太干了,OpenPPL做的RISC-V技术解析
-
转自OpenPPL公众号:https://mp.weixin.qq.com/s/jw_8BSlZKjM9-0KBPqX2vw
2月24日(周四)19:00,OpenPPL 实战训练营系列课程第七期,商汤科技高性能计算工程师焦明俊为大家带来了「OpenPPL RISC-V 技术分享」的专题课程。
OpenPPL RISC-V 是针对全志 AllWinner D1 平台 RISC-V 架构的深度学习推理引擎。
本期课程结合了 RISC-V V 指令集以及全志 D1 开发板的微架构特点,对推理引擎的算法设计进行技术解析。
以下为本次公开课的课程总结~
Part 1 | RVV 指令集概述
Part 2 | AllWinner D1 微架构特点
Part 3 | OpenPPL RISC-V 算法设计
Part 4 | OpenPPL RISC-V 性能展示
Part 5 | Q&A
Part 6 | 课程表Part 1 RVV指令集概述
1.1 RISC-V定义
RISC-V 是一个基于精简指令集 risc 原则的开源指令集架构,其指令使用模块化设计,包括基本指令集以及额外可选择的扩展指令集。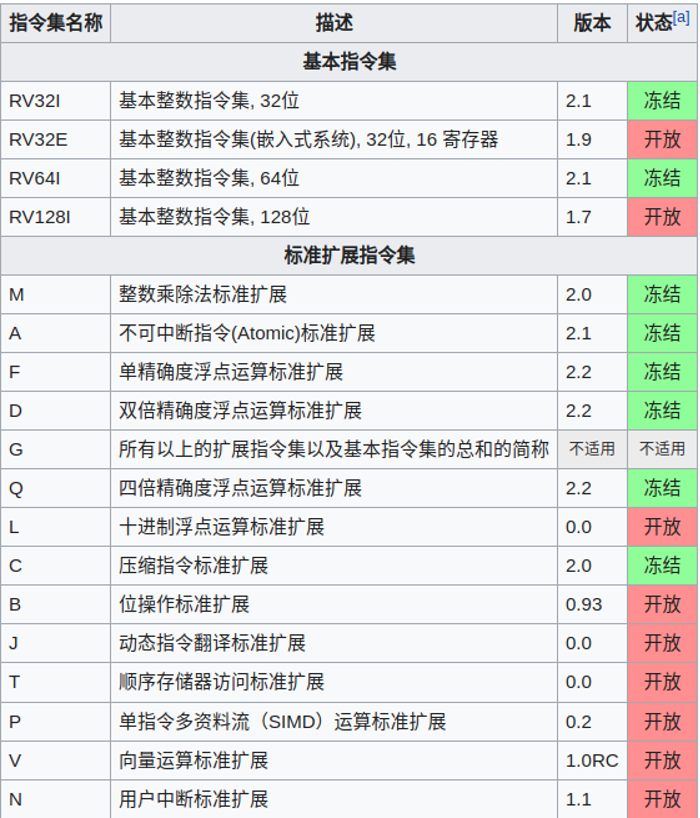
1.2 微指令集的使用
• 向量设置/控制指令
• vsetvl、vsetvli —— 用来配置 vl、vtype 寄存器
• 向量加载存储指令
• vle.v、vse.v
• 读取/修改向量寄存器指令
• vmv.v.v、vmv.v.x、vmv.v.i
• vrgather.v.v、vrgather.v.x、vrgather.v.i

1.3 向量算数运算指令
• vfadd.vv、vfadd.vf
• vfsub.vv、vfsub.vf
• vfmul.vv、vfmul.vf
• vfdiv.vv、vfdiv.vf
• vfmacc.vv、vfmacc.vf
• 对比 arm neon :vfma —— 支持向量-向量元素乘累加操作
Part 2 AllWinner D1 微架构特点
2.1 C906 处理器的体系结构特点(用户手册)
• 支持 RV64 IMA[FD]C[V]指令子集
• 5级单发射顺序执行流水线
• 一级哈佛结构的指令/数据缓存(各32K)
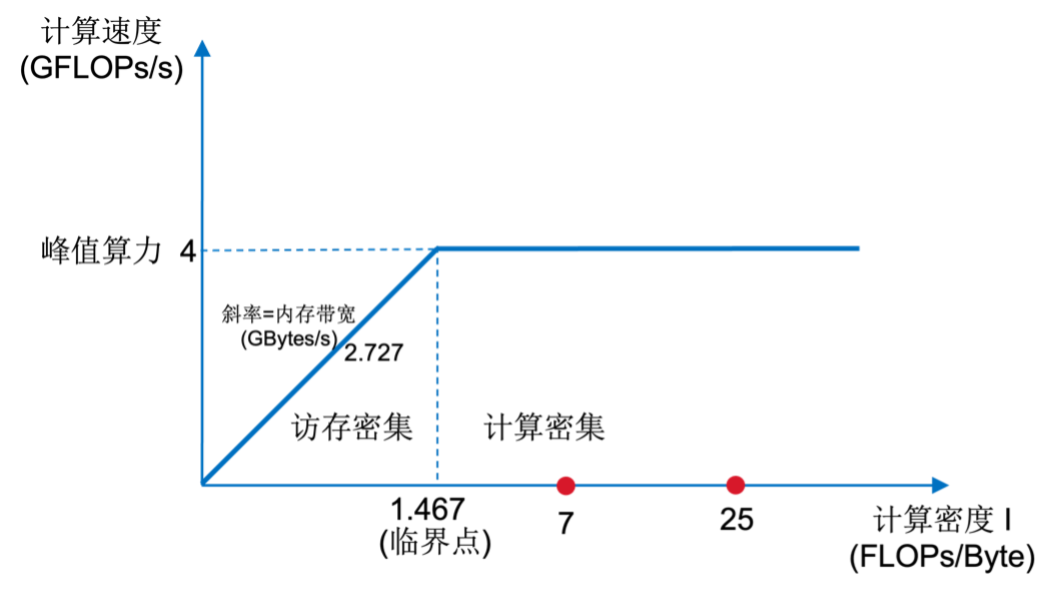
• 算力可达 4GFlops(@1GHz)
• 遵循 RVV 向量扩展标准(RVV 0.7.1)
• 支持 int8/ int16/ int32/ int64/ fp16/ fp32/ fp64/ bfp16 向量运算
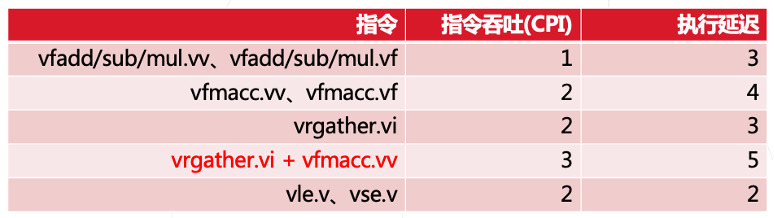
2.2 性能参数实测
• 指令吞吐
通过构建无数据依赖的相互独立的指令流来测试每条指令的执行周期数(CPI)。
• 指令延迟
通过构建具有写后读相关性的指令流序列来测试不同指令的执行延迟。
• 访存带宽
通过构建 Cache 命中率为百分百和零的两种指令流分别测试 Cache 和主存 DDR 的带宽。
2.3 实测性能参数结果
• 指令吞吐、指令延迟
• 访存带宽
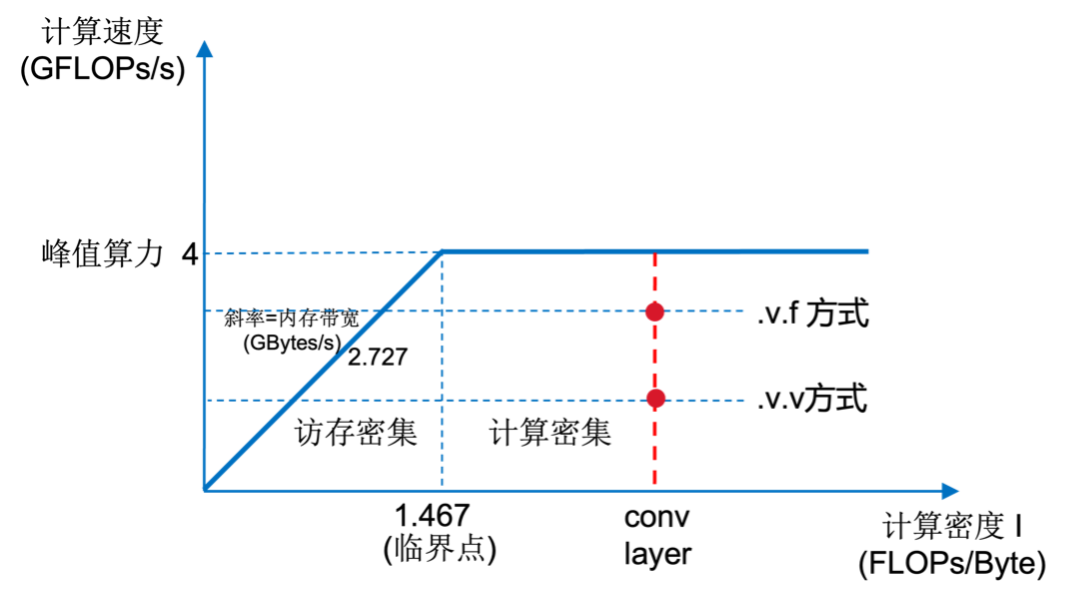
Cache :8 GB/s
Memory : 2.727 GB/s (DDR3 792 MHz)
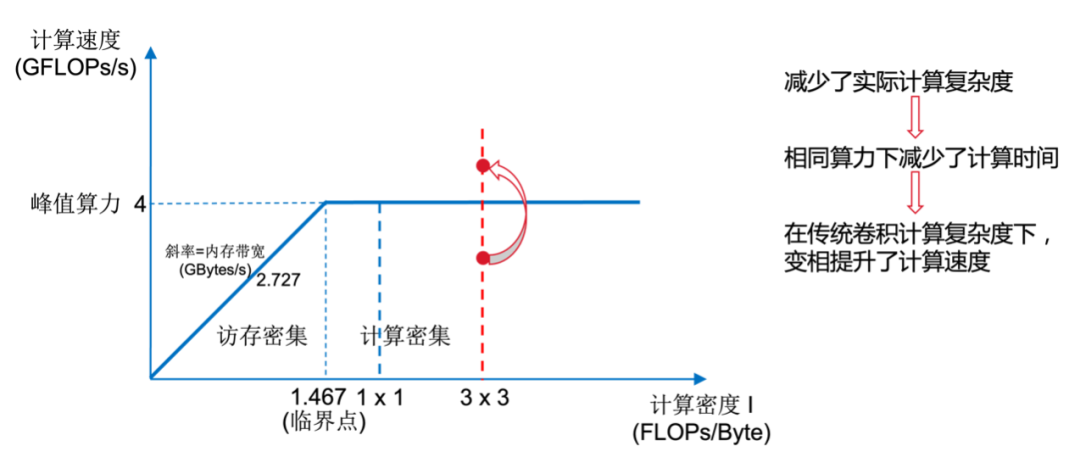
• 构建roofline模型
Part 3 OpenPPL RISC-V算法设计
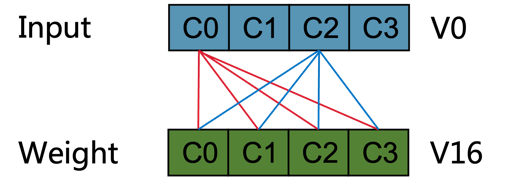
3.1 通用GEMM KERNEL的设计
• 向量广播乘累加操作性能分析
- 由于采取 NBCX 的数据排布,需要将 V0 各通道元素广播分别与 V16 进行乘累加
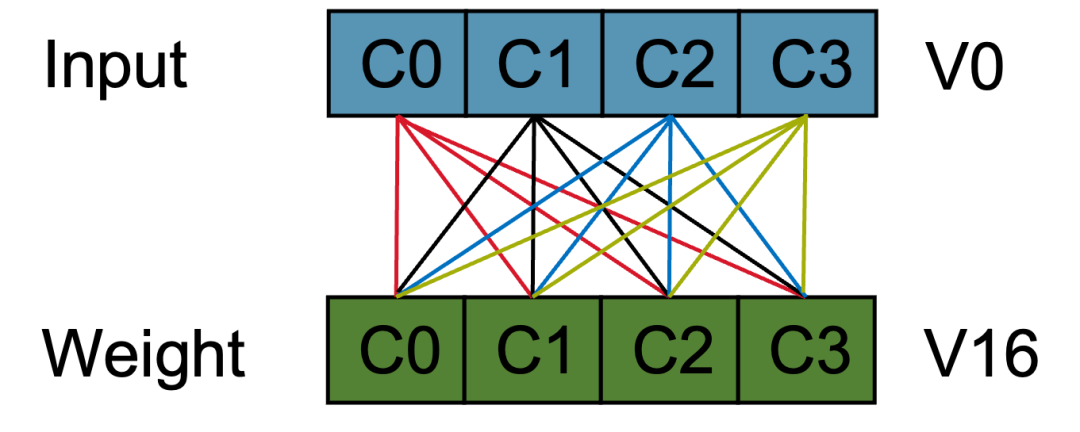
2)相关代码
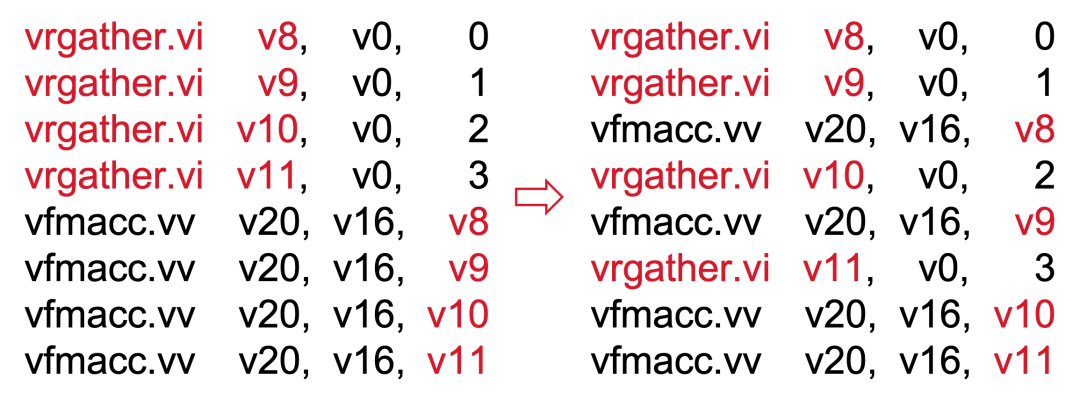
i. 代码左:2 * 4 + 2 * 4 = 16 (cycle)
ii.代码右:2 + 3 * 3 + 2 = 13 (cycle)
3)由于需要使用 gather 指令
i. 占用了向量寄存器
ii.添加了与计算无关的寄存器间数据传递指令
• gemm_kernel 的设计
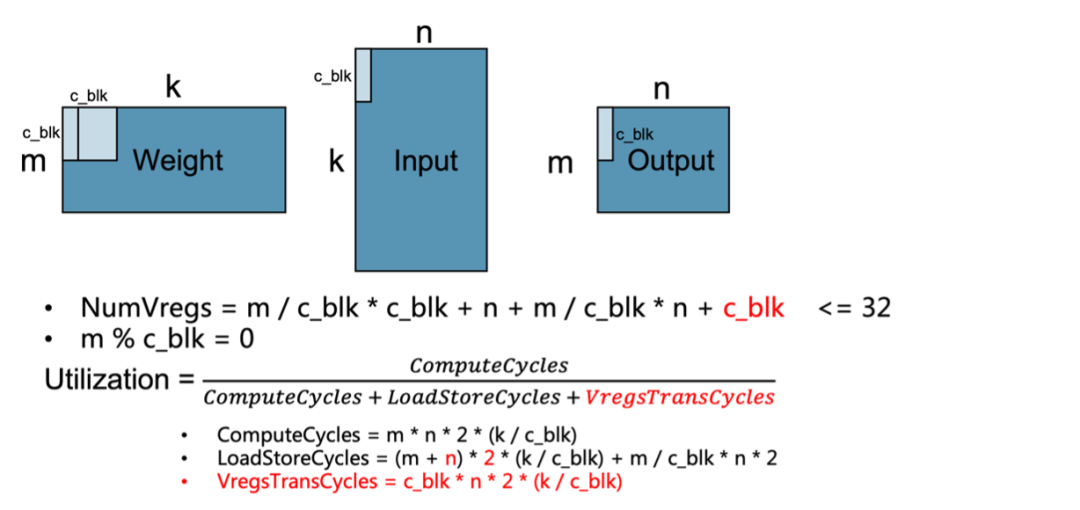
假设数据都在Cache中并且k足够大,在寄存器的约束下寻找最合适的kernel size (m/n)来达到最高的gemm_kernel性能。
-
方式一:
权重、输入均放入向量寄存器,使用向量-向量(vv)算数指令计算
weight/input : vle.v、vse.v
compute: vfmacc.vv
-
方式二:
权重放入向量寄存器,输入放入标量寄存器,使用向量-标量(vf)指令计算
weight : vle.v、vse.v
input : flw
compute : vfmacc.vf

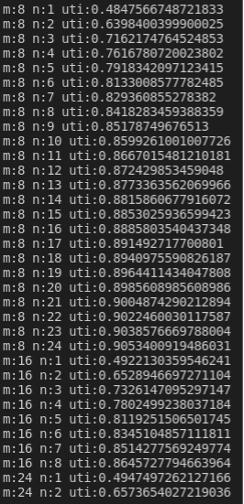
• 不同kernel size下计算指令的占用率
- vv指令在不同kernel size下计算指令的占用率

- vf指令在不同kernel size下计算指令的占用率
- 对应到roofline模型中的位置
3.2 gemm实现的两种选择
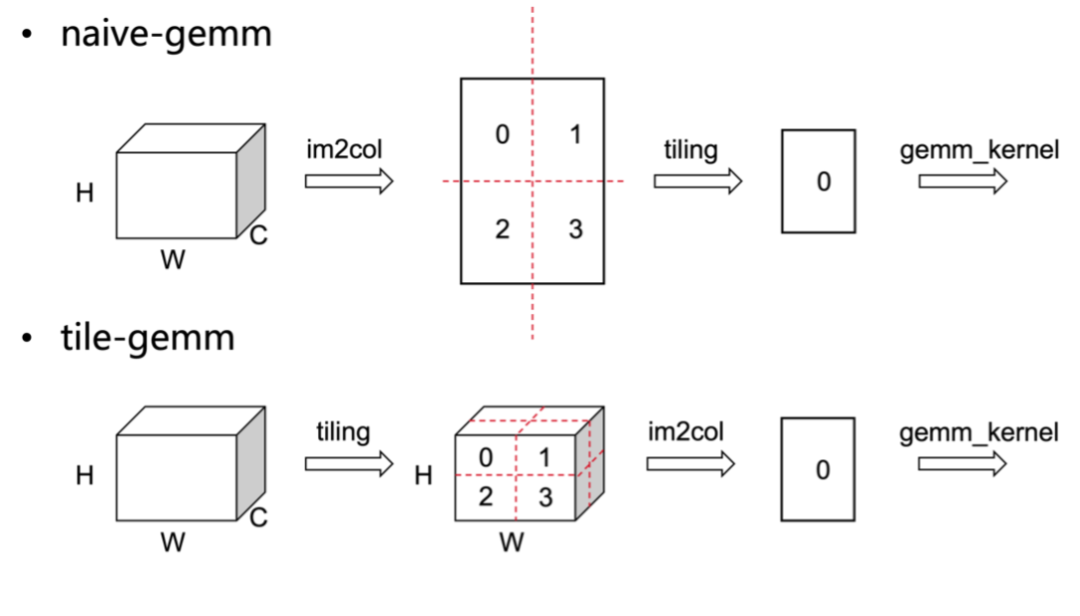
naive-gemm 优劣
• 需要开辟一块额外内存空间用来存放整张图的 im2col 结果
• im2col 过程仅需一次
• 由于Cache大小的局限性,无法合并 im2col 与 tiling 流程
• 非 1x1 卷积核下,无额外 tiling 开销
tile-gemm 优劣
• 仅需一小块 tile 大小的内存空间来存放 tile 的 im2col 结果
• 由于 Output Station 的循环计算策略,im2col 过程需要执行多次
• 可合并 tiling 与 im2col 流程,并将结果直接送入 Cache 中
• 非 1x1 卷积核下,在原图上 tiling 划分会有重叠数据开销
• 举例:
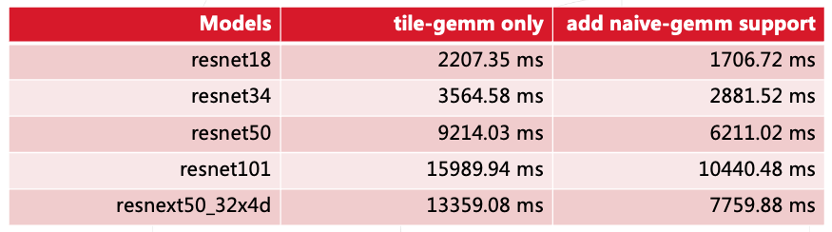
在IC较大的网络下,添加 naive-gemm对性能提升的效果。
3.3 快速卷积算法-Winograd分析
• direct conv
Td = OC * OH * OW * IC * f * f * 2• winograd conv
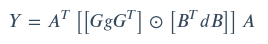
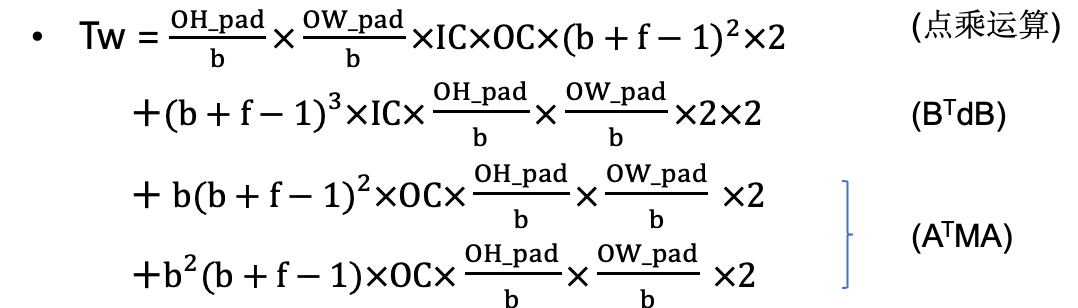
• 加速比
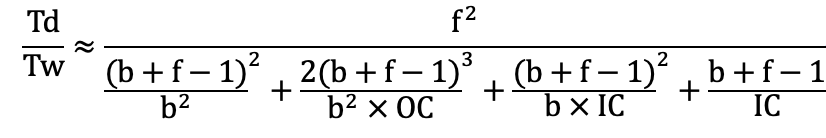
分析
• 随着 IC/OC 的增大, TBTdB / TATMA 两者减小,加速效益更明显
• 以上 IC/OC 较大的前提下,
• f 固定,随着 b 的增大,加速效益更明显 • b 固定,随着 f 的增大,加速效益更明显 • f 为 1 时,加速比为 1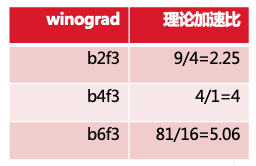
• Winograd算法提升性能的本质
Part 4 OpenPPL RISC-V性能展示
4.1 OpenPPL RISC-V使用方式
fp32 测试
• ./pplnn --use-riscv -- onnx-model model.onnx --inputs input.bin
fp16 测试
• ./pplnn --use-riscv --use-fp16 --onnx-model model.onnx --inputs input.bin
其他命令设置项
•--help :显示所有命令设置项
•--enable-profiling :显示网络性能分析详细结果
•--save-inputs :保存输入数据到指定文件
•--save-outputs :保存输出数据到指定文件
•--min-profiling-iterations :设置最小profiling迭代次数
•--wg-level :设置winograd快速算法级别
4.2 性能结果
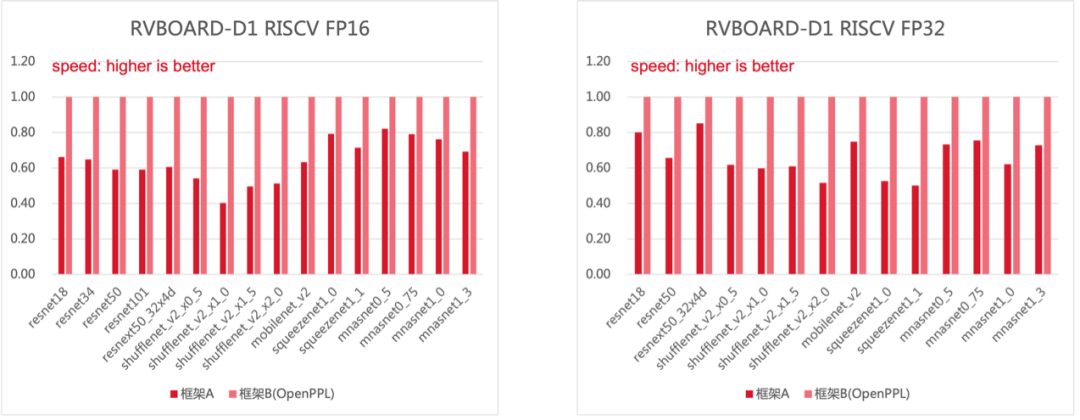
OpenPPL在 fp16 和 fp32 精度上均能够达到平均 1.5 倍于框架A的性能。
4.3 OpenPPL RISC-V开发计划与展望
支持更多的网络模型和算子
• 语义分割、目标检测等网络
• 视觉 CV 算子
支持
• 兼容 RVV 0.7.1 和 RVV 1.0 标准版本
• 可变长 VLEN 支持
Part 5 Q&A
Q1. Tile-gemm 的优势 case 有多快?
Tile-gemm的优势在于,在tile划分较少的情况下,它相对于naive-gemm会有比较大的优势。这种情况下,在一些比较小的网络里面会有一些比较好的效果,比如mobile net。具体数据可以在微信群做进一步探讨。Q2. RISC-V 上 depth-wise 卷积有优势吗?gemm kernel 的性能是多少?
关于depth-wise卷积,这边暂时没有去做具体的测试,但据了解应该是不会有劣势的。
关于gemm kernel的性能上限,可以参考内容截图。如果使用vv的计算方式,理论上限大概在50%,理论峰值就是4GFLOPs的50%左右;但如果使用vf指令,能够达到它理论峰值的80%,即4*80%,3.2GFLOPs。
-
于是框架A是ncnn嘛?

-
@nihui 要对ncnn有信心

-

Copyright © 2024 深圳全志在线有限公司 粤ICP备2021084185号 粤公网安备44030502007680号