【R329-NPU助力】Maix-Speech为嵌入式环境设计的离线语音库
-
Maix-Speech是专为嵌入式环境设计的离线语音库,设计目标包括:ASR/TTS/CHAT
作者的设计初衷是完成一个低至Cortex-A7 1.0GHz 单核下可以实时运行的ASR库。
目前市面上的离线语音库非常稀缺,即使有也对主控要求很高,Maix-Speech 针对语音识别算法进行了深度优化,在内存占用上达到了数量级上的领先,并且保持了优良的WER。
基本情况
Maix-Speech刚发布了一个面向嵌入式设备的离线语音识别库,可以在低至Coretx-A7 1.0GHz, 64MB系统内存的嵌入式设备上实时运行(RTF<1.0)
最低内存占用25MB,磁盘占用35MB(含语言模型);最优aishell wer约5.4%;支持流式识别,支持连续数字识别,关键词识别,连续大词表语音识别等
支持:x86_64, armv7, aarch64, riscv64 等多种硬件平台,支持 AWNN, Zhouyi AIPU 加速。
感兴趣的可以跳转githuib来点个赞。
链接:https://github.com/sipeed/Maix-Speech
Maix-Speech 的优势
- 列表多平台支持
Maix-Speech 支持多种嵌入式平台
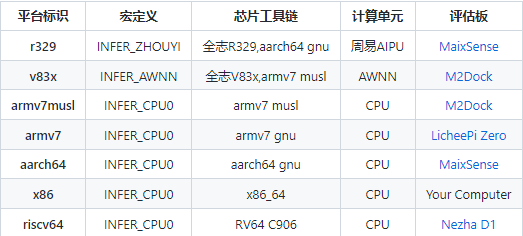
- 列表极低的内存要求和优良的正确率
Maix-Speech的内存占用相对于市面上的其他语音识别框架有数量级上的领先优势,并且保持良好的WER水平。
Maix-Speech最低可以实时运行(RTF<1)于典型的 1.0GHz Cortex-A7 内核的芯片上,并且最低仅占用25MB左右内存, 也就意味着它可以实时运行在典型的内封64MB内存的A7芯片上。
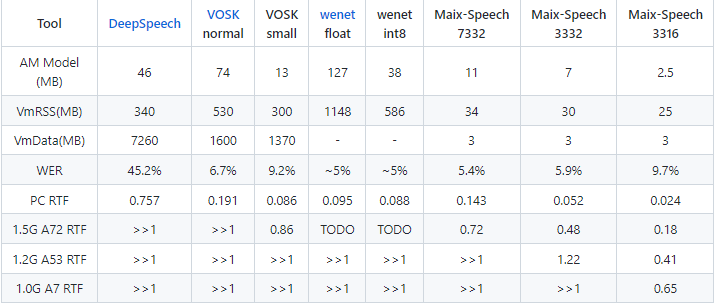
常见离线语音识别工具对比- 细节优化
优化了openfst及wfst解码,使得整个解码图无需载入内存即可实时读取解码。
可选载入内存的LG.fst解码图,压缩为lg.sfst, 尺寸为原始fst的1/3左右,占用内存为kaldi载入相同fst的内存占用的 1/20左右(kaldi需要6.5倍左右内存载入fst文件)。
使用新的sMBR等效的方式(无需修改loss)进行鉴别性训练,提升流式识别的准确率。
- 效果展示
在全志 R329 上的运行效果,视频中板卡为 MaixSense
连续大词汇量语音识别(LVCSR)
连续中文数字识别 (DIGIT)
关键词识别(KWS)
Maix-Speech 工程结构
[├── assets │ └── test_files # 提供的测试文件,方便上手测试 ├── components # 组件 │ ├── asr_lib # 组件 asr_lib │ │ ├── CMakeLists.txt # 组件配置文件 │ │ ├── include # 头文件 │ │ ├── Kconfig # 组件 menuconfig 配置文件 │ │ ├── lib # 各个平台的库文件 │ │ └── src # 源文件 │ └── utils # 工具类组件,包括了跑分、字体等 ├── Kconfig # 最顶级的 menuconfig 配置文件 ├── LICENSE # 开源协议(证书) ├── projects # 工程 │ └── maix_asr # ASR 工程 │ ├── CMakeLists.txt # 工程配置文件 │ ├── main # 工程里面的主组件 │ └── project.py # 构建脚本,方便输入命令 ├── README.md # 项目首页英文文档 ├── README_ZH.md # 项目首页中文文档 ├── tools # 项目构建相关代码,一般不用看 └── usage_zh.md # 使用方法]构建代码
项目支持多平台, 不同的平台使用的工具链和库可能有差异,注意区别。
PC环境的推荐系统为 Ubuntu 18.04 以上,gcc 7.5 以上,CMake 3.20以上,失能conda虚拟环境。其他环境可能有部分软件需要额外设置,不建议新手使用。
其他嵌入式环境的交叉编译方式可能存在一些细节使用问题,商业用户可以联系support@sipeed.com 获取支持。
- 环境准备
首先电脑安装工具链和库(Ubuntu 为例)
sudo apt update sudo apt install git python3 cmakepython 只是用在编译脚本上的,方便简单地输入编译命令, 如果你电脑里有任何一个版本的 python 都是可以的, 为确保不出问题最好是Python3。如果实在不想装 python , 也可以手动使用 cmake 命令进行编译。
x86 (Linux) 或 在跑在其它架构的系统里编译,比如在R329或树莓派的系统里使用GCC编译 安装工具链和库(Ubuntu为例)。
sudo apt install build-essential libasound2-dev交叉编译 下载工具链,并解压到指定文件夹 比如R329, 从 realease 下载 r329_toolchain.tar.gz, 并解压到一个路径,比如 /opt/r329_toolchain 比如 v83x, 在这里找到工具链下载链接并下载工具链,解压到一个文件夹,比如/opt/toolchain-sunxi-musl
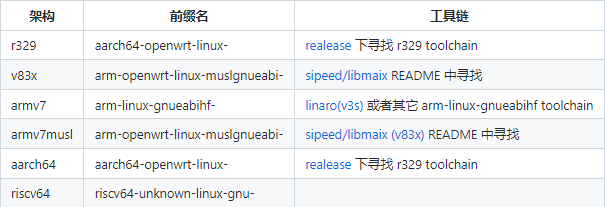
克隆代码
git clone https://github.com/sipeed/Maix-Speech- 编译
x86(Linux)或在跑在其它架构的系统里编译,比如在R329或 树莓派 的系统里使用GCC编译
注意,conda 环境下工具链可能有问题,如果出现错误可以先尝试 退出conda环境使用原生环境编译。
cd projects/maix_asr python project.py clean_conf # 清除工具链配置 python project.py menuconfig # 配置选择芯片架构(ARCH),默认是 x86 python project.py build#python project.py rebuild # 如果有新建文件需要使用 rebuild # python project.py build --verbose # 打印详细构建过程 ./build/maix_asr # 测试下运行可执行文件,可以执行即可 python project.py clean # 清除构建内容 python project.py distclean # 彻底清除构建内容, 包括 menuconfig 内容- 其它架构(交叉编译)
交叉编译需要工具链, 前面的准备工作中已经下载了工具链,在编译时需要配置工具链信息到工程里面
需要配置:
工具链可执行文件所在文件夹路径,比如
/opt/r329_toolchain/bin
/opt/toolchain-sunxi-musl/bin
工具链前缀,可在前面的表格中找到, 比如aarch64-openwrt-linux-
cd projects/maix_asr # 配置工具链位置和前缀, distclean 不会清除工具链配置, 这会在目录下生成一个 .config.mk 文件 python project.py --toolchain 工具链可执行文件路径路径 --toolchain-prefix 前缀名 config # python project.py --toolchain /opt/r329_toolchain/bin --toolchain-prefix aarch64-openwrt-linux- config python project.py menuconfig # 选择 架构 python project.py build # python project.py clean_conf # 清除工具链配置运行语音识别例程
以x86(Linux)平台为例的快速验证 demo, 其它平台特别是交叉编译的平台需要自行拷贝可执行文件到开发板的系统里面再运行:
先保证编译通过, 可执行文件 projects/maix_asr/build/maix_asr 存在并且可以运行
在release页面找到 am_7332.ziplmM.zip 文件并下载, 解压到assets/test_files 目录, 解压后assets目录结构如下
assets ├── image └── test_files ├── 1.2.wav ├── am_7332 ├── asr_wav.cfg └── lmM主要包含了两种模型 声学模型AM 和 语言模型LM, 每种模型又有几种模型大小选择,越大精度越高资源消耗越大, 另外还有字体文件
不同平台实时运行的典型配置
Cortex-A7 1.0GHz, <=128M 系统内存:am_3316 + lmS, is_mmap=1, beam<5 Cortex-A7 1.0GHz, >=256M 系统内存:am_3316 + lmM, is_mmap=0, beam=5~10 Cortex-A53 1.2GHz, >=256M 系统内存:am_3324 + lmM, is_mmap=0, beam=5~10 Cortex-A72 1.5GHz, >=1G 系统内存:am_3332 + lmL, is_mmap=0, beam=5~10带NPU的硬件平台,选用对应转换好的 NPU 硬件加速的声学模型,比如R329下载r329_7332_192.bin, 然后根据系统内存选择对应的语言模型,语言模型目前没有硬件加速,均使用 CPU 运算
进入到 test_files 目录
cd assets/test_files执行测试
../../projects/maix_asr/build/maix_asr asr_wav.cfg可以看到语音识别的结果
HANS: 一点 二三 四五 六七 八九 PNYS: yi4 dian3 er4 san1 si4 wu3 liu4 qi1 ba1 jiu3如果是 Windows 需要 GBK编码则修改asr_wav.cfg中的
words_txt:lmM/words_utf.bin为
words_txt:lmM/words.bin测试其他 wav 文件只需要修改 asr_wav.cfg 中的 device_name 到对应测试 wav 路径即可,测试其它模型,修改model_name指定文件路径即可。
注意 wav 需要是 16KHz 采样,S16_LE 存储格式。另外还支持 PCM 或者 MIC 实时识别,详见 usage_zh.md 中对 cfg 文件的介绍。
可以使用工具转换,比如 arecord -d 5 -r 16000 -c 1 -f S16_LE audio.wav
Maix ASR 模型选择
MAIX ASR 声学模型按尺寸分为:7332,3332,3324,3316
大小如下表:
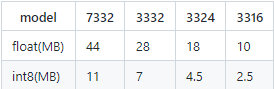
MAIX ASR 语言模型可以自由选择,默认开放三种尺寸的模型:lm_s,lm_m,lm_l
每种模型分成 sfst,sym,phones,words 四部分,其中 sym,phones,words 仅用于输出字符串使用,无需加载入内存,仅放在磁盘
sfst为解码图文件(LG.fst的压缩版),可选载入内存或者mmap实时读取。表中wer表示 aishell 测试集的汉字转拼音作为输入,通过LM转汉字后的错误率。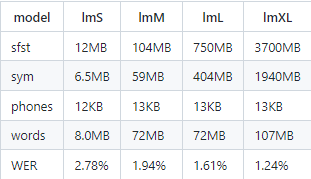
以下是各个模型的benchmark
pny wer表示带声调的拼音错误率,lmX表示加上对应语言模型后的汉字错误率。
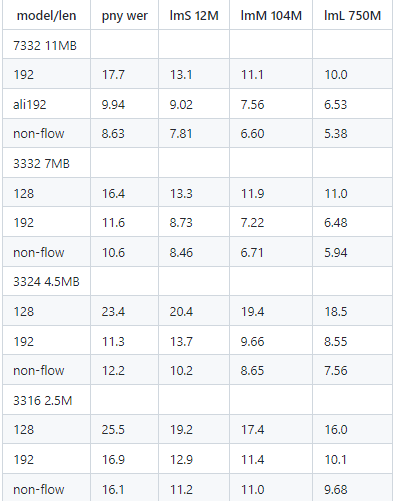
模型说明:
下划线后的数字表示选取的帧长度,如192表示一帧为192x8=768ms,asr库每采集完一帧后进行一次处理。
帧长度关系到识别延迟,如192就会最大有768ms延迟,128则为512ms,可见帧长的模型错误率更优,但是延迟稍长。
表中默认为流式识别,使用有限的上下文(一帧长度),noflow表示非流式识别(整体识别),可见非流式识别错误率大幅下降。
ali表示对齐优化后的结果,即类sMBR处理后的结果,可见对齐训练后错误率大幅下降。
附件默认上传了192长度的流式识别模型,需要其他识别模型的可以联系矽速。
-End-
微信直通车:
官网直通车:
Copyright © 2024 深圳全志在线有限公司 粤ICP备2021084185号 粤公网安备44030502007680号