@q1215200171 这个 SDK 和签了 NDA 在全志客户服务平台的 SDK 是一致的吗?
D
dream 发布的最佳帖子
-
【分析笔记】Linux I2C-Tools 使用踩坑笔记发布在 Linux
一、踩坑缘由
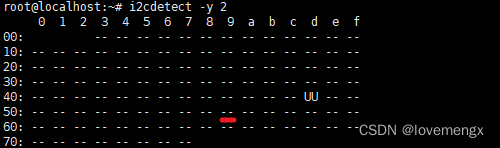
在调试 I2C 器件时,我一般习惯于使用 i2cdetect 工具来确认芯片是否有应答,通常有应答之后,就会开始着手移植或者编写对应的驱动程序,但是在调试 sgp41 传感器时却不灵了。
二、问题现象
在连续完成多个 I2C 器件的调试和驱动开发之后,最后一个 sgp41 传感器却一直无法被检测到。在使用示波器再次测量芯片供电、检查I2C波形、引脚顺序、电平匹配都正确后,认为是芯片坏了,换了多颗芯片,都无法识别,寄给供应商,供应商又说检测良好,这就很神奇了。
在同一个座子上,sht41 都能正常被检测到,但是 sgp41 却无法检测,更何况该总线上还挂了其它的 I2C 器件都能准确检测出来。
三、问题分析
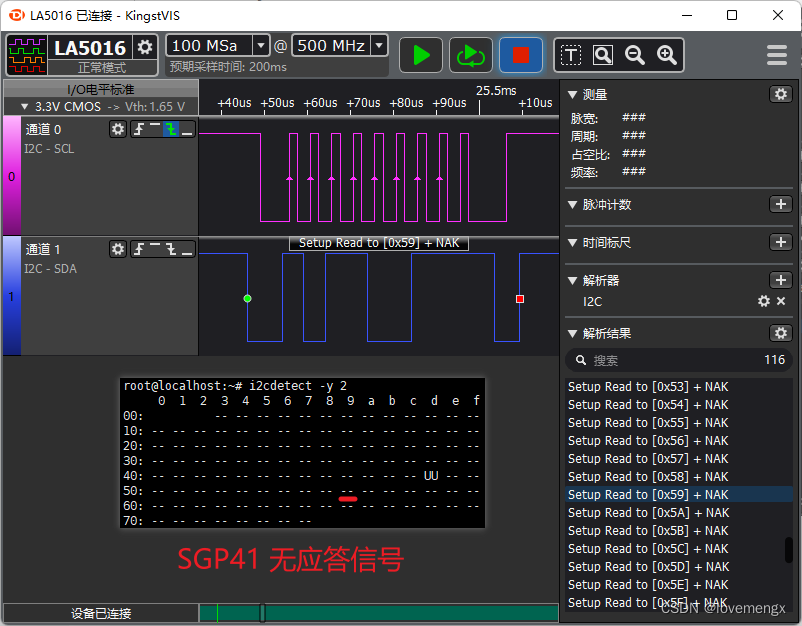
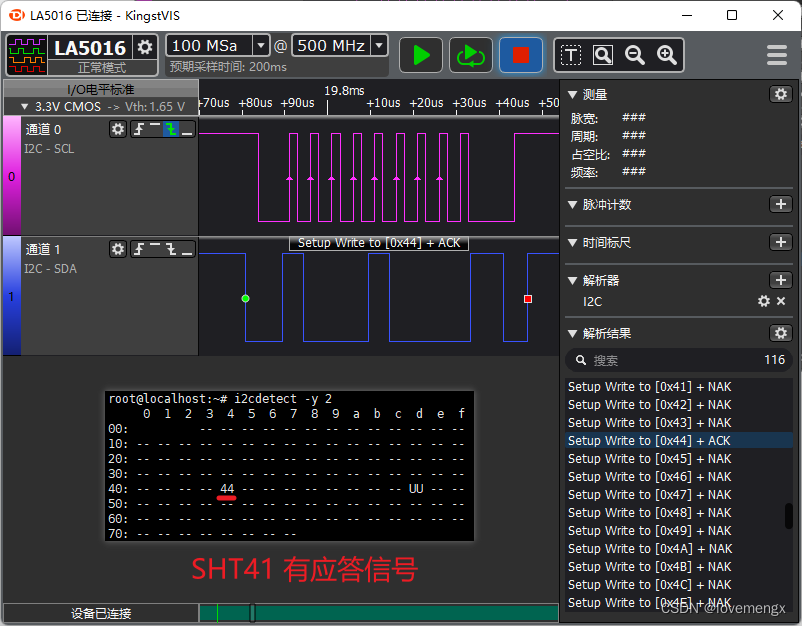
百思不得其解,在仔细观察逻辑分析仪解析的结果,发现在检测 0x44(sht41) 器件地址的时候,i2cdetect 使用的是采用写的方式检测,而检测 0x59(sgp41) 器件地址时,采用读的方式检测。
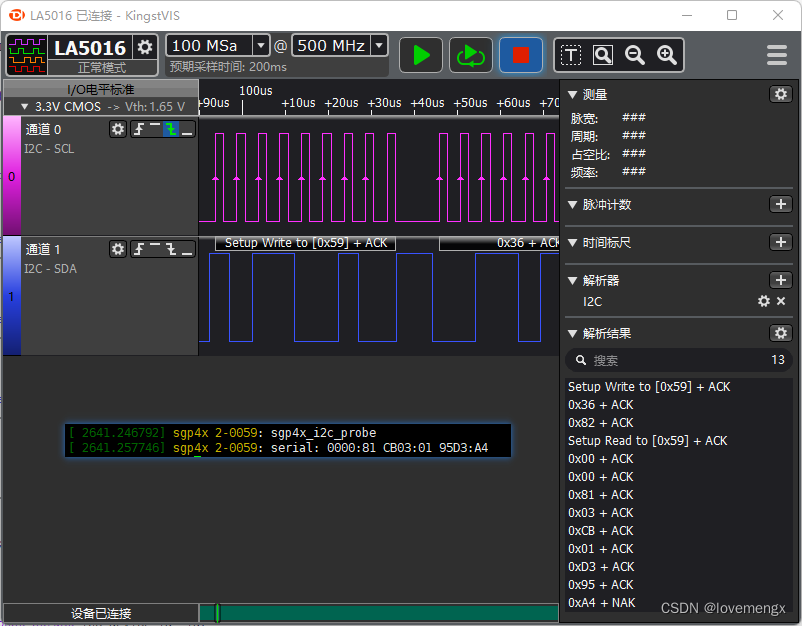
由于之前调试过 sht41 器件,知道这类传感器需要先写再读,才会有应答信号(规格书没有体现出来),因此推测跟这个有关。手写了一个 I2C 设备驱动,先写再读取,发现可以正常通信,证实了我的猜测。
四、深入分析
我特别好奇的是,为什么 i2cdetect 工具会对不同的地址段采用不同的方式进行检测,我分析了 i2cdetect.c 源代码,发现默认是以自动模式检测,而自动模式则会根据不同的地址段采取读或写来实现检测。
源码下载:http://mirrors.edge.kernel.org/pub/software/utils/i2c-tools/i2c-tools-4.0.tar.gz
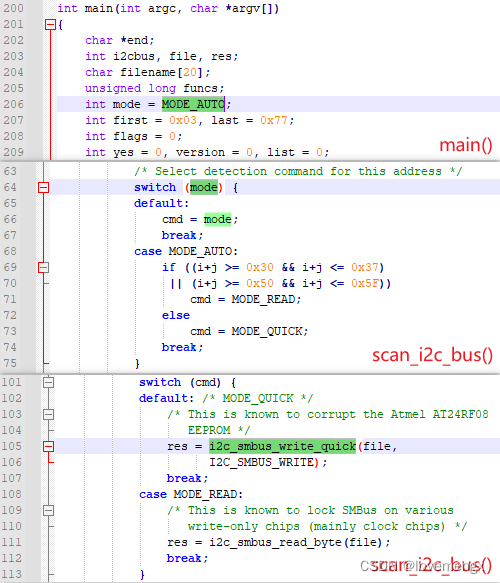
如果需要检测类似 sht41、sgp41 这种必须要先写再读才会有应答的芯片,就必须要指定检测模式为写检测(MODE_QUICK),由于 sht41 的器件地址 0x44 恰好在自动模式中以写的方式检测,因此可以检测得到。通过分析源码发现,-r 和 -q 即可指定读写模式:

下图为指定以写的方式检测 sgp41(0x59),可以发现有应答信号,被检测出来了:
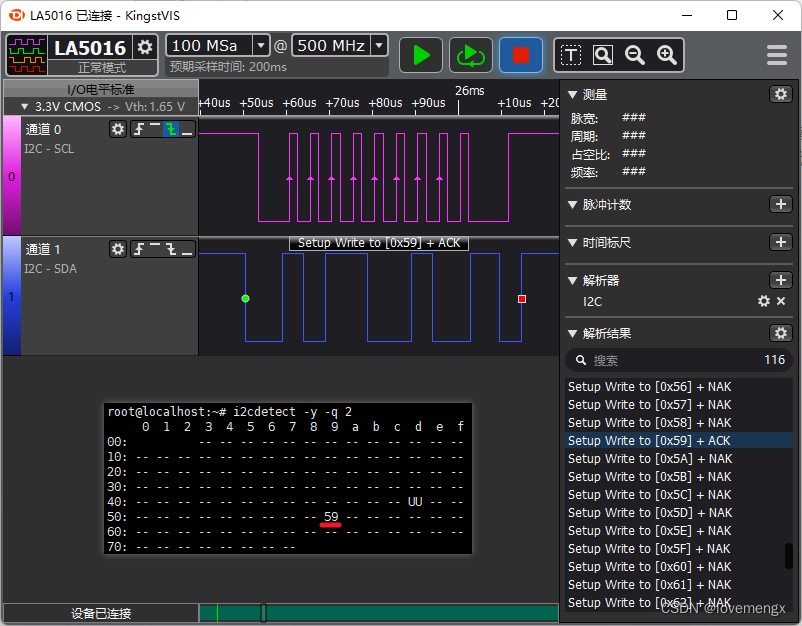
五、经验总结
- 不是所有的 I2C 器件都会直接响应读请求。
- 使用 i2cdetect 工具检测芯片,建议使用 -q 和 -r 参数都试试。
-
【分析笔记】全志 T507 PF4 引脚无法被正常设置为中断模式的问题分析发布在 其它全志芯片讨论区
相关信息
硬件平台:全志T507
系统版本:Android 10 / Linux 4.9.170
问题描述:PF4 无法通过标准接口设置为中断模式,而 PF1、PF2、PF3、PF5 正常可用。分析过程
一开始以为是引脚被其它驱动占用引起,或者该引脚不具备中断功能,经过排查,已排除这两种可能,因此通过从源码分析来找问题的根因。
以下是以 gpio_keys.c 驱动为入口进行分析:
// drivers/input/keyboard/gpio_keys.c static int gpio_keys_setup_key(struct platform_device *pdev, struct input_dev *input, struct gpio_button_data *bdata, const struct gpio_keys_button *button) { ...... error = devm_request_any_context_irq(&pdev->dev, bdata->irq, isr, irqflags, desc, bdata); } // kernel/irq/devres.c int devm_request_any_context_irq(struct device *dev, unsigned int irq, irq_handler_t handler, unsigned long irqflags, const char *devname, void *dev_id) { ...... rc = request_any_context_irq(irq, handler, irqflags, devname, dev_id); if (rc < 0) { devres_free(dr); return rc; } ...... return rc; } // kernel/irq/manage.c int request_any_context_irq(unsigned int irq, irq_handler_t handler, unsigned long flags, const char *name, void *dev_id) { ...... ret = request_irq(irq, handler, flags, name, dev_id); return !ret ? IRQC_IS_HARDIRQ : ret; } // include/linux/interrupt.h static inline int __must_check request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags, const char *name, void *dev) { return request_threaded_irq(irq, handler, NULL, flags, name, dev); } // kernel/irq/manage.c int request_threaded_irq(unsigned int irq, irq_handler_t handler, irq_handler_t thread_fn, unsigned long irqflags, const char *devname, void *dev_id) { ...... chip_bus_lock(desc); retval = __setup_irq(irq, desc, action); chip_bus_sync_unlock(desc); ...... return retval; } // kernel/irq/manage.c static int __setup_irq(unsigned int irq, struct irq_desc *desc, struct irqaction *new) { ...... if (!shared) { ret = irq_request_resources(desc); if (ret) { pr_err("Failed to request resources for %s (irq %d) on irqchip %s\n", new->name, irq, desc->irq_data.chip->name); goto out_mask; } ...... } ...... } // kernel/irq/manage.c static int irq_request_resources(struct irq_desc *desc) { struct irq_data *d = &desc->irq_data; struct irq_chip *c = d->chip; return c->irq_request_resources ? c->irq_request_resources(d) : 0; } // drivers/pinctrl/sunxi/pinctrl-sunxi.c static struct irq_chip sunxi_pinctrl_edge_irq_chip = { .name = "sunxi_pio_edge", .irq_ack = sunxi_pinctrl_irq_ack, .irq_mask = sunxi_pinctrl_irq_mask, .irq_unmask = sunxi_pinctrl_irq_unmask, .irq_request_resources = sunxi_pinctrl_irq_request_resources, .irq_release_resources = sunxi_pinctrl_irq_release_resources, .irq_set_type = sunxi_pinctrl_irq_set_type, .irq_set_wake = sunxi_pinctrl_irq_set_wake, }; // drivers/pinctrl/sunxi/pinctrl-sunxi.c static int sunxi_pinctrl_irq_request_resources(struct irq_data *d) { struct sunxi_pinctrl *pctl = irq_data_get_irq_chip_data(d); struct sunxi_desc_function *func; func = sunxi_pinctrl_desc_find_function_by_pin(pctl, pctl->irq_array[d->hwirq], "irq"); if (!func) return -EINVAL; /* Change muxing to INT mode */ printk(KERN_EMERG"[lmx] irq:%d set int mode pin:%d d->hwirq:%ld func->muxval:%d\n", d->irq, pctl->irq_array[d->hwirq], d->hwirq, func->muxval); sunxi_pmx_set(pctl->pctl_dev, pctl->irq_array[d->hwirq], func->muxval); return 0; } // drivers/pinctrl/sunxi/pinctrl-sunxi.c static void sunxi_pmx_set(struct pinctrl_dev *pctldev, unsigned pin, u8 config) { struct sunxi_pinctrl *pctl = pinctrl_dev_get_drvdata(pctldev); unsigned long flags; u32 val, mask; raw_spin_lock_irqsave(&pctl->lock, flags); pin -= pctl->desc->pin_base; val = readl(pctl->membase + sunxi_mux_reg(pin)); mask = MUX_PINS_MASK << sunxi_mux_offset(pin); writel((val & ~mask) | config << sunxi_mux_offset(pin), pctl->membase + sunxi_mux_reg(pin)); raw_spin_unlock_irqrestore(&pctl->lock, flags); }无论有多复杂的代码,最终都需要通过读写寄存器的方式来实现控制芯片,而通过上述代码分析,即可发现 sunxi_pmx_set() 接口用于配置寄存器,是最底层的接口,可以通过打印输出传入的参数,来检查是否有问题。
PF3 打印输出为:
[ 10.683205] [lmx] irq:148 set int mode pin:163 d->hwirq:131 func->muxval:6PF4 打印输出为:
[ 10.683557] [lmx] irq:149 set int mode pin:196 d->hwirq:132 func->muxval:6这里就能看出很奇怪的地方,PF3 的引脚编号是 163,而 PF4 却是 196,跨度很大。
通过以下指令查询 PF4 的正确引脚编号,也可以得知 196 引脚编号是哪一组:
mercury-demo:/ # cat /sys/kernel/debug/pinctrl/pio/pins registered pins: 137 ...... pin 160 (PF0) pin 161 (PF1) pin 162 (PF2) pin 163 (PF3) pin 164 (PF4) pin 165 (PF5) pin 166 (PF6) ...... pin 196 (PG4) pin 197 (PG5) ......确认 PF4 正确引脚编号是 164,而 196 对应是 PG4,实际生效的是 PG4,通过以下指令即可确认:
mercury-demo:/sys/kernel/debug/sunxi_pinctrl # echo PG4 > sunxi_pin mercury-demo:/sys/kernel/debug/sunxi_pinctrl # cat * pin[PG4] data: 1 pio pin[PG4] dlevel: 1 pin[PG4] funciton: 6 NOMATCH pin[PG4] pull: 1 PG4 pin[PG4] funciton: 6 pin[PG4] data: 1 pin[PG4] dlevel: 1 pin[PG4] pull: 1根据代码确定引脚编号来源于 pctl->irq_array 数组,通过 pctl->irq_array 赋值的地方进行打印输出,是否一开始就出错了:
// drivers/pinctrl/sunxi/pinctrl-sunxi.c static int sunxi_pinctrl_build_state(struct platform_device *pdev) { ...... /* Count functions associated groups */ for (i = 0; i < pctl->desc->npins; i++) { const struct sunxi_desc_pin *pin = pctl->desc->pins + i; struct sunxi_desc_function *func = pin->functions; while (func->name) { /* Create interrupt mapping while we're at it */ if (!strcmp(func->name, "irq")) { int irqnum = func->irqnum + func->irqbank * IRQ_PER_BANK; pctl->irq_array[irqnum] = pin->pin.number; printk(KERN_EMERG"[lmx] pctl->irq_array[%d] = %d (func->irqnum:%d func->irqbank:%d)\n", irqnum, pin->pin.number, func->irqnum, func->irqbank); } sunxi_pinctrl_add_function(pctl, func->name); func++; } } ...... return 0; } // drivers/pinctrl/sunxi/pinctrl-sunxi.h #define IRQ_PER_BANK 32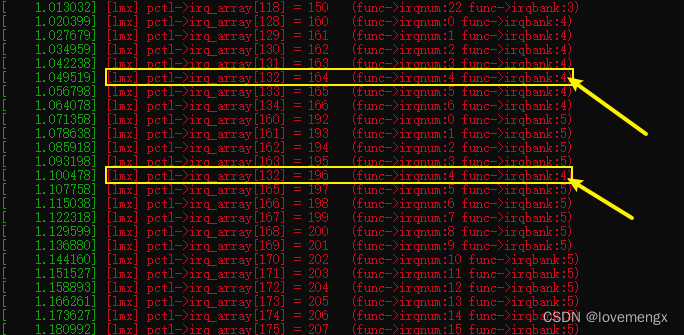
可以发现,PF4(164)对应的索引是 132,原本被正确赋值为 164,但又被覆盖为 PG4(196)。
不难发现,出现覆盖的原因是因为 PG4 的 func->irqbank 数值错误(4),导致索引下标计算错误。根据前后文来看,func->irqbank 的正确数值应该是 5,代入计算得到正确的值 164:
int irqnum(164) = func->irqnum(4) + func->irqbank(5) * IRQ_PER_BANK(32);大概率硬件资源描述配置出错,通过搜索 irqbank 被赋值的方法,来定位描述配置出错的地方:
// drivers/pinctrl/sunxi/pinctrl-sunxi.h #define SUNXI_FUNCTION_IRQ_BANK(_val, _bank, _irq) \ { \ .name = "irq", \ .muxval = _val, \ .irqbank = _bank, \ .irqnum = _irq, \ }使用的是 SUNXI_FUNCTION_IRQ_BANK 宏,重点检查第二个参数:
// drivers/pinctrl/sunxi/pinctrl-sun50iw9p1.c static const struct sunxi_desc_pin sun50iw9p1_pins[] = { ...... SUNXI_PIN(SUNXI_PINCTRL_PIN(G, 3), SUNXI_FUNCTION(0x0, "gpio_in"), SUNXI_FUNCTION(0x1, "gpio_out"), SUNXI_FUNCTION(0x2, "sdc1"), /* D1 */ SUNXI_FUNCTION_IRQ_BANK(0x6, 5, 3), /* PG_EINT3 */ SUNXI_FUNCTION(0x7, "io_disabled")), SUNXI_PIN(SUNXI_PINCTRL_PIN(G, 4), SUNXI_FUNCTION(0x0, "gpio_in"), SUNXI_FUNCTION(0x1, "gpio_out"), SUNXI_FUNCTION(0x2, "sdc1"), /* D2 */ // 可以发现第二个参数恰好是 4,根据分析结果,以及结合上下文,正确的应该是 5 SUNXI_FUNCTION_IRQ_BANK(0x6, 4, 4), /* PG_EINT4 */ SUNXI_FUNCTION(0x7, "io_disabled")), SUNXI_PIN(SUNXI_PINCTRL_PIN(G, 5), SUNXI_FUNCTION(0x0, "gpio_in"), SUNXI_FUNCTION(0x1, "gpio_out"), SUNXI_FUNCTION(0x2, "sdc1"), /* D3 */ SUNXI_FUNCTION_IRQ_BANK(0x6, 5, 5), /* PG_EINT5 */ SUNXI_FUNCTION(0x7, "io_disabled")), ...... };修改之后的 pctl->irq_array 打印输出正确:
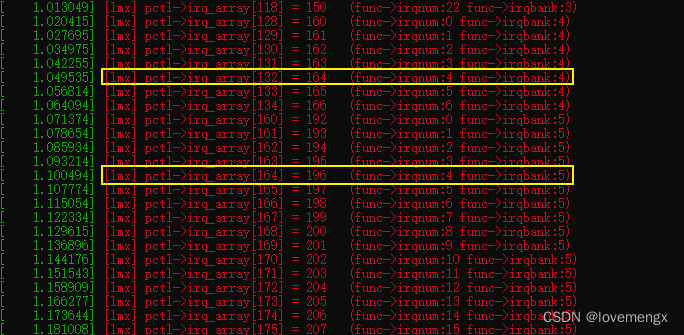
进行实测,PF4 已经可以正常的被设置为中断模式。
问题总结
全志原厂提供的 SoCs pinctrl driver 中的 PG4 中断信息描述错误,导致覆盖了 PF4 的引脚编号,因此只要修正 PG4 的描述信息,即可解决问题。
这个问题不仅仅会影响 PF4 无法使用,也会影响 PG4 引脚无法使用,从代码来看,想要设置为 PG4 为中断模式,实际修改的会 PA0(0)。
--- a/longan/kernel/linux-4.9/drivers/pinctrl/sunxi/pinctrl-sun50iw9p1.c +++ b/longan/kernel/linux-4.9/drivers/pinctrl/sunxi/pinctrl-sun50iw9p1.c @@ -693,7 +693,7 @@ SUNXI_FUNCTION(0x0, "gpio_in"), SUNXI_FUNCTION(0x1, "gpio_out"), SUNXI_FUNCTION(0x2, "sdc1"), /* D2 */ - SUNXI_FUNCTION_IRQ_BANK(0x6, 4, 4), /* PG_EINT4 */ + SUNXI_FUNCTION_IRQ_BANK(0x6, 5, 4), /* PG_EINT4 */ SUNXI_FUNCTION(0x7, "io_disabled")), SUNXI_PIN(SUNXI_PINCTRL_PIN(G, 5), SUNXI_FUNCTION(0x0, "gpio_in"), -
回复: 【入门必看】全志V853开发板——构建编译与固件烧篇发布在 V Series
还有一个更加方便的配置编译命令:
- source build/envsetup.sh
- lunch 1
- make && pack
不是很明白为啥楼主要用 ./build.sh 的方式配置编译,就好像不明白我自己刚拿到 SDK 的时候为啥也用 ./build.sh 的方式编译,哈哈。
-
R311 Tina usb gadget ncm wrong ndp sign 问题修复发布在 其它全志芯片讨论区
一、模拟网卡简介
在 Linux 通过 usb 模拟网卡时,有四种方式:
- 使用 usb gadget rndis
- 使用 usb gadget ecm
- 使用 usb gadget ncm
- 使用 usb gadget eem
rndis:
是微软公司制定的协议规范, 不过似乎规范不完整, 引起 rndis host 驱动作者的强烈反对。lichee\linux-4.9\drivers\net\usb\rndis_host.c
ecm:
传输的是纯粹的以太网包,一次USB传输只包含一个以太网帧,因此吞吐量较低,实测在 6MB/s 左右,Windows 的驱动不太好找,Ubuntu 可以直接支持。ncm:
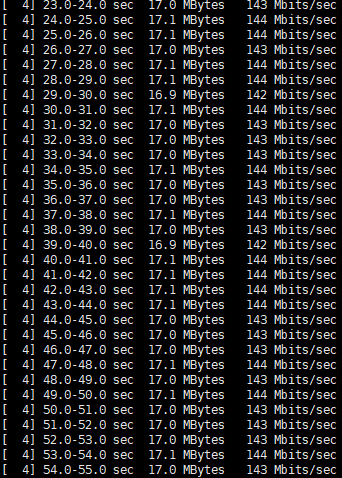
ecm 的改进版本,每个NCM报文可以包含多个以太网帧,这种特性称为报文聚合,即调用一次URB可以发送或者接收多个IP报文,实测在 17MB/s 左右,Windows 自带有驱动(本文在 Win10 平台实测通过),Ubuntu 可以直接支持,本文使用 ncm 方式实现网卡模拟。eem:
了解不多。二、问题现象
启用步骤很简单,全志也有相应的文档介绍,这里只介绍问题以及解决方法。
接入 Windows 之后,启用该网卡,会不停的输出 "Wrong NDP SIGN",并且无法相互 ping 通。
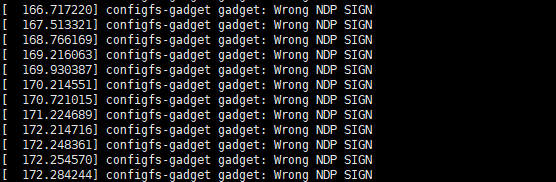
分析发现因为 ncm->ndp_sign 的值等于 0,未被正确赋值。(f_ncm.c)

分析发现 ncm->ndp_sign 只有在设置 CRC 模式的时候才会拷贝 ncm->parser_opts,由此可见 Win10 的 ncm 驱动并未主动配置 CRC 模式引起。

经调试发现 USB_CDC_SET_NTB_FORMAT 会被触发,会设置 ncm->parser_opts,那么如果也顺道一同拷贝 ncm->ndp_sign 应该就能解决问题。
实测确实解决了问题,既然 f_ncm.c 驱动有缺陷,那么很有可能最新的内核已经解决了此问题,查看了最新内核的驱动(v5.18),发现已经调整了 ncm->ndp_sign 顺序,在 switch 语句后面进行赋值,同样也能解决问题。

三、修复补丁
由于 5.9.y 相对于 4.9 版本改动较大,这里发出一个针对 4.9 版本修复此问题的最小改动补丁:
diff --git a/lichee/linux-4.9/drivers/usb/gadget/function/f_ncm.c b/lichee/linux-4.9/drivers/usb/gadget/function/f_ncm.c old mode 100644 new mode 100755 index 639603722..278580b5a --- a/lichee/linux-4.9/drivers/usb/gadget/function/f_ncm.c +++ b/lichee/linux-4.9/drivers/usb/gadget/function/f_ncm.c @@ -828,7 +828,7 @@ static int ncm_setup(struct usb_function *f, const struct usb_ctrlrequest *ctrl) default: goto invalid; } - ncm->ndp_sign = ncm->parser_opts->ndp_sign | ndp_hdr_crc; + // ncm->ndp_sign = ncm->parser_opts->ndp_sign | ndp_hdr_crc; value = 0; break; } @@ -846,6 +846,9 @@ static int ncm_setup(struct usb_function *f, const struct usb_ctrlrequest *ctrl) w_value, w_index, w_length); } + // lmx: fix ncm_unwrap_ntb() --> ncm->ndp_sign to==0, generate "Wrong NDP SIGN" Bug + ncm->ndp_sign = ncm->parser_opts->ndp_sign | (ncm->is_crc ? NCM_NDP_HDR_CRC : 0); + /* respond with data transfer or status phase? */ if (value >= 0) { DBG(cdev, "ncm req%02x.%02x v%04x i%04x l%d\n",实测吞吐量:
-
回复: 【分析笔记】Linux I2C-Tools 使用踩坑笔记发布在 Linux
@dream 在 【分析笔记】Linux I2C-Tools 使用踩坑笔记 中说:
@daizebin sht41 的器件地址是 0x44,就决定了在自动模式下,是以写方式检测,所以可以识别到,但是 sgp41 的器件地址是 0x59,落在了以读方式检测的范围,所以无法识别到。具体看本文 scan_i2c_bus() 的源码截图就能看出来。
再补充一下,不是所有的 I2C 器件都必须要以写的方式才能检测出来,只有少部分,如 sht41\sgp41 这类器件比较特别,需要先写再读才有应答,正因为大部分 I2C 器件无论是读写都会有应答,所以才会因惯性思维,导致踩坑。
-
回复: 【V853开发板试用】使用pack命令报错:ERROR: Unsupport PACK_PLATFORM: tinyos发布在 V Series
最方便的编译方法是:
- source build/envsetup.sh
- lunch 1
你报错,大概是通过 build.sh 编译,在linux_dev 选择了 tinyos,其实你如果选择 openWRT 也是也可以的。
-
【分析笔记】Linux tasklet 机制的理解发布在 Linux
Tasklet 介绍
Linux 内核提供的四种中断下半部中 softirq(软中断)、tasklet(小任务)、workqueue(工作队列) 、request thread(中断线程)中的其中一种,其效率仅次于软中断,但远高于request thread 和 workqueue。
-
软中断(softirq) 之所以性能高的原因,在 SMP 系统下多个 cpu 同时并发处理
如网卡的 fifo 半满中断触发,被 cpu0 处理,cpu0 会在关闭中断后,将数据从网卡的 fifo 拷贝到 ram 之后触发软中断,再打开中断,基于谁触发谁处理原则,cpu0 会继续执行软中断服务函数。若网卡的 fifo 全满中断有再次触发,就会被 cpu1 处理,同样是关闭中断后拷贝数据再开启中断,再去触发和执行软中断进行网卡数据包处理。若此时 cpu0\cpu1 都还在软中断处理数据,网卡再次产生中断,那么 cpu2 就会继续相同的流程。由此可见,软中断充分利用的多 cpu 进行并发处理,因此性能非常高,但也同时因为并发的存在,就需要考虑临界区的问题。 -
小任务(tasklet) 之所以性能较软中断差,是因为同一种小任务在多个 cpu 上不会并发执行
由于 tasklet 基于 softirq 的基础实现,为了易用性考虑,同一种 tasklet 在多个 cpu 上不会并行执行,因此不存在并发问题,在使用上就可以少一些顾虑。但也正是因为不存在并发,导致了性能较之 softirq 差一些。 -
tasklet 之所以比 workqueue 和 request thread 性能高
原因是因为前者是在软中断上下文件工作(意味着不能调用任何阻塞的接口),而后两者是在进程上下文工作(实质上是在内核线程里面执行)。
使用示例模版
#include <linux/module.h> #include <linux/init.h> #include <linux/kernel.h> #include <linux/interrupt.h> static struct tasklet_struct my_tasklet; static void my_tasklet_handle(unsigned long data) { printk("tasklet handle running...\n"); } static irqreturn_t xxx_interrupt(int irq, void *dev_id) { // 调度 tasklet tasklet_schedule(&my_tasklet); } static int __init demo_driver_init(void) { // 初始化一个 tasklet ,关联处理函数 tasklet_init(&my_tasklet, my_tasklet_handle, 0); request_irq(xxx, xxx_interrupt, IRQF_SHARED, xxx, xxx); return 0; } static void __exit demo_driver_exit(void) { tasklet_kill(&my_tasklet); return ; } module_init(demo_driver_init); module_exit(demo_driver_exit); MODULE_LICENSE("GPL v2");内核源码分析
Linux 内核被启动后,会执行 start_kernel() 函数,tasklet 是基于 softirq 实现的,会在 softirq_init() 里面进行必要的初始化,主要是初始化 tasklet 链表和与相应的软中断号建立关联。
tasklet_hi_action 是高优先级的 tasklet,tasklet_action 是普通的 tasklet,两者实现原理都一样。
// kernel\linux-4.9\init\main.c asmlinkage __visible void __init start_kernel(void) { ... softirq_init(); ... } // kernel\linux-4.9\kernel\softirq.c void __init softirq_init(void) { int cpu; // 初始化链表 for_each_possible_cpu(cpu) { per_cpu(tasklet_vec, cpu).tail = &per_cpu(tasklet_vec, cpu).head; per_cpu(tasklet_hi_vec, cpu).tail = &per_cpu(tasklet_hi_vec, cpu).head; } // 建立TASKLET_SOFTIRQ、HI_SOFTIRQ软中断号的对应服务接口 open_softirq(TASKLET_SOFTIRQ, tasklet_action); open_softirq(HI_SOFTIRQ, tasklet_hi_action); }当调用 tasklet_schedule() 时,如果该 tasklet 没有被设置 TASKLET_STATE_SCHED 标记时,才会加入链表内,如果已经设置了 TASKLET_STATE_SCHED 了,那么就会忽略此次的 tasklet _schedule(),这就意味着如果在极短的时间内调用 tasklet_schedule() 只会触发一次(这里可能会存在丢失中断事件的情况),之后会通过 raise_softirq_irqoff() 启用 TASKLET_SOFTIRQ 软中断。
哪颗 cpu 受理该软中断,就将 tasklet 加入到该 cpu 的 tasklet 链表内,由于相同的软中断可以同时被其他 cpu 触发执行,因此会出现 cpu0\cpu1 的 tasklet 链表内有同一个 tasklet 的情况。
// kernel\linux-4.9\include\interrupt.h static inline void tasklet_schedule(struct tasklet_struct *t) { if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state)) __tasklet_schedule(t); } // kernel\linux-4.9\kernel\softirq.c void __tasklet_schedule(struct tasklet_struct *t) { unsigned long flags; // 将指定的 tasklet 加入到链表内并设置软中断 local_irq_save(flags); t->next = NULL; *__this_cpu_read(tasklet_vec.tail) = t; __this_cpu_write(tasklet_vec.tail, &(t->next)); raise_softirq_irqoff(TASKLET_SOFTIRQ); local_irq_restore(flags); }在初始化的时候已经为 TASKLET_SOFTIRQ 软中断与 tasklet_action() 建立关联的关系,因此软中断触发时,就会调用 tasklet_action(),这里是精髓部分。
多次触发软中断时,当前 cpu 只能同一时间执行一次相同的软中断,但是如果有多个 cpu 的话,那么会有多个 cpu 并发执行软中断,所以下面的 tasklet_action() 要想到这一点。
-
tasklet_action() 屏蔽当前 CPU 中断,获取当前 CPU 的 tasklet 链表并清空原有的链表,在恢复中断。避免在操作链表的过程中,被硬件中断打断。
-
开始遍历链表取出 tasklet,先 TASKLET_STATE_RUN 标记确定该 tasklet 是否已经被其它 cpu 执行,因为该 tasklet 在执行的过程中,又被加入到当前的 cpu 的 tasklet 链表内。
-
如果没有被执行,就继续检查该 tasklet 是否被 tasklet_disable(),如果有被 disable 就清除 TASKLET_STATE_RUN 标记,这样可以重新被添加会当前 tasklet 链表内,等待再次执行。如果有被执行,即使又被设置了 TASKLET_STATE_RUN 标记,也会在第 5 步执行完成后,会清除掉该标记。
-
如果没有被 disable,那么就清除 TASKLET_STATE_SCHED 标记,该标记一旦被清除,就意味着在 tasklet 执行期间,tasklet_schedule() 可以继续添加新的 tasklet 其他 cpu 的 tasklet 链表内。如果当前 cpu 已经完成了 tasklet_action() ,新的 tasklet 也可能会重新添加到当前的 tasklet 链表。
-
这里就会执行通过 tasklet_init() 绑定的 func,也就是示例中的 my_tasklet_handle(),执行完成后再清除 TASKLET_STATE_RUN 标记,继续下一个 tasklet。
-
能走到这一步,会有两种情况,一种情况是即将执行 tasklet ,发现已经被 disable 掉了,另外一种情况是 tasklet 已经在其它 CPU 上执行中。无论哪种情况,都会将当前的 tasklet 重新放回到当前 cpu 的 tasklet 链表内,并调用 __raise_softirq_irqoff() 重新触发软中断(应该是启用该软中断)。
注意,以上获取 TASKLET_STATE_RUN 和 TASKLET_STATE_SCHED 标记都是位原子操作,所以不会出现因并发引发的问题。
// kernel\linux-4.9\kernel\softirq.c // 某 CPU 要调度各个 tasklet 的实现 static __latent_entropy void tasklet_action(struct softirq_action *a) { struct tasklet_struct *list; // 1 ------------------------------------------------------ local_irq_disable(); list = __this_cpu_read(tasklet_vec.head); // 获取 tasklet 链表 __this_cpu_write(tasklet_vec.head, NULL); // 清空 tasklet 链表 __this_cpu_write(tasklet_vec.tail, this_cpu_ptr(&tasklet_vec.head)); local_irq_enable(); // 如果存在 tasklet 就会进入循环 while (list) { struct tasklet_struct *t = list; list = list->next; // 2 ------------------------------------------------------ // TASKLET_STATE_SCHED: 表示该 tasklet 已经被挂接到某个 CPU 上 // TASKLET_STATE_RUN: 表示该 tasklet 正在某个 CPU 上执行 // 检查并设置 TASKLET_STATE_RUN 标记 // 返回 1: 表示 tasklet 没有被执行 返回 0: 表示 tasklet 已经被执行 if (tasklet_trylock(t)) { // 3 ------------------------------------------------------ // 如果当前 tasklet 没有被 tasklet_disable() if (!atomic_read(&t->count)) { // 4 ---------------------------------------------- // 清除 TASKLET_STATE_SCHED 状态,便于该 tasklet 可以再次被触发 if (!test_and_clear_bit(TASKLET_STATE_SCHED, &t->state)) BUG(); // 5 ---------------------------------------------- // 这期间,该 tasklet 可以被 tasklet_schedule(),从而引出下面第二种情况 t->func(t->data); // 如果没有执行且没有 disable 则执行 tasklet_unlock(t); // 清理 TASKLET_STATE_RUN 标记 continue; // 继续下一个 tasklet } // 如果当前已经被 disable 了,那就清理 TASKLET_STATE_RUN 标记 tasklet_unlock(t); } // 6 ----------------------------------------------------- // 有两种情况下,会将该 tasklet 再挂接回链表内,并重新触发,等待下一次执行的机会 // 1. 如果没有被执行,但是被调用 tasklet_disable() 接口 disable 了 // 2. 当前 tasklet 已经在其它 CPU 正在执行 func 这时候 tasklet 又会被挂回在 // 原来的链表中,为了满足同一种类型的 tasklet 只能在一个 CPU 上执行的设计 // 因此此次不执行 tasklet,挂入链表后等待下一次被执行的时机执行 local_irq_disable(); t->next = NULL; *__this_cpu_read(tasklet_vec.tail) = t; __this_cpu_write(tasklet_vec.tail, &(t->next)); __raise_softirq_irqoff(TASKLET_SOFTIRQ); local_irq_enable(); } }贴出判断和标记和清除 tasklet 运行的 TASKLET_STATE_RUN 标记代码
// kernel\linux-4.9\include\interrupt.h static inline int tasklet_trylock(struct tasklet_struct *t) { return !test_and_set_bit(TASKLET_STATE_RUN, &(t)->state); } // kernel\linux-4.9\include\interrupt.h static inline void tasklet_unlock(struct tasklet_struct *t) { smp_mb__before_atomic(); clear_bit(TASKLET_STATE_RUN, &(t)->state); }贴出关闭 tasklet 执行的代码
// kernel\linux-4.9\include\interrupt.h static inline void tasklet_disable(struct tasklet_struct *t) { tasklet_disable_nosync(t); tasklet_unlock_wait(t); smp_mb(); } // kernel\linux-4.9\include\interrupt.h // 关闭 tasklet(实际上应该理解为暂停调度执行) static inline void tasklet_disable_nosync(struct tasklet_struct *t) { // 这里对整型原子操作 count 自增了,对应 tasklet_action() 里面的 atomic_read() atomic_inc(&t->count); smp_mb__after_atomic(); } // kernel\linux-4.9\include\interrupt.h static inline void tasklet_enable(struct tasklet_struct *t) { // 这里对整型原子操作 count 自减了,对应 tasklet_action() 里面的 atomic_read() smp_mb__before_atomic(); atomic_dec(&t->count); } tasklet_init() 实现与用户函数关联的接口,也是很简单 // kernel\linux-4.9\kernel\softirq.c void tasklet_init(struct tasklet_struct *t, void (*func)(unsigned long), unsigned long data) { t->next = NULL; t->state = 0; atomic_set(&t->count, 0); t->func = func; t->data = data; }tasklet_kill() 主要实现是尽可能快的让 tasklet 得到执行,等待执行完成后再退出。
-
判断该 tasklet 是否已经被挂接到某个 cpu 的 tasklet 链表内,如果有挂接到,那么就立即让出 cpu,直至 tasklet 清除 TASKLET_STATE_SCHED 标记(参考 tasklet_action() 第 4 个步骤),进入运行状态。
-
如果 tasklet 没有挂接或者一旦进入到执行状态,那么就会不停的检测 TASKLET_STATE_RUN 是否有被清除,被清除的话说明已经运行完成(参考 tasklet_action() 第5个步骤),可以放心的退出了。
// kernel\linux-4.9\kernel\softirq.c void tasklet_kill(struct tasklet_struct *t) { if (in_interrupt()) pr_notice("Attempt to kill tasklet from interrupt\n"); // 1 ---------------------------------------------- while (test_and_set_bit(TASKLET_STATE_SCHED, &t->state)) { do { yield(); } while (test_bit(TASKLET_STATE_SCHED, &t->state)); } // 2 ---------------------------------------------- tasklet_unlock_wait(t); clear_bit(TASKLET_STATE_SCHED, &t->state); } // kernel\linux-4.9\include\interrupt.h static inline void tasklet_unlock_wait(struct tasklet_struct *t) { while (test_bit(TASKLET_STATE_RUN, &(t)->state)) { barrier(); } }至此,tasklet 关键的实现原理分析完成,实际上还应联合 softirq,才算完整的了解整个机制。
Tasklet 机制总结
-
每颗 cpu 都有自己的 tasklet 链表,这样可以将 tasklet 分布在各个 cpu 上,可实现并发不同的 tasklet。
-
相同的 tasklet 只能在某一颗 cpu 上串行执行,其它 cpu 会暂时避让,在此情况下,不需要考虑并发问题(即不需要加锁)。
3. tasklet_schedule() 接口调用时,如果 tasklet 还未被执行,或者处于 disable 期间,指定的 tasklet 不会被加入链表内,即该请求不会被受理。
- tasklet_disable() 接口只是暂时停止指定的 tasklet 执行,依然会被加回待执行链表内。而在 disable 期间,相同的 tasklet 将无法被加入链表调度。
-
-
【分析笔记】Linux 内核自旋锁的理解和使用原则发布在 Linux
自旋锁简单说明自旋锁主要解决在竞态并发下,保护执行时间很短的临界区。它只允许一个执行单位进入临界区,在该执行单位离开前,其它的执行单位将会在进入临界区前不停的循环等待(即所谓的自旋),直至该执行单位离开临界区后,最先等待的一个执行单位会立即进入临界区。此方式不涉及到上下文切换,因此效率极高。
出现并发的场景
硬中断触发打断当前进程、softirq、tasklet、timer等形成的并发
softirq(软中断)、tasklet(小任务)、timer(内核定时器) 触发打断 当前进程(或内核线程)形成的并发
在 SMP 系统下,多次触发 softirq 之间形成的并发(同一个 softirq 可在多个 cpu 并发执行)
在 SMP 系统下,不同 tasklet、timer 之间的并发(同一个 tasklet 和 timer 不会并发执行)
在内核抢占的调度机制形成高低优先级进程之间(或内核线程)的并发额外的注意事项
一、软中断在同一个cpu下并不会并发,但是在多个cpu下是可以并发的,因此性能很高。
如网卡接受数据,产生一个中断后,被 cpu0 处理,关闭中断后,将数据从网卡的 fifo 拷贝到 ram 之后触发软中断,再打开中断,基于谁触发谁处理原则,cpu0 会继续执行软中断服务函数。此时网卡又再次产生中断,会被 cpu1 处理,同样是关闭中断后拷贝数据再开启中断,再去触发和执行软中断进行网卡数据包处理。若此时 cpu0\cpu1 都还在软中断处理数据,网卡再次产生中断,那么 cpu2 就会继续参与,由此可见,软中断充分利用的多 cpu 进行并发处理,因此性能非常高,但也同时因为并发的存在,就需要考虑临界区的问题。
二、同一个 tasklet、timer 在同一时间,只会在一个cpu上运行,是为了易用性做出的牺牲。
由于 tasklet,timer 都是基于 softirq 的基础实现,为了易用性考虑,与 softirq 不同的是,同一种tasklet、timer 在多个cpu上也不会并行执行,因此不存在并发问题。
三、新版本的 Linux 内核不再支持中断嵌套(不确定是从哪个版本开始,以下为内核补丁说明)
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=e58aa3d2d0cc自旋锁的种类说明
最基础的自旋锁有三个版本:
- spin_lock()\spin_unlock()
这是最基础的自旋锁,也是对系统影响最小的自旋锁,在未获得锁时,会自旋等待进入临界区。
- spin_lock_bh()\spin_unlock_bh()
这是在最基础的自旋锁上获取锁之前,先关闭中断底半部,明确的来说就是关闭软中断(包含基于软中断实现的 tasklet 和 timer),主要影响系统的软中断类的并发。
- spin_lock_irq()\spin_unlock_irq()、spin_lock_irqsave()\spin_unlock_irqrestore()
这是在最基础的自旋锁上获取锁之前,先屏蔽当前 cpu 的中断,禁止内核抢占当前进程,主要用于防止软硬件中断并发,影响最大,它影响了当前 CPU 的软硬中断和进程调度。
spin_lock_irq() 是会屏蔽当前 cpu 所有的中断,spin_unlock_irq() 会开启当前 cpu 所有的中断。spin_lock_irqsave() 是现将当前 cpu 的中断使能位取出来,然后在屏蔽当前 cpu 所有中断,spin_unlock_irqrestore() 再恢复之前的中断使能位。
凡是用到 spin_lock_irq()\spin_unlock_irq() 都可以用 spin_lock_irqsave()\spin_unlock_irqrestore() 替换,根据使用情况决定选择哪种方式即可。例如希望中断执行完成后,所有的中断都要开启,那就选择 spin_lock_irq()\spin_unlock_irq(),如果希望中断执行完成后,只需要恢复执行前的中断开关状态,那么就选择 spin_lock_irqsave()\spin_unlock_irqrestore(),如执行前 A中断 本来就要求关闭的,那么执行完之后,还是希望 A中断 仍处于关闭状态。
使用自旋锁的原则
首先要先明确硬件中断的优先级最高,它可以随时打断软中断和内核线程与用户进程,他们之间的优先级如下:
硬中断 >>> 软中断(含基于软中断实现的 tasklet、timer) >>> 内核线程\用户进程
然后需要确定谁可能会并发访问临界区,然后遵循如下规则,选择合适的锁即可:
- 低优先级要防着高优先级的,用能禁止高优先级的自旋锁,而高优先级的只需最简单的锁
- 同等级要防着同等级的, 就使用最简单自旋锁
一、低优先级要防着高优先级的,用能禁止高优先级的自旋锁,而高优先级的只需最简单的锁
例1:用户进程上下文或内核线程 和 硬件中断 都会访问同一个临界区
用户进程:使用 spin_lock_irq()\spin_unlock_irq()
硬件中断:使用 spin_lock()\spin_unlock()
进程上下文访问临界区要防止被硬件中断打断侵入,就需要通过调用 spin_lock_irq()\spin_unlock_irq() 禁止当前 CPU 的中断再去获取锁,那么临界区内就不会被硬件中断访问。但它也只能关闭当前 cpu 的中断,此时其它 cpu 还能继续响应中断,所以中断内部还是需要加上 spin_lock()\spin_unlock() 来保护临界区,即使该中断未拿到锁而持续自旋,也不会影响进程上下文继续执行,顶多就自旋等待一会就能获得锁。
这里也能说明,被自旋锁保护的临界区代码不能太过复杂,不然在这种场景下,就会导致中断自旋时间过长,在该中断自旋期间就无法响应其它的中断,如 tick 心跳中断,最终可能导致系统异常死机。
例2:软中断(softirq、tasklet、timer) 和 硬件中断 都会访问同一个临界区
软件中断:使用 spin_lock_irq()\spin_unlock_irq()
硬件中断:使用 spin_lock()\spin_unlock()
例3:用户进程上下文或内核线程 和 软中断(softirq、tasklet、timer) 都会访问同一个临界区
用户进程:使用 spin_lock_bh()\spin_unlock_bh()
软件中断:使用 spin_lock()\spin_unlock()
进程上下文访问临界区要防止被软中断打断侵入,就需要使用 spin_lock_bh()\spin_unlock_bh() 禁用软中断,但只能关闭当前 cpu 的软中断,其它 cpu 依然能响应软中断,因此还需在软中断中使用 spin_lock()\spin_unlock() 来保护临界区。
二、同等级要防着同等级的, 就使用最简单自旋锁
例1:用户进程上下文或内核线程 和 用户进程上下文和内核线程 即多个进程会访问同一个临界区
只需要使用:spin_lock()\spin_unlock(),因为内核支持抢占调度,所以需要上锁。
例2:不同的 硬件中断 都会访问同一个临界区
只需要使用: spin_lock()\spin_unlock(),不同的硬件中断是可以同时被多颗 cpu 响应处理的,因此需要使用自旋锁进行保护。
如果是旧版内核支持中断嵌套的,则应该使用 spin_lock_irq()\spin_unlock_irq(),以避免被高优先级中断抢占,从而导致出现死锁情况。
例3:不同的 tasklet、timer 会访问同一个临界区
只需要使用:spin_lock()\spin_unlock(),因为不同的 tasklet 或 timer 是可以在不同的 cpu 并发执行。
注意,如果只有相同的 tasklet 或者 timer 访问临界区,是不需要加锁的,因为相同的 tasklet 或 timer 不会并发,即使是有多个 cpu 也不会。
例4:在一个或者多个软中断(softirq) 中会访问同一个临界区
只需要使用:spin_lock()\spin_unlock(),虽然同一时间一个 cpu 只能执行一个软中断,但其它的 cpu 还是可以并发执行相同的软中断的。
三、workqueue、waitqueue、completion 用锁规则
workqueue(工作队列)是基于内核线程实现、waitqueue(等待队列)工作在用户进程上下文、completion(完成量)是基于等待队列实现也是工作在用户进程上下文,因此它们的用锁规则等同于用户进程。
自旋锁的代码分析
自旋锁在不同的硬件环境的实现不一样,此处分析以最复杂的环境下自旋锁的实现原理,即:SMP 下支持任务抢占的硬件环境。
一、自旋锁初始化
锁的数据结构定义,这个数据结构用的是结构体内嵌共用体设计,理解这点非常重要。
#define TICKET_SHIFT 16 // 指明 owner 和 next 的位宽 typedef struct { union { u32 slock; // 32 位 struct __raw_tickets { u16 owner; // 16 位 解锁计数 u16 next; // 16 位 上锁计数 } tickets; }; } arch_spinlock_t; 锁的初始化 spin_lock_init() :lock->raw_lock 成员变量被设置为 __ARCH_SPIN_LOCK_UNLOCKED { { 0 } },即 lock->tickets.owner = 0, lock->tickets.next = 0 #define spin_lock_init(_lock) \ do { \ spinlock_check(_lock); \ raw_spin_lock_init(&(_lock)->rlock); \ } while (0) # define raw_spin_lock_init(lock) \ do { *(lock) = __RAW_SPIN_LOCK_UNLOCKED(lock); } while (0) #define __RAW_SPIN_LOCK_UNLOCKED(lockname) \ (raw_spinlock_t) __RAW_SPIN_LOCK_INITIALIZER(lockname) #define __RAW_SPIN_LOCK_INITIALIZER(lockname) \ { \ .raw_lock = __ARCH_SPIN_LOCK_UNLOCKED, \ SPIN_DEBUG_INIT(lockname) \ SPIN_DEP_MAP_INIT(lockname) } #define __ARCH_SPIN_LOCK_UNLOCKED { { 0 } }二、自旋锁上锁的分析
static __always_inline void spin_lock(spinlock_t *lock) { raw_spin_lock(&lock->rlock); // 调用宏 } #define raw_spin_lock(lock) _raw_spin_lock(lock) // 调用 _raw_spin_lock void __lockfunc _raw_spin_lock(raw_spinlock_t *lock) { __raw_spin_lock(lock); // 继续调用 __raw_spin_lock } static inline void __raw_spin_lock(raw_spinlock_t *lock) { // 设置当前进程不可被抢占 preempt_disable(); spin_acquire(&lock->dep_map, 0, 0, _RET_IP_); // 调用 do_raw_spin_lock LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock); }上面的代码使用 preempt_disable() 设置当前进程不可被抢占,此举可避免在持锁期间被高优先级进程抢占当前进程去访问临界区。
void do_raw_spin_lock(raw_spinlock_t *lock) { debug_spin_lock_before(lock); arch_spin_lock(&lock->raw_lock); // 调用 arch_spin_lock debug_spin_lock_after(lock); } static inline void arch_spin_lock(arch_spinlock_t *lock) { unsigned long tmp; u32 newval; arch_spinlock_t lockval; prefetchw(&lock->slock); __asm__ __volatile__( "1: ldrex %0, [%3]\n" // 4 ------------------------- " add %1, %0, %4\n" // 5 ------------------------- " strex %2, %1, [%3]\n" // 6 ------------------------- " teq %2, #0\n" // 7 ------------------------- " bne 1b" : "=&r" (lockval), "=&r" (newval), "=&r" (tmp) // 1 ----------- : "r" (&lock->slock), "I" (1 << TICKET_SHIFT) // 2 ------------ : "cc"); // 3 指明上述汇编指令会改变条件寄存器 // 8 --------------------------------------------- while (lockval.tickets.next != lockval.tickets.owner) { wfe(); // 让当前 cpu 进入低功耗模式 lockval.tickets.owner = ACCESS_ONCE(lock->tickets.owner); } // 9 --------------------------------------------- smp_mb(); }这部分的代码是实现自旋锁的核心,是通过内嵌汇编指令实现,使用比较关键的汇编指令 ldrex\strex 实现原子访问:
-
ldrex Rx, [Ry]:读取寄存器Ry指向的4字节内存值,将其保存到Rx寄存器中,同时标记对Ry指向内存区域的独占访问
-
strex Rx, Ry, [Rz]:如果发现已经被标记为独占访问了,则将寄存器Ry中的值更新到寄存器Rz指向的内存,并将寄存器Rx设置成0。指令执行成功后,会将独占访问标记位清除。
-
ldrex 负责拷贝数据和独占访问标记,strex 在根据标记存在与否拷贝数据和清除标记的过程是原子操作。
以下为 arch_spin_lock() 的代码进行逐行解释:
-
将 lockval、newval、tmp 局部变量分别与 %0、%1、%2 编号关联(编号对应由编译器指定 CPU 的寄存器)
-
将 &lock->slock 、(1 << TICKET_SHIFT) 分别与 %3、%4 编号关联(编号会由编译器指定 CPU 的寄存器),这里的 TICKET_SHIFT 含义是指明内部变量位宽,代码定义的是 16,表面是 16 位宽的变量,也就是说 %4 是与 1 << 16 关联,便于汇编指令计算。
-
指定此内嵌的汇编指令会修改条件寄存器
-
ldrex 指令实现读取 %3(lock->slock) 里面的数据到 %0(lockval),也就是将入参 lock 的数据拷贝到局部变量 lockval 中,并标记 lock 所在内存的独占访问标记。这一步主要是记录当前锁的计数。
-
add 指令实现将 %0(lockval) + %4(1 << 16) ,结果放到 %1(newval),实现的效果等同于 newval= lockval.slock + (1 << 16)。这个步骤是根据 arch_spinlock_t 数据结构设计的,它内部是一个共同体,slock 与 tickets 使用的是相同的内存空间,slock 的低 16 位等同于 tickets.owner,高 16 位宽等同于 tickets.next。
-
strex 会先检查 %3(lock->slock) 这块内存的独占标记是否还在,如果不在则设置 %2(tmp) 为 1,说明已经被其它线程修改了,如果还在的话设置为 0,将 %1(newval) 数据覆盖到 %3(lock->slock) ,再将独占访问标记清除。这两步主要是借助中间变量 newval 对 next 计数进行自增后,更新到原 lock 里面。
-
teq 和 bne 指令实现判断如果 %2(tmp) 不等于 0,说明已经被其它线程修改了,重新再跳转到标签 1 执行,也就是重新跳转回第 4 个步骤继续执行,否则就继续往下执行。
-
这里主要是不停的判断当前的当前锁的 owen 是否与当前的 next 相等,如果不相等则一直循环检查,这个步骤就是实现了我们所说的自旋功能。当其它持有锁的线程要对该锁进行解锁,解锁的操作会将 owen 自增,当 owen 与当前记录的 next 相等,就会让当前线程退出自旋。
-
自旋退出了,就意味着拿到锁了,就可以访问临界区了。
三、自旋锁解锁的分析
static __always_inline void spin_unlock(spinlock_t *lock) { raw_spin_unlock(&lock->rlock); } #define raw_spin_unlock(lock) _raw_spin_unlock(lock) void __lockfunc _raw_spin_unlock(raw_spinlock_t *lock) { __raw_spin_unlock(lock); } static inline void __raw_spin_unlock(raw_spinlock_t *lock) { spin_release(&lock->dep_map, 1, _RET_IP_); do_raw_spin_unlock(lock); // 2 ------------------------------------- preempt_enable(); } void do_raw_spin_unlock(raw_spinlock_t *lock) { debug_spin_unlock(lock); arch_spin_unlock(&lock->raw_lock); } static inline void arch_spin_unlock(arch_spinlock_t *lock) { smp_mb(); // 1 ------------------------------------- lock->tickets.owner++; dsb_sev(); }-
对 lock->tickets.owner 进行自增,这样可以让等待锁的线程退出自旋
-
恢复内核对当前线程的抢占
推演自旋锁的工作过程:
从自旋锁刚进行初始化的状态来推演:lock->tickets.owner = 0,lock->tickets.next = 0
- 线程A:开始申请锁:读取锁 lock 到临时变量 A.lockval 并设置该内存区域独占标记,此时的状态:
lock->tickets.owner = 0,lock->tickets.next = 0,A.lockval.tickets.owner = 0,A.lockval.tickets.next = 0
- 线程B:开始申请锁:读取锁 lock 到临时变量 B.lockval 并设置该内存区域独占标记,此时的状态:
lock->tickets.owner =0,lock->tickets.next = 0,B.lockval.tickets.owner = 0,B.lockval.tickets.next = 0
- 线程A:计算锁序号:对 A.newval = A.lockval.slock + (1<<16) = 0x10000,此时的状态:
lock->tickets.owner = 0,lock->tickets.next = 0,A.lockval.tickets.owner = 0,A.lockval.tickets.next = 0,A.newval = 0x10000
4. 线程C:开始申请锁:读取锁 lock 到临时变量 lockvalC 并设置该内存区域独占标记,此时的状态:
lock->tickets.owner = 0,lock->tickets.next = 0,C.lockval.tickets.owner = 0,C.lockval.tickets.next = 0
5. 线程B:计算锁序号:对 B.newval = B.lockval.slock + (1<<16) = 0x00 + 0x10000,此时的状态:
lock->tickets.owner = 0,lock->tickets.next = 0,B.lockval.tickets.owner = 0,B.lockval.tickets.next = 0,B.newval = 0x10000
- 线程A:更新锁计数:检查该内存区域的独占访问标记存在,将 A.newval 覆盖到 lock->slock 并清除独占标记,此时的状态:
lock->tickets.owner = 0,lock->tickets.next = 1,A.lockval.tickets.owner = 0,A.lockval.tickets.next = 0,A.newval = 0x10000
- 线程A:锁持有检测:由于 A.lockval.tickets.next == A.lockval.tickets.owner 相等则跳出 while 循环,正式持有锁返回了。
lock->tickets.owner = 0,lock->tickets.next = 1,A.lockval.tickets.owner = 0,A.lockval.tickets.next = 0,A.newval = 0x10000
- 线程B:更新锁计数:检查该内存区域的独占访问标记已被清除,重新读取锁 lock 到临时变量 B.lockval 并设置该内存区域独占标记,此时的状态:
lock->tickets.owner =0,lock->tickets.next = 1,B.lockval.tickets.owner = 0,B.lockval.tickets.next = 1
9. 线程B:计算锁序号:对 B.newval = B.lockval.slock + (1<<16) = 0x10000 + 0x10000,此时的状态:
lock->tickets.owner = 0,lock->tickets.next = 1,B.lockval.tickets.owner = 0,B.lockval.tickets.next = 1,B.newval = 0x20000
- 线程B:更新锁计数:检查该内存区域的独占访问标记存在,将 B.newval 覆盖到 lock->slock 并清除独占标记,此时的状态:
lock->tickets.owner = 0,lock->tickets.next = 2,B.lockval.tickets.owner = 0,B.lockval.tickets.next = 1,B.newval = 0x20000
- 线程B:锁持有检测:由于 B.lockval.tickets.next != B.lockval.tickets.owner,因此进入 while 循环,不停的读取 lock->tickets.owner 并覆盖到 B.lockval.tickets.owner
lock->tickets.owner = 0,lock->tickets.next = 2,B.lockval.tickets.owner = 0,B.lockval.tickets.next = 1,B.newval = 0x20000
12. 线程C:计算锁序号:对 C.newval = C.lockval.slock + (1<<16) = 0x00 + 0x10000,此时的状态:
lock->tickets.owner = 0,lock->tickets.next = 0,C.lockval.tickets.owner = 0,C.lockval.tickets.next = 0,C.newval = 0x10000
- 线程C:更新锁计数:检查该内存区域的独占访问标记已被清除,重新读取锁 lock 到临时变量 C.lockval 并设置该内存区域独占标记,此时的状态:
lock->tickets.owner = 0,lock->tickets.next = 2,C.lockval.tickets.owner = 0,C.lockval.tickets.next = 2
14. 线程C:计算锁序号:对 C.newval = C.lockval.slock + (1<<16) = 0x20000 + 0x10000,此时的状态:
lock->tickets.owner = 0,lock->tickets.next = 2,C.lockval.tickets.owner = 0,C.lockval.tickets.next = 2,C.newval = 0x30000
- 线程C:更新锁计数:检查该内存区域的独占访问标记存在,将 C.newval 覆盖到 lock->slock 并清除独占标记,此时的状态:
lock->tickets.owner = 0,lock->tickets.next = 3,C.lockval.tickets.owner = 0,C.lockval.tickets.next = 2,C.newval = 0x30000
- 线程C:锁持有检测:由于 C.lockval.tickets.next != C.lockval.tickets.owner,因此进入 while 循环,不停的读取 lock->tickets.owner 并覆盖到 C.lockval.tickets.owner
lock->tickets.owner = 0,lock->tickets.next = 3,C.lockval.tickets.owner = 0,C.lockval.tickets.next = 2
至此,线程B 一直在等待 lock->tickets.owner 等于 1,而 线程C 则一直在等待 lock->tickets.owner 等于 2
- 线程A:访问完临界区后,调用 spin_unlock() 释放锁,lock->tickets.owner = lock->tickets.owner + 1
lock->tickets.owner = 1,lock->tickets.next = 3
- 线程B:锁持有检测:读取 lock->tickets.owner 并覆盖到 B.lockval.tickets.owner,由于 B.lockval.tickets.next == B.lockval.tickets.owner 相等则跳出 while 循环,正式持有锁返回了。
lock->tickets.owner = 1,lock->tickets.next = 3,B.lockval.tickets.owner = 1,B.lockval.tickets.next = 1
- 线程C:锁持有检测:继续读取 lock->tickets.owner 并覆盖到 C.lockval.tickets.owner,由于 C.lockval.tickets.next != C.lockval.tickets.owner,继续循环自旋。
lock->tickets.owner = 1,lock->tickets.next = 3,C.lockval.tickets.owner = 1,C.lockval.tickets.next = 2
- 线程B:访问完临界区后,调用 spin_unlock() 释放锁,lock->tickets.owner = lock->tickets.owner + 1
lock->tickets.owner = 2,lock->tickets.next = 3
- 线程C:锁持有检测:读取 lock->tickets.owner 并覆盖到 C.lockval.tickets.owner,由于 C.lockval.tickets.next == C.lockval.tickets.owner 相等则跳出 while 循环,正式持有锁返回了。
lock->tickets.owner = 2,lock->tickets.next = 3,C.lockval.tickets.owner = 2,C.lockval.tickets.next = 2
整个过程推演完毕,很巧妙的借助两个计数器和局部变量,实现等锁线程的有序排队,该思路也适用于应用程序开发。
自旋锁的原理总结
-
自旋锁是通过 ldrex、strex 来确保读写锁的计数器是原子操作的,这是 arm 芯片级实现的。
-
在上锁的过程中,会有两处循环,第一处是汇编指令循环, 第二处是 C 语言的 while 循环,两个循环的意义不一样:
-
汇编指令循环:实现对锁计数器的原子读写,确保得到的锁数据是最新的,锁的计数更新是准确无误的。
-
C语言的循环:实现锁在等待时的自旋功能,通过比较计数器,实现谁先等待锁,谁就先得到锁的有序排队。
以上两个循环的协同工作,前者实现原子操作和记录,后者实现了有序排队,完成了自旋锁的核心互斥功能。
-
Yuzuki Lizard V851S 开发板 WIFI 功能异常发布在 V Series
没查出是什么原因,有哪位大神可以帮忙看看是什么问题?
源码来源:github docker [https://github.com/YuzukiHD/Yuzukilizard]
问题现象:使用未经修改的 SDK 编译出来的固件,无法正常扫描 SSID 和连接 WIFI。
已经排查:
- 确认有识别到 XR829。
- 确认有成功下载 firmware。
- 确认所选的配置是 40M,且 GPIO 配置正确。
- 使用 iw 和 wifi -s 都不能正常扫描 ssid。
- 使用 ifconfig waln0 可以正常的 up、down。
问题日志:以下是内核启动 WIFI 时的日志输出:
[ 5.782165] ======== XRADIO WIFI OPEN ======== [ 5.787181] [XRADIO] Driver Label:XR_V02.16.91 _HT40_01.33 Feb 17 2024 10:35:49 [ 5.795746] [XRADIO] Allocated hw_priv @ c37c6c80 [ 5.801281] [XRADIO_ERR] Access_file failed, path:/data/misc/wifi/xr_wifi.conf! [ 5.810623] sunxi-wlan soc@03000000:wlan@0: bus_index: 1 [ 5.926666] sunxi-mmc sdc1: sdc set ios:clk 0Hz bm PP pm UP vdd 21 width 1 timing LEGACY(SDR12) dt B [ 5.936923] [XRADIO] Detect SDIO card 1 [ 5.951799] sunxi-mmc sdc1: no vqmmc,Check if there is regulator [ 5.979134] sunxi-mmc sdc1: sdc set ios:clk 400000Hz bm PP pm ON vdd 21 width 1 timing LEGACY(SDR12) dt B [ 6.019771] sunxi-mmc sdc1: sdc set ios:clk 400000Hz bm PP pm ON vdd 21 width 1 timing LEGACY(SDR12) dt B [ 6.034411] open /dev/mtd1 failed,ret=-6 [ 6.034423] remoteproc0: Can't finded boot_package head [ 6.034428] remoteproc0: sunxi_request_firmwarefailed,ret=-19 [ 6.054089] sunxi-mmc sdc1: sdc set ios:clk 400000Hz bm PP pm ON vdd 21 width 1 timing LEGACY(SDR12) dt B [ 6.075296] sunxi-mmc sdc1: sdc set ios:clk 400000Hz bm PP pm ON vdd 21 width 1 timing SD-HS(SDR25) dt B [ 6.086091] sunxi-mmc sdc1: sdc set ios:clk 50000000Hz bm PP pm ON vdd 21 width 1 timing SD-HS(SDR25) dt B [ 6.097147] sunxi-mmc sdc1: sdc set ios:clk 50000000Hz bm PP pm ON vdd 21 width 4 timing SD-HS(SDR25) dt B [ 6.108870] mmc1: new high speed SDIO card at address 0001 [ 6.115965] [SBUS] XRadio Device:sdio clk=50000000 [ 6.123030] [XRADIO] XRADIO_HW_REV 1.0 detected. [ 6.179491] [XRADIO] xradio_update_dpllctrl: DPLL_CTRL Sync=0x00c00000. [ 6.215546] [XRADIO] Bootloader complete [ 6.324725] [XRADIO] Firmware completed. [ 6.330654] [WSM] Firmware Label:XR_C09.08.52.73_DBG_02.122 2GHZ HT40 May 18 2021 13:36:09 [ 6.348111] [XRADIO] Firmware Startup Done. [ 6.353158] [XRADIO_WRN] enable Multi-Rx! [ 6.370051] ieee80211 phy0: Failed to initialize wep: -2 [ 6.376126] ieee80211 phy0: Selected rate control algorithm 'minstrel_ht' [ 6.472871] [VIN_WARN]sensor_helper_probe: cannot get sensor0_cameravdd supply, setting it to NULL! [ 6.483380] [VIN_WARN]sensor_helper_probe: cannot get sensor0_iovdd supply, setting it to NULL! [ 6.493411] [VIN_WARN]sensor_helper_probe: cannot get sensor0_avdd supply, setting it to NULL! [ 6.503160] [VIN_WARN]sensor_helper_probe: cannot get sensor0_dvdd supply, setting it to NULL! [ 6.583658] sunxi_i2c_do_xfer()1974 - [i2c1] incomplete xfer (status: 0x20, dev addr: 0x37) [ 6.593242] sunxi_i2c_do_xfer()1974 - [i2c1] incomplete xfer (status: 0x20, dev addr: 0x37) [ 6.602769] sunxi_i2c_do_xfer()1974 - [i2c1] incomplete xfer (status: 0x20, dev addr: 0x37) [ 6.612213] [VIN_DEV_I2C]gc2053_mipi sensor read retry = 2 [ 6.819401] sunxi_i2c_do_xfer()1974 - [i2c1] incomplete xfer (status: 0x20, dev addr: 0x37) [ 6.828941] sunxi_i2c_do_xfer()1974 - [i2c1] incomplete xfer (status: 0x20, dev addr: 0x37) [ 6.838493] sunxi_i2c_do_xfer()1974 - [i2c1] incomplete xfer (status: 0x20, dev addr: 0x37) [ 6.847865] [VIN_DEV_I2C]gc2053_mipi sensor read retry = 2 [ 7.074215] sunxi_i2c_do_xfer()1974 - [i2c1] incomplete xfer (status: 0x20, dev addr: 0x37) [ 7.083765] sunxi_i2c_do_xfer()1974 - [i2c1] incomplete xfer (status: 0x20, dev addr: 0x37) [ 7.093316] sunxi_i2c_do_xfer()1974 - [i2c1] incomplete xfer (status: 0x20, dev addr: 0x37) [ 7.102687] [VIN_DEV_I2C]gc2053_mipi sensor read retry = 2 [ 7.309327] sunxi_i2c_do_xfer()1974 - [i2c1] incomplete xfer (status: 0x20, dev addr: 0x37) [ 7.318844] sunxi_i2c_do_xfer()1974 - [i2c1] incomplete xfer (status: 0x20, dev addr: 0x37) [ 7.328392] sunxi_i2c_do_xfer()1974 - [i2c1] incomplete xfer (status: 0x20, dev addr: 0x37) [ 7.337775] [VIN_DEV_I2C]gc2053_mipi sensor read retry = 2 [ 7.343932] [gc2053_mipi] error, chip found is not an target chip. [ 7.363360] [VIN_ERR]registering gc2053_mipi, No such device! [ 7.603549] udevd[893]: could not create /tmp/run/udev: No such file or directory [ 8.251755] file system registered [ 8.269359] configfs-gadget 4100000.udc-controller: failed to start g1: -19 [ 8.381933] read descriptors [ 8.385211] read strings [ 8.543205] sunxi_set_cur_vol_work()482 WARN: get power supply failed [ 8.630668] android_work: sent uevent USB_STATE=CONNECTED [ 8.814319] configfs-gadget gadget: high-speed config #1: c [ 8.820726] android_work: sent uevent USB_STATE=CONFIGURED [ 11.049029] ieee80211_do_open: vif_type=2, p2p=0, ch=3, addr=54:0d:42:ee:1a:22 [ 11.057317] [STA] !!!xradio_vif_setup: id=0, type=2, p2p=0, addr=54:0d:42:ee:1a:22 [ 11.070863] [AP_WRN] BSS_CHANGED_ASSOC but driver is unjoined. [ 11.089296] IPv6: ADDRCONF(NETDEV_UP): wlan0: link is not ready在使用扫描的时候,会出现如下问题:
root@TinaLinux:/# iw wlan0 scan scan aborted! [ 374.889081] [SCAN_WRN] Timeout waiting for scan complete notification. [ 374.896412] [SCAN_WRN] xradio_scan_timeout:scan timeout cnt=1 [ 374.902934] [SCAN_ERR] Scan failed (-110). [ 375.902951] [WSM_ERR] [FW-DEBUG] DbgId = 4 [ 375.907562] [WSM_ERR] [FW-DEBUG] 0x000F4242从日志信息来看,通信和下载 WIFI 固件都没有问题,也尝试过使用 wifi -o sta 之后再 wifi -s,也不行。
[ 374.889081] [SCAN_WRN] Timeout waiting for scan complete notification. [ 374.896412] [SCAN_WRN] xradio_scan_timeout:scan timeout cnt=1 [ 374.902934] [SCAN_ERR] Scan failed (-110). [ 375.902951] [WSM_ERR] [FW-DEBUG] DbgId = 4 [ 375.907562] [WSM_ERR] [FW-DEBUG] 0x000F4242 [ 375.912376] [SCAN_WRN] Scan timeout already occured. Don't cancel work [ 730.729141] [SCAN_WRN] Timeout waiting for scan complete notification. [ 730.736667] [SCAN_WRN] xradio_scan_timeout:scan timeout cnt=2 [ 730.743224] [SCAN_ERR] Scan failed (-110). [ 731.743199] [WSM_ERR] [FW-DEBUG] DbgId = 4 [ 731.747803] [WSM_ERR] [FW-DEBUG] 0x000F4241
