全志V853 NPU yolov3转化模型时量化未使用全部data图片
-
大佬们,我又来求助了。
主要有三个问题:
1.yolov3转化模型时量化未使用全部data图片
过程是这样的,在用 sample_odet_demo 使用自己训练模型后,同样的模型对比海思平台,实际检测效果不是特别好。检查了下过程,发现量化时 不管放了多少张图片,但实际只使用了一张图片。怀疑是这里影响了检测效果?
验证1如下:
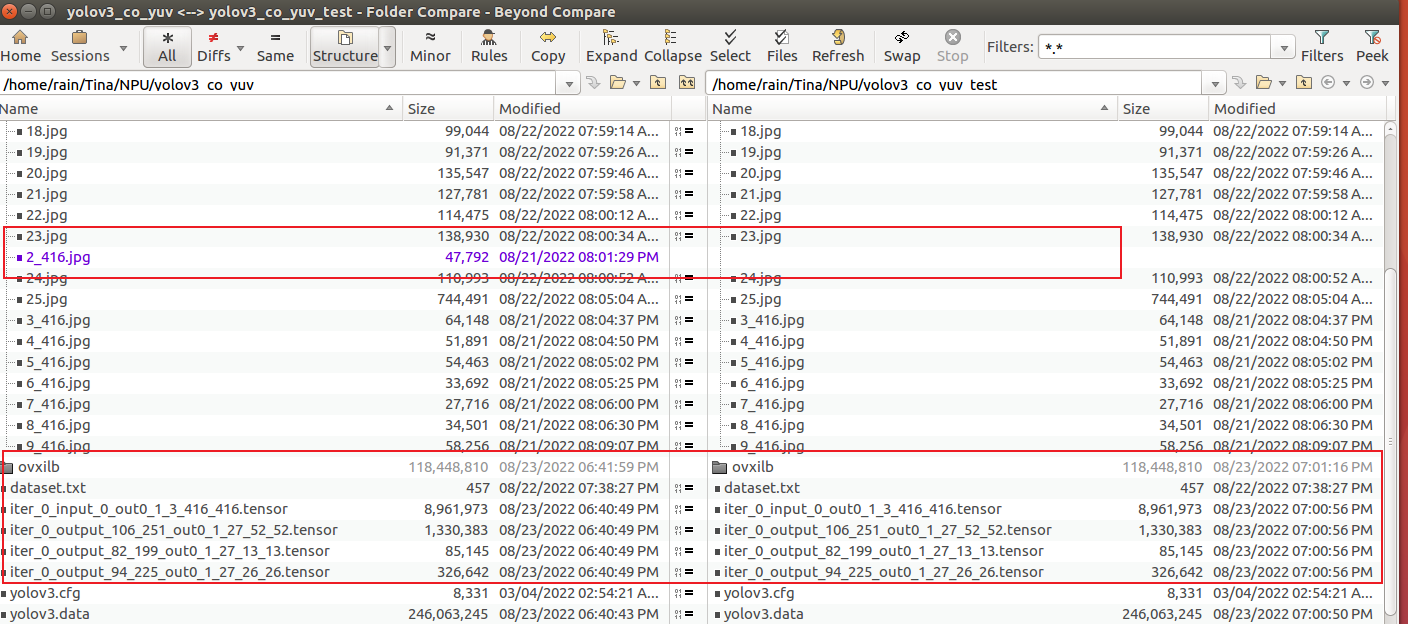
在2个文件夹文件内容完全一样的基础上,第二个文件夹将 2_416.jpg 图片删掉,dataset.txt 不修改 依然包含此图片。
 :
:
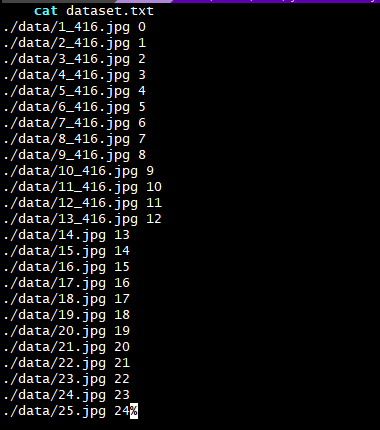
在同样步骤转换后,对比两个文件夹内容发现:少了一张图片的文件夹模型转换过程中 没有报错,此外输入输出Tensor 一模一样,以及 ovxilb/yolov3_nbg_unify/network_binary.nb 都一样。
验证2如下:
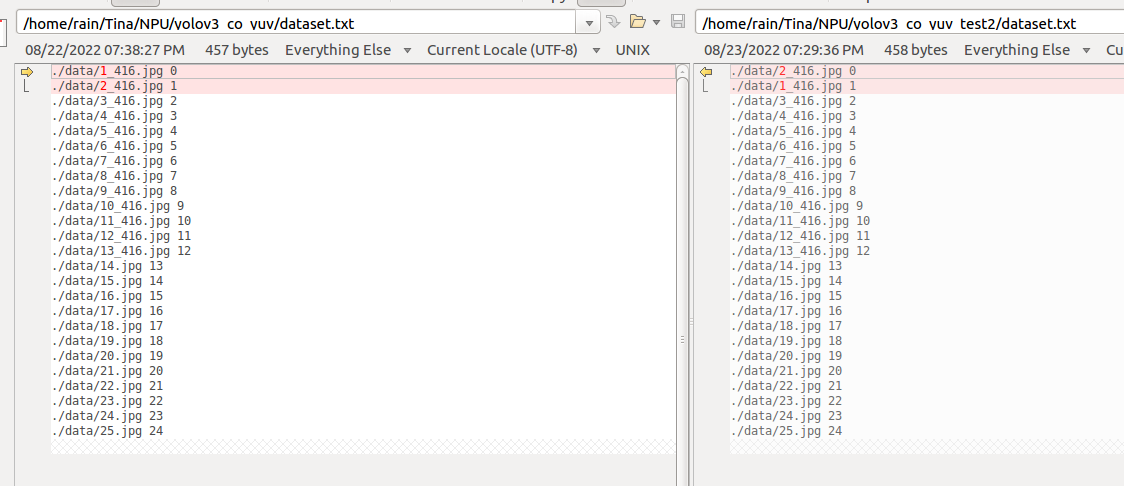
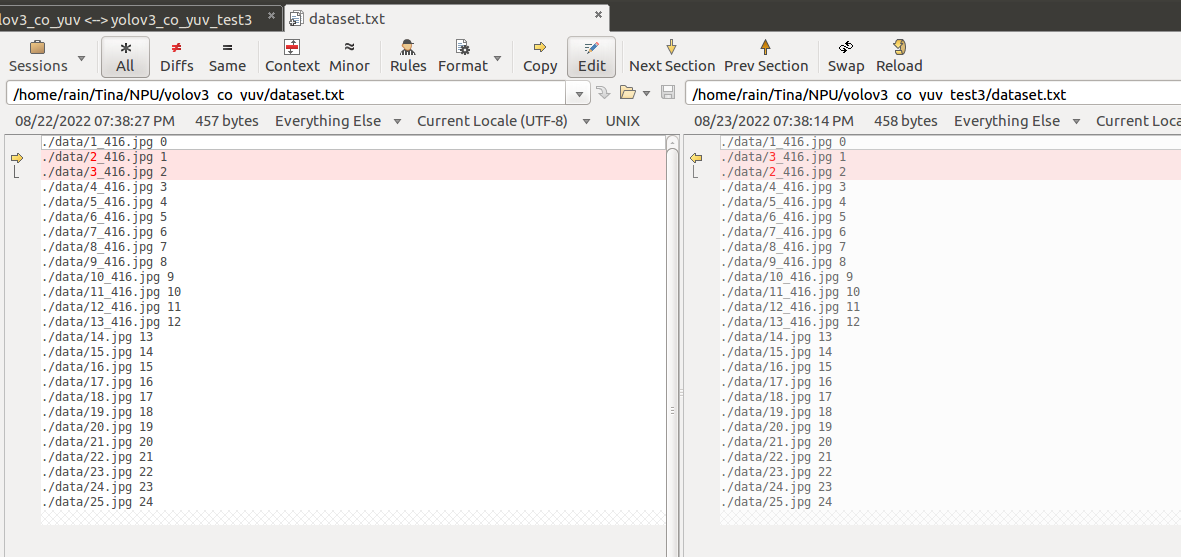
在3个文件夹文件内容完全一样的基础上,修改 ②号文件夹 dataset.txt 将第二行与第一行交换, 修改 ③号文件夹 将第三行与第二行交换。
① ②对比
① ③ 对比
转换后:
① ②对比
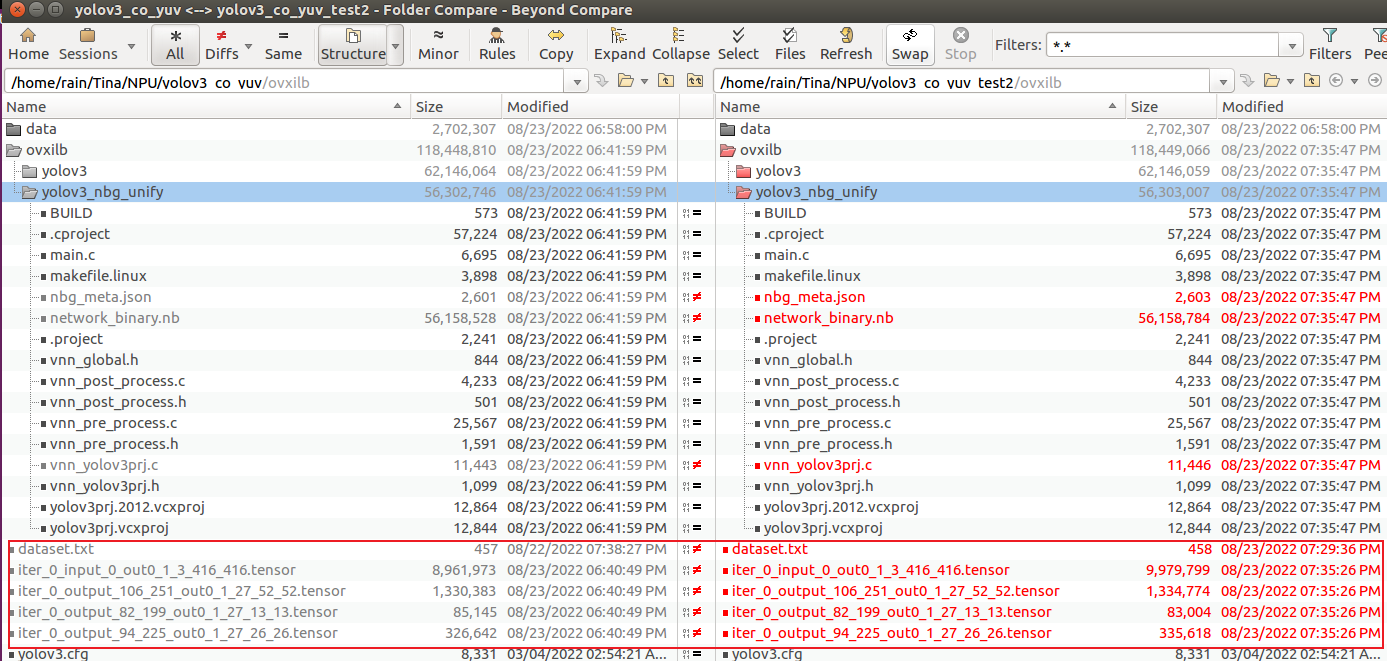
① ③ 对比
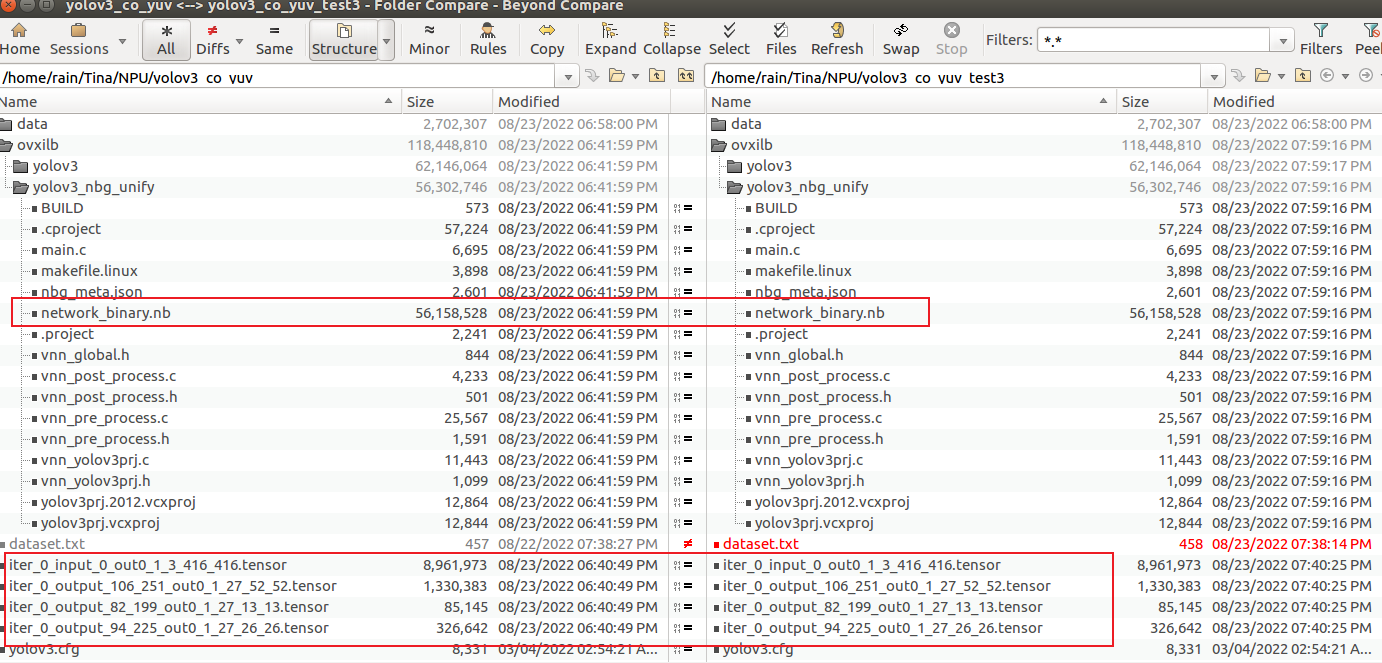
这里发现,①② tensor 以及 nbg 有明显差异,①③tensor 以及 nbg 相同,故怀疑量化时 只使用了第一张图片。这是为什么呢?
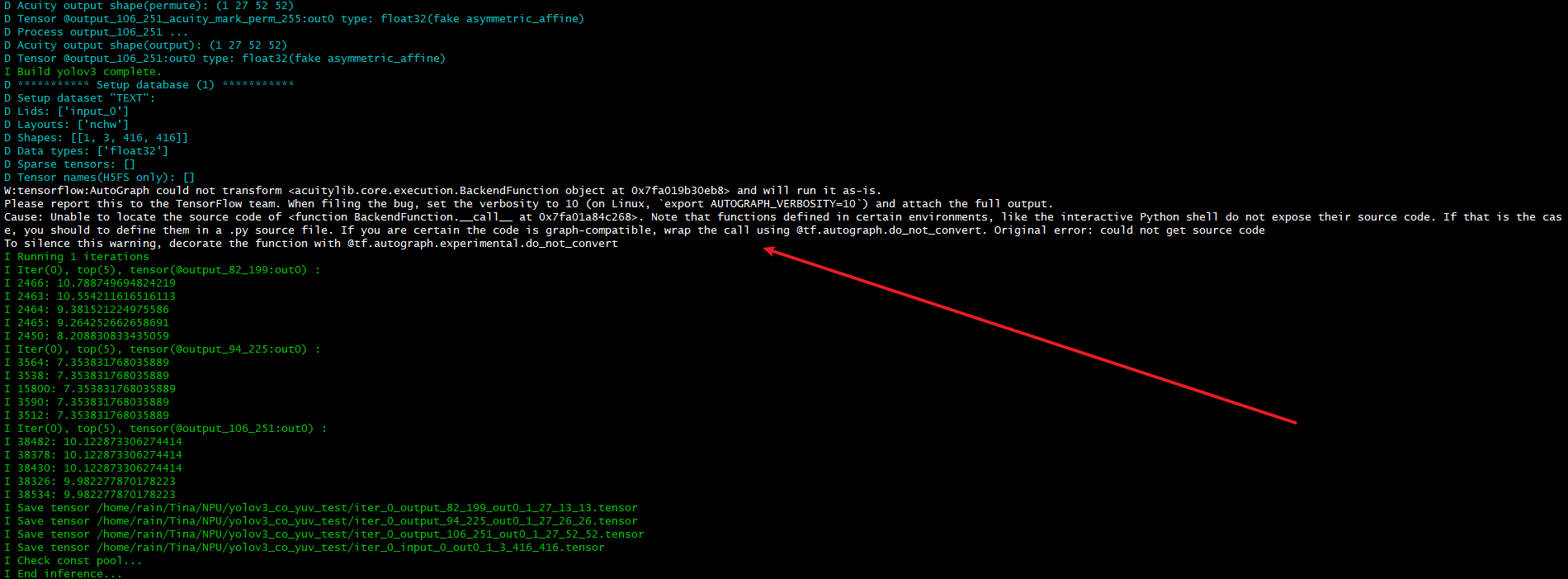
2.转化模型时候,中间在 量化 /预推理 有这个输出log,是否有影响或有问题?
3. 使用sample_odet_demo 使用自己训练转化的yolov3模型,图像实时显示标框有点卡顿现象,该怎么调高时钟让其顺畅?
-
补充下转换过程:
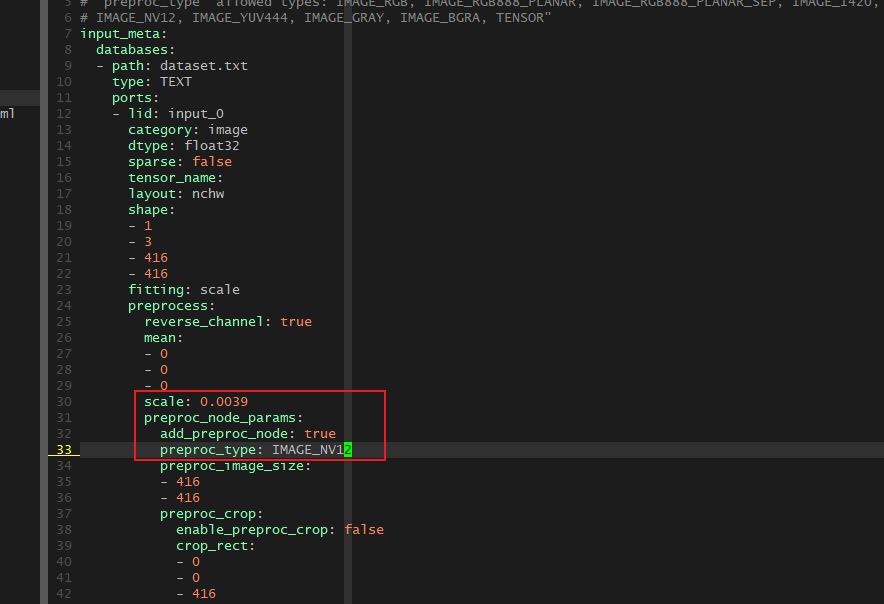
export VSI_USE_IMAGE_PROCESS=1 pegasus import darknet --model yolov3.cfg --weights yolov3.weights --output-model yolov3.json --output-data yolov3.data pegasus generate inputmeta --model yolov3.json --input-meta-output yolov3_inputmeta.yml pegasus generate postprocess-file --model yolov3.json --postprocess-file-output yolov3_postprocessmeta.yml修改 inputmeta
pegasus quantize --model yolov3.json --model-data yolov3.data --batch-size 1 --device CPU --with-input-meta yolov3_inputmeta.yml --rebuild --model-quantize yolov3.quantize --quantizer asymmetric_affine --qtype uint8 pegasus inference --model yolov3.json --model-data yolov3.data --batch-size 1 --dtype quantized --model-quantize yolov3.quantize --device CPU --with-input-meta yolov3_inputmeta.yml --postprocess-file yolov3_postprocessmeta.yml pegasus export ovxlib --model yolov3.json --model-data yolov3.data --dtype quantized --model-quantize yolov3.quantize --batch-size 1 --save-fused-graph --target-ide-project 'linux64' --with-input-meta yolov3_inputmeta.yml --output-path ovxilb/yolov3/yolov3prj --pack-nbg-unify --postprocess-file yolov3_postprocessmeta.yml --optimize "VIP9000PICO_PID0XEE" --viv-sdk ${VIV_SDK} -
- 量化不仅是对参数量化,也会对输入输出的数据量化。模型没有输入数据,就不知道输入输出的数据范围。 不一定要把所有训练数据全部加入量化。太多了,量化就太慢了。通常我们选择几百张能够代表所 有场景的输入数据就可以了。量化数据放入多一些,量化后精度可能会好一些。nbg 包含权重以及 量化信息,板子上面运行 NBG 文件时,只需要准备输入数据。不需要量化文件。 量化过程中的--batch-size 表示一次处理的数据的个数,对 YOLOV3 来说,这个数据就是 dataset.txt 中指定的图片,当 --batch-size 和--iterations 联合起来一起用,表示以--batch-size 个为单位处理单位的数据,处理 --iterations 次,并且是按照 dataset.txt 文件列表循环处理的。简言之,batch size 就是 NCHW 中的 N.
- 这个log表示此时使用的是CPU而不是GPU,是Tensorflow这个库的一个警告,无视即可
- 实际测试过,将NPU主频提高400MHz并没有明显的提升,说明提高NPU主频并没有什么意义。卡顿可以通过减少数据量,优化视频通路来解决。例如使用320分辨率的图片
-
@yteraa 感谢大佬,明白了。
-
您好,想再请教下。
量化与预推理时候 将 --batch-size 1 修改为 --batch-size 25 --iterations 2 ,修改后发现生成的 tensor 的确有变化。
pegasus quantize --model yolov3.json --model-data yolov3.data --batch-size 25 --iterations 2 --device CPU --with-input-meta yolov3_inputmeta.yml --rebuild --model-quantize yolov3.quantize --quantizer asymmetric_affine --qtype uint8 pegasus inference --model yolov3.json --model-data yolov3.data --batch-size 25 --iterations 2 --dtype quantized --model-quantize yolov3.quantize --device CPU --with-input-meta yolov3_inputmeta.yml --postprocess-file yolov3_postprocessmeta.yml
而在导出模型这步却识别不了 iterations 参数,这步难道不需要修改吗?pegasus export ovxlib --model yolov3.json --model-data yolov3.data --dtype quantized --model-quantize yolov3.quantize --batch-size 25 --iterations 2 --save-fused-graph --target-ide-project 'linux64' --with-input-meta yolov3_inputmeta.yml --output-path ovxilb/yolov3/yolov3prj --pack-nbg-unify --postprocess-file yolov3_postprocessmeta.yml --optimize "VIP9000PICO_PID0XEE" --viv-sdk ${VIV_SDK} -
@rain_tk 是的,量化和预推理需要
-
@rain_tk 在 全志V853 NPU yolov3转化模型时量化未使用全部data图片 中说:
sample_odet_demo
你好,sample_odet_demo的原代码运行需要做什么修改吗?如果需要修改,可以将你修改该过的代码发一下吗?
Copyright © 2024 深圳全志在线有限公司 粤ICP备2021084185号 粤公网安备44030502007680号