飞凌OK-T527开发板试用2-简单的性能测试
-
本文主要使用CoreMark、Dhrystone和Stream对芯片性能进行初步检测,并与ELFBorad进行了简单的单核性能比较。
OK527N-C
CoreMark
获取CoreMark源码
首先,从EEMBC官网下载CoreMark的源代码压缩包,或者使用Git克隆仓库:
git clone https://github.com/eembc/coremark.git cd coremark修改Makefile
首先复制文件夹
cp -rf posix ok527之后修改ok527文件夹下的core_portme.mak文件,将CC修改如下
CC = aarch64-none-linux-gnu-gcc交叉编译
make PORT_DIR=ok527编译结束后会报错,但是已经生成了交叉编译的coremark.exe可执行程序。这是由于架构不同,该交叉编译的程序并不能在电脑上直接运行。
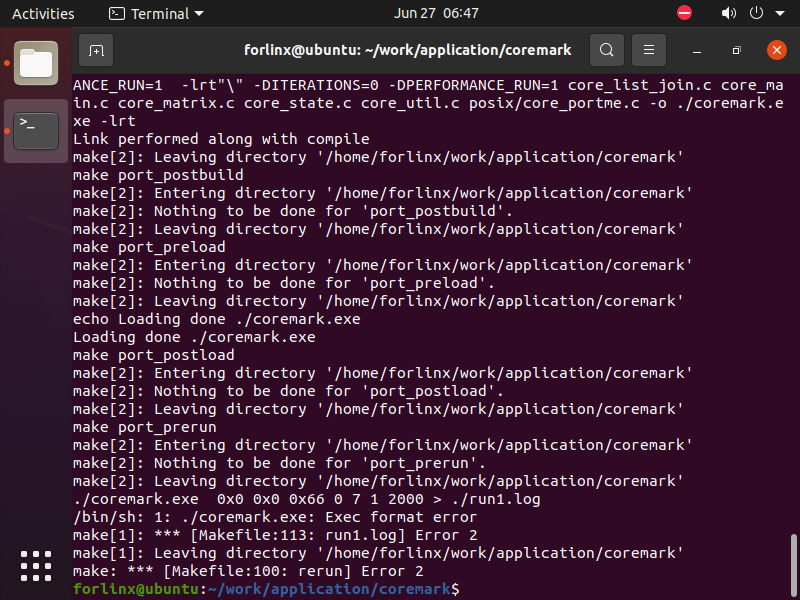
将文件夹下的coremark.exe复制到板卡上,执行chmod 777 coremark.exe ./coremark.exe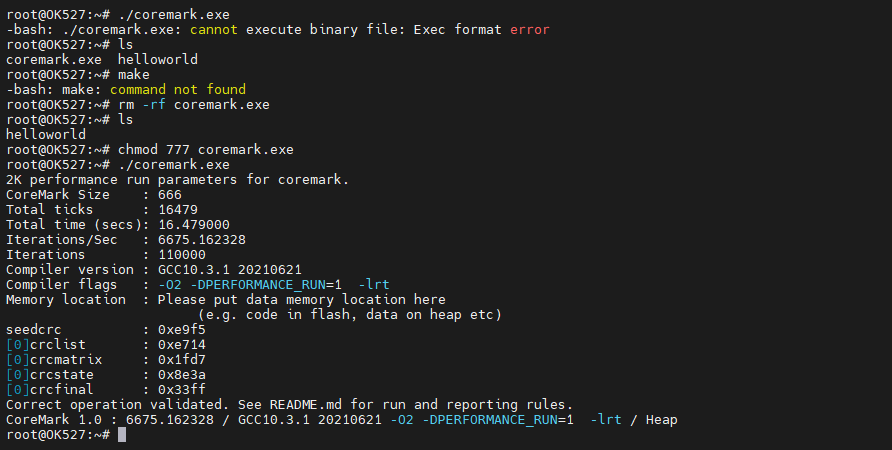
多核
make PORT_DIR=ok527 XCFLAGS="-DMULTITHREAD=4 -DUSE_FORK -pthread"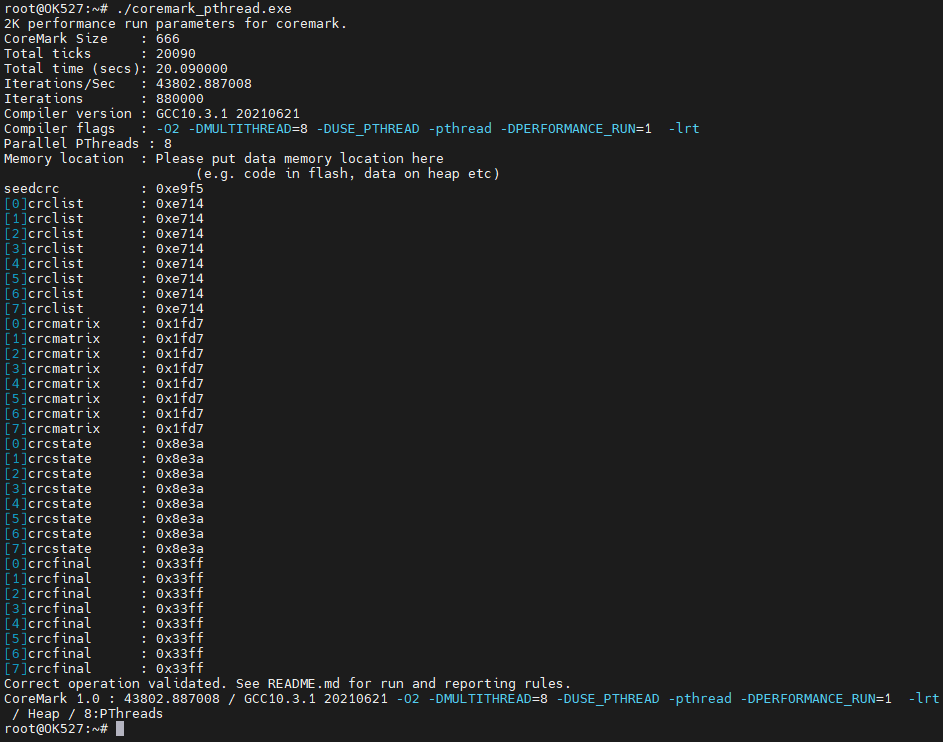
Dhrystone(单核性能测试工具)
首先下载源码(http://www.roylongbottom.org.uk/classic_benchmarks.tar.gz)并解压
tar -vxf classic_benchmarks.tar.gz之后新建一个编译文件夹,复制相关源码到此,并新建Makefile文件
cd classic_benchmarks mkdir ./build cd ./build cp -rf ../source_code/common_64bit/cpuidc64.c ./ cp -rf ../source_code/common_64bit/cpuidh.h ./ cp -rf ../source_code/dhrystone2/dhry.h ./ cp -rf ../source_code/dhrystone2/dhry_1.c ./ cp -rf ../source_code/dhrystone2/dhry_2.c ./ touch Makefile将如下内容复制到Makefile文件中并保存
CC=aarch64-none-linux-gnu-gcc main:*.o ${CC} -o dhry2_64 *.o ${CC} -O2 -o dhry22_64 *.o ${CC} -O3 -o dhry23_64 *.o *.o:*.c ${CC} -g -c *.c clean: rm -f *.o dhry2_64 dhry22_64 dhry23_64此外由于source_code/common_64bit/cpuida64.asm代码并不适配aarch64-none-linux-gnu-as汇编器,所以我们在复制的时候没有复制此文件,并且需要注释掉 cpuidc64.c中的_cpuida() 、_calculateMHz() 两个汇编函数。
最后执行编译make clean make
生成的三个可执行文件分别为dhry2_64(无优化等级)、dhry22_64(优化等级2)、dhry23_64(优化等级3)。这里我们将dhry2_64复制到板卡中并运行,得到的结果如下
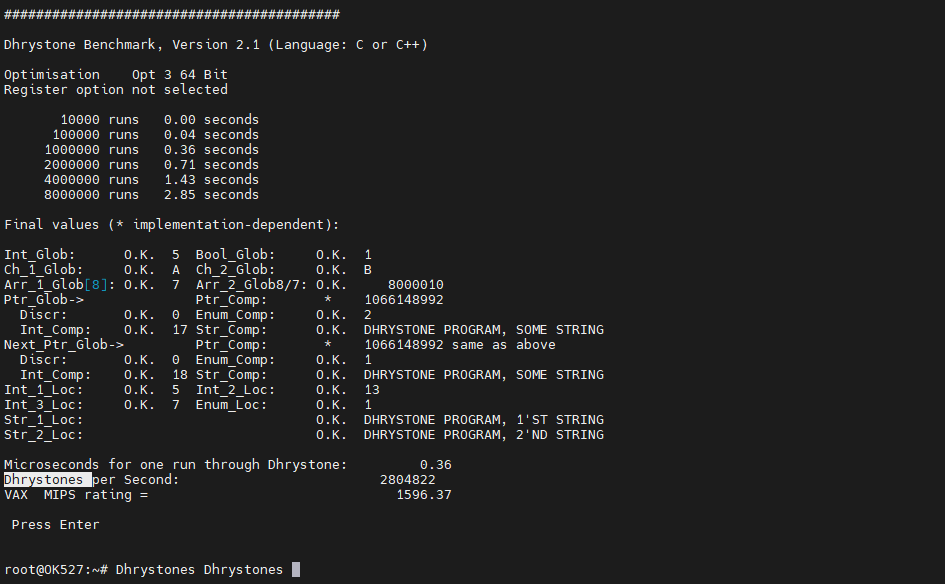
Stream
STREAM是一种内存带宽测试工具,主要用于评估计算机系统的内存子系统性能,特别是其读写速度和带宽。它通过一系列简单但计算密集型的操作来模拟对连续内存区域的访问,以此来测量系统的实际内存带宽性能。
STREAM测试主要提供以下四种指标:- Copy (复制):测量一个数组中的数据复制到另一个数组的速度。这项测试代表了简单的数据移动操作,如内存拷贝。
- Scale (尺度变换):测量将数组中的每个元素乘以一个常数的速度。这代表了需要读取、修改并重新写回内存的数据操作。
- Add (矢量求和):测量将两个数组的相应元素相加,并将结果存储到第三个数组中的速度。这代表了常见的向量加法操作。
- Triad (复合矢量求和):测量将一个数组的元素与另一个数组的元素相加,然后将结果乘以一个常数,并存储到第三个数组中的速度。这是最复杂的一项测试,因为它涉及读取、计算和写回三个数组的操作。
首先下载C源码(https://www.cs.virginia.edu/stream/FTP/Code/stream.c),并在同一目录下新建makefile,并将以下内容复制进去
CC=aarch64-none-linux-gnu-gcc main: ${CC} stream.c -o stream clean: rm -f *.o stream编译执行后得到可执行文件stream,将其复制到板卡上并执行

此外,在编译程序时还可以启用-fopenmp选项,它会告诉编译器生成能利用多线程的代码,从而可以并行地执行内存读取和写入操作,从而更好地模拟真实应用的负载情况,因为现代应用程序往往利用了多核架构的并行处理能力。因此,启用-fopenmp可以得到更接近实际工作负载下的内存带宽测量值。启用-fopenmp选项后的测试结果如下:
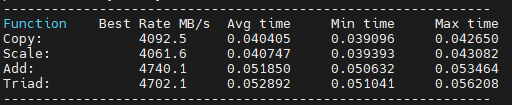
可以看到板卡的内存性能也很不错。
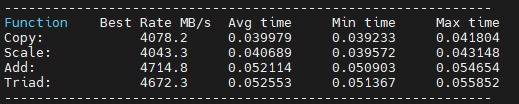
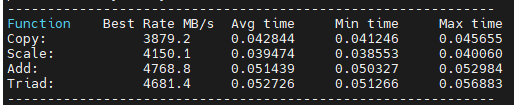
之后我们修改Makefile来查看不同编译优化等级的影响,CC=aarch64-none-linux-gnu-gcc main: ${CC} stream.c -fopenmp -o stream ${CC} stream.c -fopenmp -O1 -o stream1 ${CC} stream.c -fopenmp -O2 -o stream2 ${CC} stream.c -fopenmp -O3 -o stream3 clean: rm -f *.o stream交叉编译后分别得到无优化、优化等级1、优化等级2、优化等级3的程序,将其下载到板卡中进行测试。
- 无优化
- 优化等级1

- 优化等级2
- 优化等级3
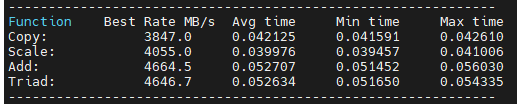
可以看到当为优化等级1时效果最好,O2和O3都会导致部分指标有一定的衰减。
ELFBoard
下面以搭载i.MX6ULL芯片的ELFBoard为例进行单核性能比对测试。
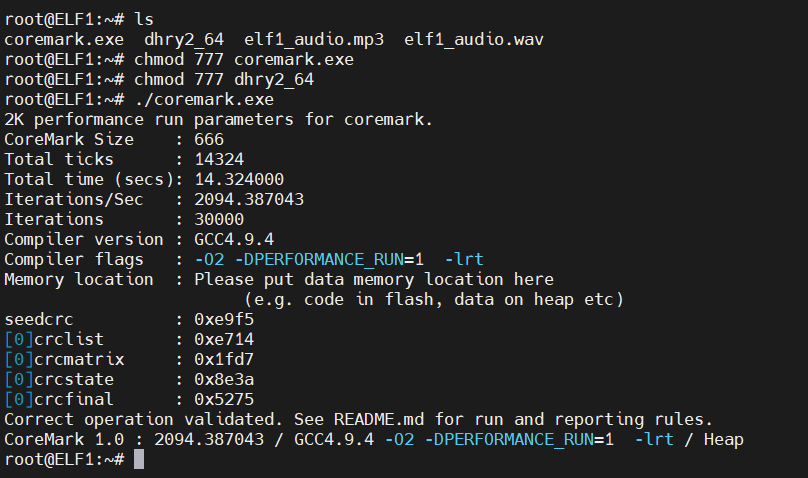
coremark
Dhrystone
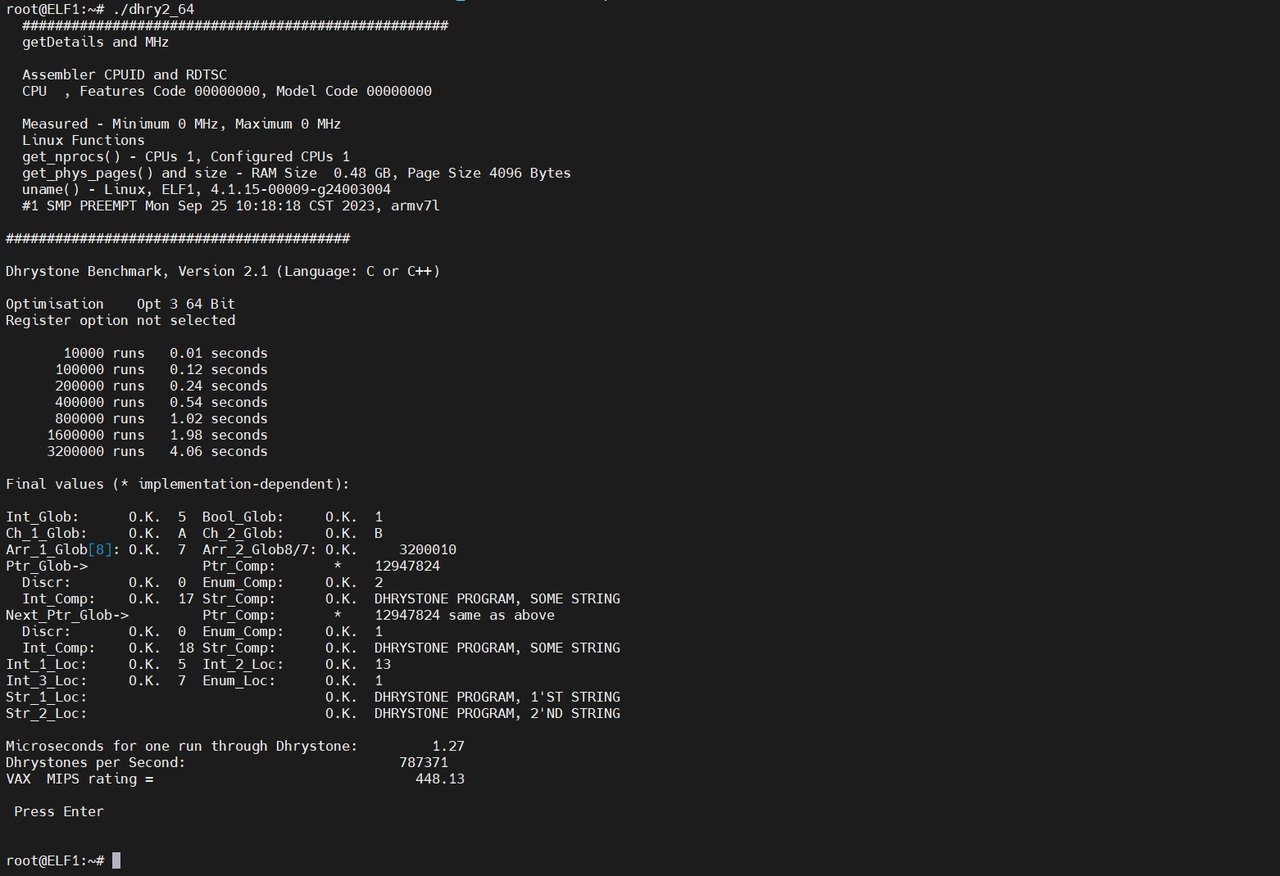
可以看到在单核性能上T527N就比i.MX6ULL大约高了三倍。
Copyright © 2024 深圳全志在线有限公司 粤ICP备2021084185号 粤公网安备44030502007680号