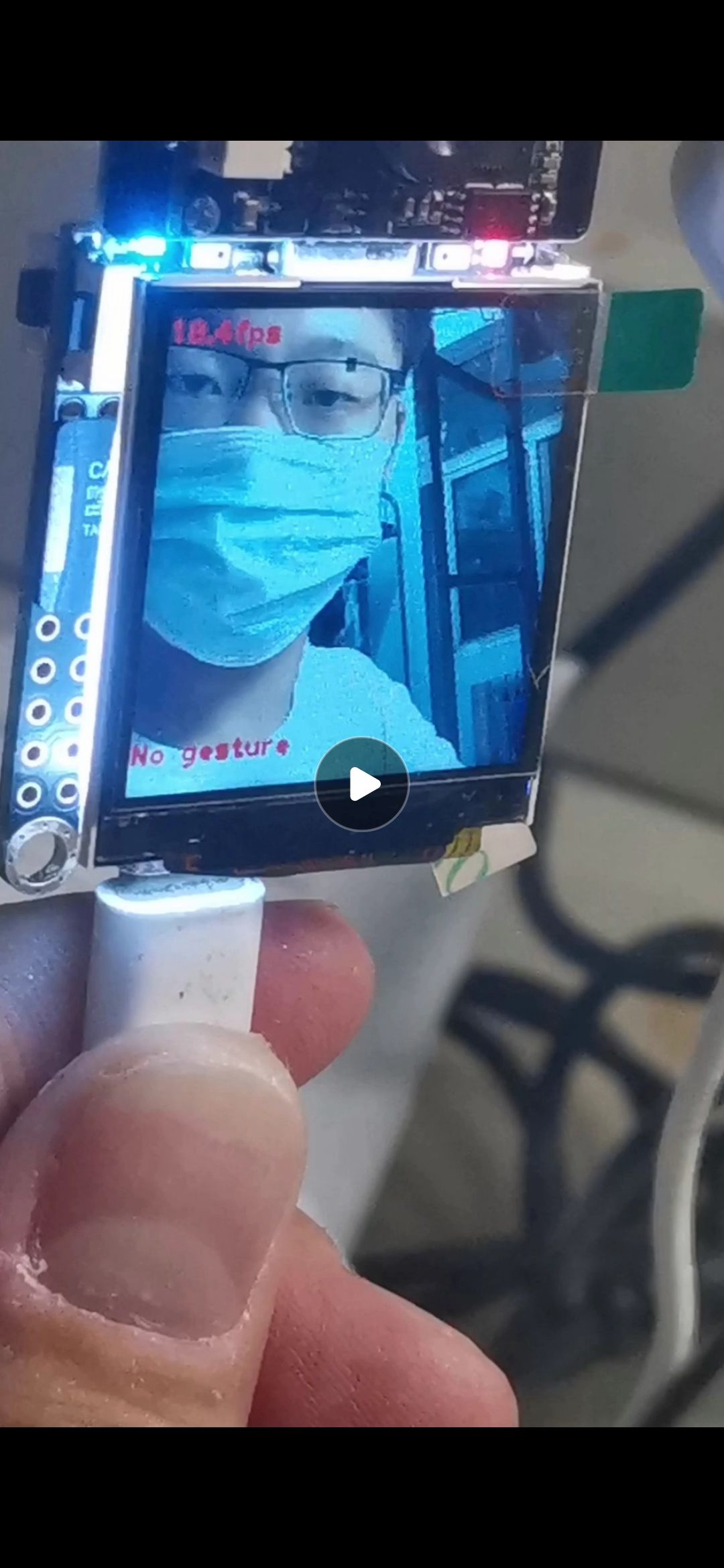
三、移植到AIPU
3.1模型量化
为了防止出现未知错误,我直接把作者的pytorch代码重构为TensoFlow代码,后面会开源。
由于涉及到时间建模,模型输入有11个输入矩阵。1个图像矩阵,10个转移矩阵,输出也是11个矩阵,1个分类矩阵,10个转移矩阵。
cfg配置如下:
[[Common]
mode = build
use_aqt = True
[Parser]
model_name = mobilenet_v2
model_type = tensorflow
detection_postprocess =
model_domain = image_classification
output = fully_connected/BiasAdd,Slice,Slice_2,Slice_4,Slice_6,Slice_8,Slice_10,Slice_12,Slice_14,Slice_16,Slice_18
input_model = ./input/model3.pb
input = x_input,x_input0,x_input1,x_input2,x_input3,x_input4,x_input5,x_input6,x_input7,x_input8,x_input9
input_shape = [1, 224, 224, 3],[1, 56, 56, 3],[1, 28, 28, 4],[1, 28, 28, 4],[1, 14, 14, 8],[1, 14, 14, 8],[1, 14, 14, 8],[1, 14, 14, 12],[1, 14, 14, 12],[1, 7, 7, 20],[1, 7, 7, 20]
output_dir = ./
[AutoQuantizationTool]
quantize_method = SYMMETRIC
quant_precision = int8
ops_per_channel = DepthwiseConv
reverse_rgb = False
label_id_offset =
dataset_name =
detection_postprocess =
anchor_generator =
ts_max_file = ./input/max_dict2.npy
ts_min_file = ./input/min_dict2.npy
[GBuilder]
outputs = aipu_mobilenet_v2Z2_1104.bin
target = Z1_0701]
由于模型涉及到多输入多输出,故不能直接使用训练集模型自动量化,所以需要手动求出每个节点的最值,按照技术手册里规定的格式,分别保存max,min的值为dict文件。
3.2模型推理
需要对输出结果微调,以下为推理和微调代码。
/**
* @file main.cpp
* @brief
*
* Copyright (c) 2021 Sipeed team
* ********************************
* Modify by @zhai
* *******************************
*/
extern "C" {
#include <stdio.h>
#include <unistd.h>
#include <stdint.h>
#include <string.h>
#include "fbviewer.h"
#include "label.h"
#include <sys/wait.h>
#include <sys/types.h>
}
#include "standard_api.h"
#include <iostream>
#include <sys/time.h>
#include<list>
#include<vector>
#include "opencv2/opencv.hpp"
using namespace cv;
#define DBG_LINE() printf("###L%d\r\n", __LINE__)
int label_oft = 0;
typedef struct {
int index;
int8_t val;
} int8_data_t;
typedef struct {
int index;
uint8_t val;
} uint8_data_t;
std::list<int8_t*> listbuffs;
int8_t flag_frame_num=0 ;
std::vector<int> history;
int FindMax(int8_t a[], int n, int*pMaxPos)
{
int i;
int8_t max;
max = a[0];
*pMaxPos = 0;
for (i=1; i<n; i++)
{
if (a[i] > max)
{
max = a[i];
*pMaxPos = i;
}
}
return max ;
}
cv::VideoCapture capture(0);
int init_cam(void)
{
int x,y;
getCurrentRes(&x, &y);
printf("LCD width is %d, height is %d\n", x, y);
cv::Mat img;
VideoCapture cap;
cap.isOpened();
if(!capture.isOpened())
{
std::cout<<"video not open."<<std::endl;
return 1;
}
//get default video fps, set fps to 30fps
double rate = capture.get(CAP_PROP_FPS);
printf("rate is %lf\n", rate);
capture.set(CAP_PROP_FPS, 30);
rate = capture.get(CAP_PROP_FPS);
printf("rate is %lf\n", rate);
//get default video frame info
double frame_width = capture.get(CAP_PROP_FRAME_WIDTH);
double frame_height = capture.get(CAP_PROP_FRAME_HEIGHT);
printf("frame_width is %lf, frame_height is %lf\n", frame_width, frame_height);
//set video frame size to QVGA (then we crop to 224x224)
frame_width = 320;
frame_height = 240;
if(!capture.set(CAP_PROP_FRAME_WIDTH,frame_width))
{
printf("set width failed\n");
return 2;
}
if(!capture.set(CAP_PROP_FRAME_HEIGHT, frame_height))
{
printf("set width failed\n");
return 3;
}
return 0;
}
int init_graph(char* file_model, aipu_ctx_handle_t ** ctx, aipu_graph_desc_t* gdesc, aipu_buffer_alloc_info_t* info)
{
const char* status_msg =NULL;
aipu_status_t status = AIPU_STATUS_SUCCESS;
int ret = 0;
//Step1: init ctx handle
status = AIPU_init_ctx(ctx);
if (status != AIPU_STATUS_SUCCESS) {
AIPU_get_status_msg(status, &status_msg);
printf("[DEMO ERROR] AIPU_init_ctx: %s\n", status_msg);
ret = -1;
//goto out;
}
//Step2: load graph
status = AIPU_load_graph_helper(*ctx, file_model, gdesc);
if (status != AIPU_STATUS_SUCCESS) {
AIPU_get_status_msg(status, &status_msg);
printf("[DEMO ERROR] AIPU_load_graph_helper: %s\n", status_msg);
ret = -2;
//goto deinit_ctx;
}
printf("[DEMO INFO] AIPU load graph successfully.\n");
//Step3: alloc tensor buffers
status = AIPU_alloc_tensor_buffers(*ctx, gdesc, info);
if (status != AIPU_STATUS_SUCCESS) {
AIPU_get_status_msg(status, &status_msg);
printf("[DEMO ERROR] AIPU_alloc_tensor_buffers: %s\n", status_msg);
ret = -3;
//goto unload_graph;
}
return ret;
}
int cap_img(Mat* lcd_frame, Mat* ai_frame)
{
Rect roi(40, 0, 240/4*3, 240); //16/9 -> 4/3
Rect input_roi(8, 8, 224, 224);
Size dsize = Size(240, 240);
if(!capture.read(*lcd_frame))
{
printf("no video frame\r\n");
return -1;
}
*lcd_frame = (*lcd_frame)(roi).clone();
rotate(*lcd_frame, *lcd_frame, ROTATE_180);
resize(*lcd_frame, *lcd_frame, dsize);
cvtColor(*lcd_frame, *lcd_frame, COLOR_BGR2RGB);
*ai_frame = (*lcd_frame)(input_roi).clone();
//*ai_frame = (*lcd_frame)(input_roi).clone() + Scalar(-123, -117,-104);
ai_frame->convertTo(*ai_frame,CV_16SC3);
add(Scalar(-127, -127,-127),*ai_frame,*ai_frame);
ai_frame->convertTo(*ai_frame,CV_8SC3);
return 0;
}
int infer_img(Mat* ai_frame,Mat* x0,Mat* x1,Mat* x2,Mat* x3,Mat* x4,Mat* x5,Mat* x6,Mat* x7,Mat* x8,Mat* x9, aipu_ctx_handle_t ** ctx, aipu_graph_desc_t* gdesc, aipu_buffer_alloc_info_t* info, int signed_flag, int* label_idx, int* label_prob)
{
uint32_t job_id=0;
const char* status_msg =NULL;
int32_t time_out=-1;
bool finish_job_successfully = true;
aipu_status_t status = AIPU_STATUS_SUCCESS;
int ret = 0;
//std::cout<<* ai_frame<<std::endl;
// printf("input_x:%d\n",info->inputs.tensors[0].size);
// printf("input_x0:%d\n",info->inputs.tensors[1].size);
// printf("input_x1:%d\n",info->inputs.tensors[2].size);
// printf("input_x2:%d\n",info->inputs.tensors[3].size);
// printf("input_x3:%d\n",info->inputs.tensors[4].size);
// printf("input_x4:%d\n",info->inputs.tensors[5].size);
// printf("input_x5:%d\n",info->inputs.tensors[6].size);
// printf("input_x6:%d\n",info->inputs.tensors[7].size);
// printf("input_x7:%d\n",info->inputs.tensors[8].size);
// printf("input_x8:%d\n",info->inputs.tensors[9].size);
// printf("input_x9:%d\n",info->inputs.tensors[10].size);
memcpy(info->inputs.tensors[0].va, ai_frame->data,info->inputs.tensors[0].size);
memcpy(info->inputs.tensors[1].va, x0->data, info->inputs.tensors[1].size);
memcpy(info->inputs.tensors[2].va, x1->data, info->inputs.tensors[2].size);
memcpy(info->inputs.tensors[3].va, x2->data,info->inputs.tensors[3].size);
memcpy(info->inputs.tensors[4].va, x3->data, info->inputs.tensors[4].size);
memcpy(info->inputs.tensors[5].va, x4->data,info->inputs.tensors[5].size);
memcpy(info->inputs.tensors[6].va, x5->data,info->inputs.tensors[6].size);
memcpy(info->inputs.tensors[7].va, x6->data, info->inputs.tensors[7].size);
memcpy(info->inputs.tensors[8].va, x7->data,info->inputs.tensors[8].size);
memcpy(info->inputs.tensors[9].va, x8->data, info->inputs.tensors[9].size);
memcpy(info->inputs.tensors[10].va, x9->data,info->inputs.tensors[10].size);
flag_frame_num=1;
status = AIPU_create_job(*ctx, gdesc, info->handle, &job_id);
//std::cout<<status<<std::endl;
if (status != AIPU_STATUS_SUCCESS) {
AIPU_get_status_msg(status, &status_msg);
printf("[DEMO ERROR] AIPU_create_job: %s\n", status_msg);
ret = -1;
//goto free_tensor_buffers;
}
status = AIPU_finish_job(*ctx, job_id, time_out);
if (status != AIPU_STATUS_SUCCESS) {
AIPU_get_status_msg(status, &status_msg);
printf("[DEMO ERROR] AIPU_finish_job: %s\n", status_msg);
finish_job_successfully = false;
} else {
finish_job_successfully = true;
}
if (finish_job_successfully) {
int8_t *result = (int8_t *)info->outputs.tensors[0].va;
uint32_t size = info->outputs.tensors[0].size;
int8_t *buff=(int8_t *)malloc(27*sizeof(int8_t));
memcpy(buff, result, sizeof(int8_t)*27);
if(listbuffs.size()>5){listbuffs.pop_front();}
listbuffs.push_back(buff);
int8_t *buffsum;
buffsum=(int8_t *)calloc(27,sizeof(int8_t));
int Len=listbuffs.size();
int k=0;
std::list<int8_t *>::iterator iter;
for(iter=listbuffs.begin();iter!=listbuffs.end();iter++){
for(k=0;k<27;k++){buffsum[k]=buffsum[k]+(*iter)[k];}
}
int i=0;
memcpy((x0->data),info->outputs.tensors[1].va, info->outputs.tensors[1].size);
memcpy((x1->data),info->outputs.tensors[2].va, info->outputs.tensors[2].size);
memcpy((x2->data),info->outputs.tensors[3].va, info->outputs.tensors[3].size);
memcpy((x3->data),info->outputs.tensors[4].va, info->outputs.tensors[4].size);
memcpy((x4->data),info->outputs.tensors[5].va, info->outputs.tensors[5].size);
memcpy((x5->data),info->outputs.tensors[6].va, info->outputs.tensors[6].size);
memcpy((x6->data),info->outputs.tensors[7].va, info->outputs.tensors[7].size);
memcpy((x7->data),info->outputs.tensors[8].va, info->outputs.tensors[8].size);
memcpy((x8->data),info->outputs.tensors[9].va, info->outputs.tensors[9].size);
memcpy((x9->data),info->outputs.tensors[10].va, info->outputs.tensors[10].size);
int idx;
FindMax(buffsum, 27, &idx);
printf("idx:%d\n",idx);
int label_covert=2;
int errors_fre[]={7, 8, 21, 22, 3,10,11,12,13};
i=0;
for(i=0;i<9;i++){
if(idx==errors_fre[i]){idx=history.back();}
}
if(idx==0){idx=history.back();}
if(idx!=history.back()){
if(history[history.size()-3]!=history.back()||history[history.size()-2]!=history.back()){idx=history.back();}
}
history.push_back(idx);
*label_idx=history.back();
if(history.size()>20){history.erase(history.begin());}
}
status = AIPU_clean_job(*ctx, job_id);
if (status != AIPU_STATUS_SUCCESS) {
AIPU_get_status_msg(status, &status_msg);
printf("[TEST ERROR] AIPU_clean_job: %s\n", status_msg);
ret = -2;
//goto free_tensor_buffers;
}
return ret;
}
float cal_fps(struct timeval start, struct timeval end)
{
struct timeval interval;
if (end.tv_usec >= start.tv_usec) {
interval.tv_usec = end.tv_usec - start.tv_usec;
interval.tv_sec = end.tv_sec - start.tv_sec;
} else {
interval.tv_usec = 1000000 + end.tv_usec - start.tv_usec;
interval.tv_sec = end.tv_sec - 1 - start.tv_sec;
}
float fps = 1000000.0 / interval.tv_usec;
return fps;
}
volatile int exit_flag = 0;
void my_handler(int s){
printf("Caught signal %d\n",s);
exit_flag = 1;
return;
}
int main(int argc, char *argv[])
{
int ret = 0;
uint32_t job_id=0;
int32_t time_out=-1;
bool finish_job_successfully = true;
int model_inw, model_inh, model_inch, model_outw, model_outh, model_outch, img_size;
int8_t* bmpbuf;
cv::Mat lcd_frame;
cv::Mat ai_frame;
int label_idx, label_prob;
struct timeval start, end;
int flag_frame=0;
float fps=0;
// cv::Mat x0 = cv::Mat::zeros(56,56 , CV_32FC(3));
// cv::Mat x1 = cv::Mat::zeros(28, 28, CV_32FC(4));
// cv::Mat x2 = cv::Mat::zeros(28, 28, CV_32FC(4));
// cv::Mat x3 = cv::Mat::zeros(14, 14, CV_32FC(8));
// cv::Mat x4 = cv::Mat::zeros(14,14 , CV_32FC(8));
// cv::Mat x5 = cv::Mat::zeros(14,14 , CV_32FC(8));
// cv::Mat x6 = cv::Mat::zeros(14, 14, CV_32FC(12));
// cv::Mat x7 = cv::Mat::zeros(14,14 , CV_32FC(12));
// cv::Mat x8 = cv::Mat::zeros(7,7 , CV_32FC(20));
// cv::Mat x9 = cv::Mat::zeros(7, 7, CV_32FC(20 ));
cv::Mat x0 = cv::Mat::zeros(56,56 , CV_8SC(3));
cv::Mat x1 = cv::Mat::zeros(28, 28, CV_8SC(4));
cv::Mat x2 = cv::Mat::zeros(28, 28, CV_8SC(4));
cv::Mat x3 = cv::Mat::zeros(14, 14, CV_8SC(8));
cv::Mat x4 = cv::Mat::zeros(14,14 , CV_8SC(8));
cv::Mat x5 = cv::Mat::zeros(14,14 , CV_8SC(8));
cv::Mat x6 = cv::Mat::zeros(14, 14, CV_8SC(12));
cv::Mat x7 = cv::Mat::zeros(14,14 , CV_8SC(12));
cv::Mat x8 = cv::Mat::zeros(7,7 , CV_8SC(20));
cv::Mat x9 = cv::Mat::zeros(7, 7, CV_8SC(20 ));
signal(SIGINT, my_handler);
history.push_back(2);
history.push_back(2);
printf("Zhouyi Cam test program: \r\n");
printf("Usage: \r\n");
printf(" ./zhouyi aipu.bin signed [label_oft]\r\n");
printf(" signed=0, uint8 output; =1, int8 output\r\n");
printf(" real_label_idx = predict_idx-label_oft, \r\n");
printf(" NOTE: default cal with 224x224\r\n");
aipu_ctx_handle_t * ctx = NULL;
aipu_status_t status = AIPU_STATUS_SUCCESS;
const char* status_msg =NULL;
aipu_graph_desc_t gdesc;
aipu_buffer_alloc_info_t info;
//Step 0: parse input argv
if(argc < 3) {
printf("argc=%d error\r\n", argc);
return -1;
}
if(argc >3) label_oft = atoi(argv[3]);
char* file_model= argv[1];
int signed_flag = 1;
//Step 1: set USB camera
ret = init_cam();DBG_LINE();
if(ret != 0) {
printf("[DEMO ERROR] init_cam err: %s\n", ret);
goto out;
}
//Step 2: init model graph
ret = init_graph(file_model, &ctx, &gdesc, &info);DBG_LINE();
if(ret == -1) goto out;
else if(ret == -2) goto deinit_ctx;
else if(ret == -3) goto unload_graph;
//MAIN LOOP
while(!exit_flag)
{
//1. cap cam img
if(cap_img(&lcd_frame, &ai_frame) != 0) {
break;
}
//2. infer cam img, get label
gettimeofday(&start, NULL);
if(flag_frame%2==0){
ret = infer_img(&ai_frame,&x0,&x1,&x2,&x3,&x4,&x5,&x6,&x7,&x8,&x9, &ctx, &gdesc, &info, signed_flag, &label_idx, &label_prob);
if(ret != 0) goto free_tensor_buffers;
gettimeofday(&end, NULL);
fps = cal_fps(start, end);
}
flag_frame+=1;
//3. draw lcd
flip(lcd_frame, lcd_frame, 1);
putText(lcd_frame, labels[label_idx], Point(0, 224), cv::FONT_HERSHEY_PLAIN, 1, Scalar(255,0,0), 2);
char fps_str[16];
sprintf(fps_str, "%.1ffps", fps);
putText(lcd_frame, fps_str, Point(0, 16), cv::FONT_HERSHEY_PLAIN, 1, Scalar(255,0,0), 2);
fb_display(lcd_frame.data, 0, 240, 240, 0, 0, 0, 0);
}
free_tensor_buffers:
status = AIPU_free_tensor_buffers(ctx, info.handle);
if (status != AIPU_STATUS_SUCCESS) {
AIPU_get_status_msg(status, &status_msg);
printf("[DEMO ERROR] AIPU_free_tensor_buffers: %s\n", status_msg);
ret = -1;
}
unload_graph:
status = AIPU_unload_graph(ctx, &gdesc);
if (status != AIPU_STATUS_SUCCESS) {
AIPU_get_status_msg(status, &status_msg);
printf("[DEMO ERROR] AIPU_unload_graph: %s\n", status_msg);
ret = -1;
}
deinit_ctx:
status = AIPU_deinit_ctx(ctx);
if (status != AIPU_STATUS_SUCCESS) {
AIPU_get_status_msg(status, &status_msg);
printf("[DEMO ERROR] AIPU_deinit_ctx: %s\n", status_msg);
ret = -1;
}
out:
return ret;
}
四、代码地址
https://github.com/ZhaiFengYun/R329-AIPU-gesture-recognition
(文章转载自:极术社区 zhai)
(原文链接:https://aijishu.com/a/1060000000230937 )