【DIY教程】用D1哪吒开发板做一个卡牌识别机,可以玩游戏王、狼人杀、三国杀、剧本杀
-
前要
卡牌游戏从诞生之初就因为其独特的玩法和相较其他类型的游戏在休闲程度上,在其方便快捷、操作简单、自动高效的特点,迅速火遍手机游戏市场,不同厂商根据其故事题材及剧情线可制作出各式各样的卡牌动画、玩法模式,让不同年龄段的玩家都能感受到自己喜欢的剧情及游戏风格在棋牌上演绎。而在茶前饭后,朋友聚会,火遍桌游的狼人杀、炉石传说等著名的卡牌游戏,也迅速占领手机游戏市场,而在线下,有着非常著名的一些玩法,如:万智牌、游戏王、口袋妖怪卡等。卡牌游戏其魅力不仅在玩法上的多样,更在集卡集英雄时的快乐。

百度词条之卡牌游戏
为了在集卡过程中和桌游过程中,让玩家们不在看着单调静态的卡片只将目光聚焦于玩法,同时卡牌游戏本事所具有的故事线和故事背景也值得玩家们在桌游中聚焦。本项目,准备使用哪吒开发板+机器视觉+多媒体技术完成一个提升卡牌游戏桌游的趣味性的小玩意。

小项目实现方式
思维导图:
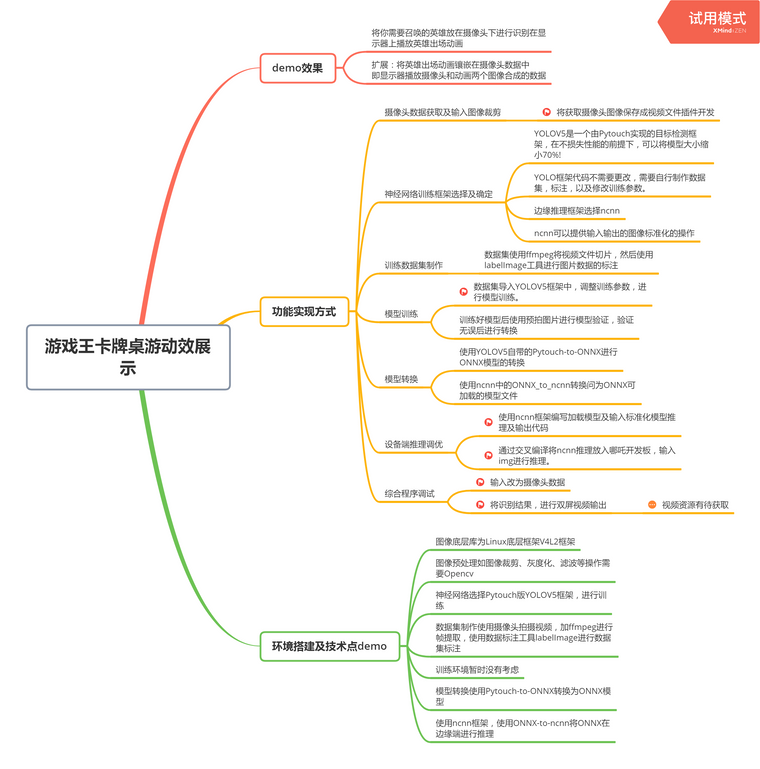
不知道看不看的清楚
看不清楚可以留言告诉我! 非常感谢
非常感谢
项目进展
拍照及摄影
拍照使用V4L2框架,对摄像头输出数据进行保存即可拍照,拍照详情见D1官方文档:
摄影期间踩了比较多的坑。下面我一一列举:1.原本以为照片的集合就是视频了,然后我就是用图片叠加写入的方式,将70帧图片写入一个文件,然后发现他并不是一个视频文件。并不能通过播放器打开。
2.通过查找资料,发现视频文件是需要专门的编码格式文件。然后就摄像头输出文件进行编码。
-
首先尝试了JPEG照片文件应该怎么编码,发现这个数据使用MJPEG高清编码会比较好,但是没有找到对应的实现方式。需要从github上找找。(此坑等填)

-
在网上看到有关编码的教程都是针对YUV格式的编码。然后就尝试使用YUV图片,此处可能成功但没有使用响应的软件打开(我自己电脑的问题)没有验证。但时看文件是由大小的(然后我就假装可以了)
-
然后就针对YUV格式进行编码,在网上找到了X264的编码库,已经成功移植到板子上,但是在这边软件实现上,仍然打不开编码的文件(失败了???? (又是一个坑)

-
我突然想到我移植了Opencv,为何不通过Opencv直接保存视频呢?然后我就写了一个简单的Opencv的程序。在Tina中 使用Opencv 的Videocopter 打不开系统摄像头?? 他找不到摄像头???? 然后就找了几个方法 1. 修改摄像头初始化的参数.set()函数。没有成功!2. 可能是设备号的问题。通过遍历打开,可能的所有设备号。也没有成功! (然后Opencv就打不开摄像头,希望这块会的大佬可以看看是什么问题)。

-
在我个人技术实在不能通过软件的方法来实现的时候,我终于还是选择了ffmeg,通过交叉编译,将ffmpeg移植进开发板中。使用ffmpeg指令终于可以进行录像。

使用FFmpeg会由如下几种问题,由于FFmpeg 默认已经编码加上哪吒算力有限,其编码速度为3fps~5fps,且在编码1000张图片后就会开始提示警告。可能是哪吒算力的问题吧?吧?
最后为了 训练集的准确性和效率,我没有选择使用ffmpeg,我自己写了一个demo,可以使用开发板上的按键进行控制拍照保存图片,每次拍一组准备。开始制作数据集,上面的坑慢慢填~!!!!

YOLOV5框架
已在yolov5官方下载源码,并下载了yolov5的官方模型,使用官方模型跑通了测试图片。
数据集制作
下载了ffmpeg源码并完成了编译。等摄影程序调试好对视频进行切帧制作训练数据集。
模型训练
待更新。。。。。
-
-
这个小demo的灵感,来源于前些天很火的一个司法拍卖:
80块钱游戏卡“青眼白龙”拍出8700万天价!原主人是95后贪污近7000万被判无期
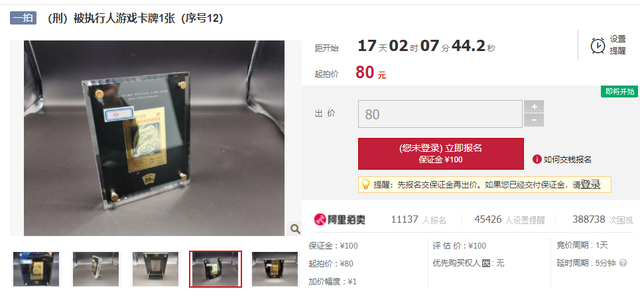
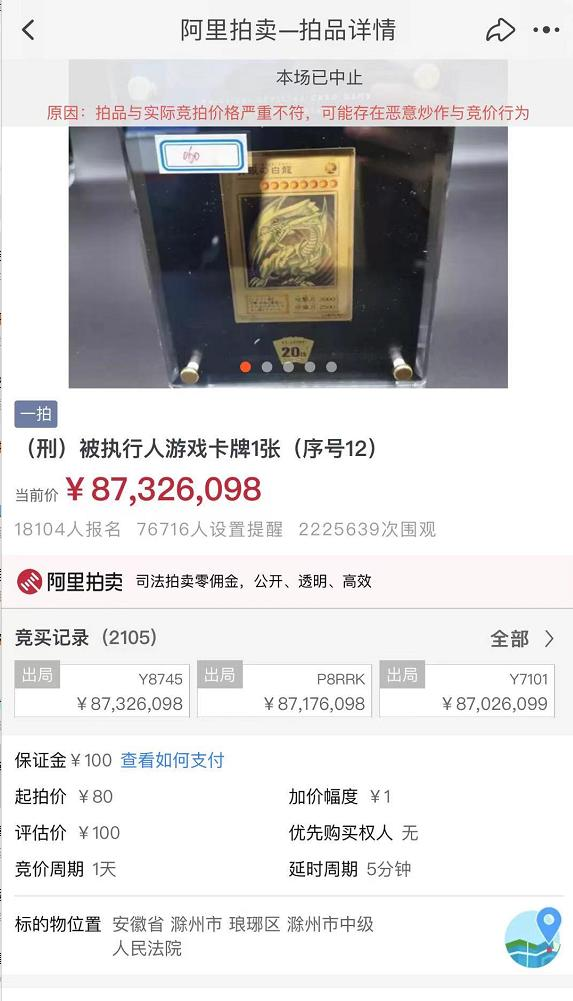
这款纯金的“青眼白龙”卡牌限量发售500套,官方定价为1万多人民币。
虽然这个次拍卖是被人恶意哄抬价格,但是根据近期日本拍卖网站的成交价格来看,这张卡的实际市场估值已经去到了20-30万人民币左右。
对此我们只能说:

与此同时,我们看到了这样一个抖音视频:
通过全息风扇玩游戏王,增强线下游戏的氛围感

小时候看游戏王的动画片,里面的角色对战的时候可以直接召唤到怪兽,出场还自带动画和BGM,而我们自己玩的时候,则是一堆冷冰冰的卡牌,想想真是太无趣了

所以我们决定做一个【现实版插件】——游戏王对战机!
通过屏幕效果的展示和一些辅助功能,增强线下卡牌对战的氛围感和体验 -
这个游戏王对战机会实现如下功能:
1.识别卡牌;
2.展示召唤效果——动画+光效+BGM;
3.修改攻击力/防御力
——这是线下对战中的一个痛点,因为在对战中经常有卡牌的效果影响怪兽的怪兽攻击力/防御力,比如场上有一只A怪兽的时候,B怪兽的攻击力会增加300点等以上功能需要两个显示屏幕实现,正好D1支持双屏异显,即同时接两个屏幕,分别输出不一样的内容,并且可以支持触控,这样看,我们的功能就都能在一块D1开发板上实现。
我们需要的硬件配置有:
D1哪吒开发板,MIPI屏幕+HDMI屏幕,USB摄像头,LED灯带做出来整个demo的硬件方案大概就是这样的:
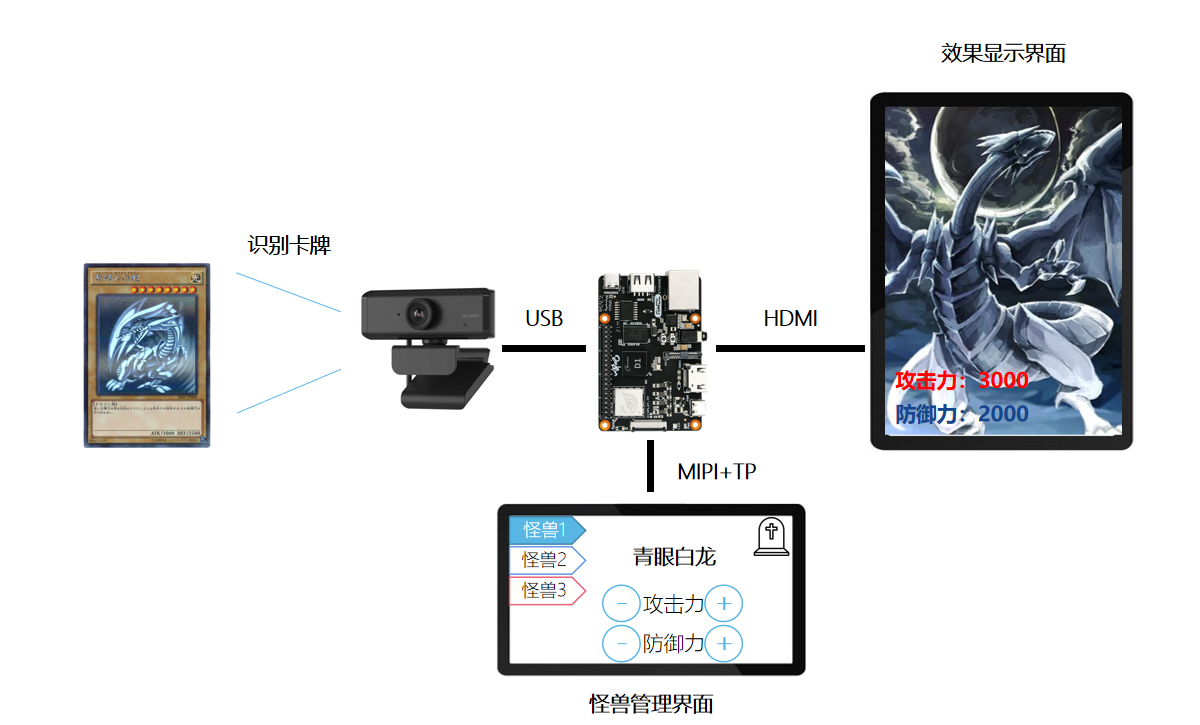
-
进展更新:
通过妥协视频改用照片使用按键拍照得到照片,然后使用LabelImg进行数据标注。(吐槽一下数据标注真的难受 )。
)。标注了10类数据。
下面准备模型训练
关于YOLOV5 框架的使用,准备单独做一节记录吧
-
历经七七四十九小时,九九八十一难,终于偷偷摸摸把模型训练好了
虽然有点夸张,但是还是磨人(这磨人数据标注and漫长的等待)
下面谈谈数据标注 和 模型训练
框架:YOLOV5 链接:https://github.com/ultralytics/yolov5
关于YOLOV5评估:https://zhuanlan.zhihu.com/p/172121380
对神经网络感兴可以详细看看第二篇文章评估,我们直接下载 yolov5 git仓库。
同时参考README文档说明,搭建好YOLOV5环境,个人推荐使用Python虚拟环境(Python版本3.8以上)
如果需要GPU请自行安装CUDA > 10.1 版本Pytorch。(我没有用 )
我用的CPU来训练的(没有钱)
好了不多BB(假装安装都没有问题)(其实我遇到挺多问题
 记录之)
记录之)- 编译安装Python 需要确认 本机是否已经 安装 bizp2 lzma 等软件包没有需要 apt 安装(一定要参考一下 网上的教程)具体细节我就不做展开了。(那是菜的扣jo)
- 要验证 bz2 lzma 这两个包确实是不是编译安装上了(在 make 最后会提示有些包没有安装。问题不大)
- 确认安装没有问题,再进行 pip3 install -r requirements.txt 安装环境需要的扩展包。
当安装过程一切顺利,都安装好后,针对我们标好的数据集去做一些label的调整和修改。使用两个生成脚本。
voc_lable.py split_train_cal.py
通过这两个脚本调整数据集label 和 训练所需参数位置。
---- 然后就是一些网上教程的东西了。附上链接:https://www.pythonf.cn/read/161104
很详细。
最后我们就开始训练:
python train.py --cfg models/yolov5s.yaml --device "cpu"
150 epochs completed in 32.378 hours. Optimizer stripped from runs\train\exp2\weights\last.pt, 14.4MB Optimizer stripped from runs\train\exp2\weights\best.pt, 14.4MB哈哈哈,我用自己电脑跑了 32 个 小时。 可以看一下训练记录。
这是分类框准确度
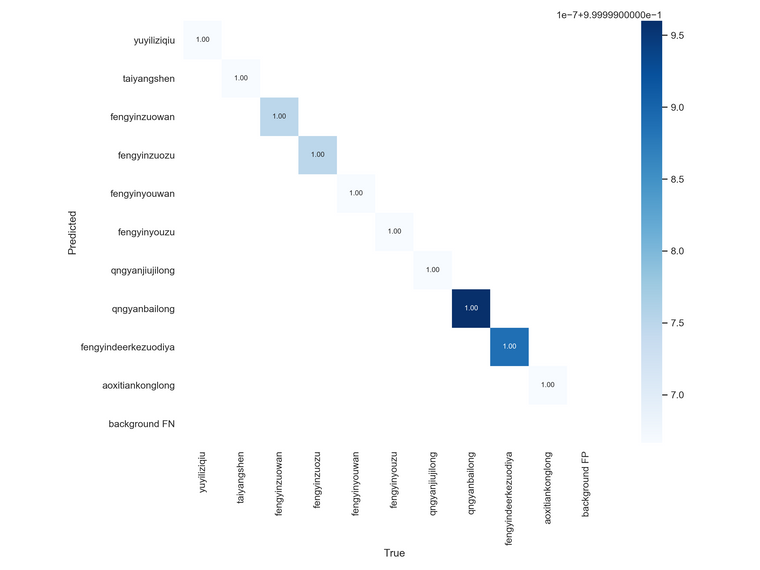
参数递归下降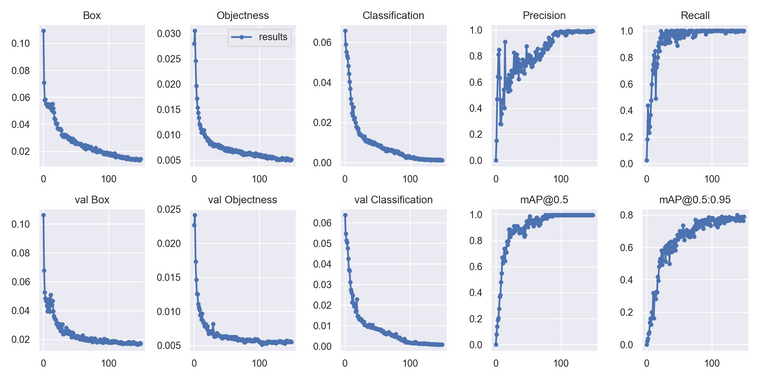
分类聚类
然后就可以愉快的测试啦。
验证完毕,整理一下开始下一步啦。
-
今天模型转换真的是踩了一天。。。。。。。。。。。

最最最最最最最最奇妙的是 转化过程中失败没有报错误提示,使用网络可视化工具依然能打开,而且能看到输入输出。!!!!!
然后就是 只能成功半拉 从网上找了各种方法来试试,降torch版本,降coremltools和onnx版本,中间又出现了numpy版本冲突。。。。等问题。
下面贴出来。。。
最后选择使用 torch 1.6.0 加 yolo v5 3.0 转化成功!!!!(午夜12点)明天再说
-
我有个想法, 想做个VR级别的射击游戏.
-
@aldfaaa 有想法就冲!
-
先谈一下模型部署的流程——今天结合网上流程梳理了一下接接下来的步骤:
首先是模型转换流程
pt -> onnx -> ncnn 。模型转换需要使用onnx作为中间件来转换。 ncnn 作者 nihui 也提供了一个ncnn 的 yolov5 的转换过程,由于我本人对于神经网络的了解也不是很足,所以在对模型的改造上看起来十分的吃力,但我目前正在一步步理解,或者说解决 正在出现的错误。
ncnn 的编译环境 nihui 已经在其文章中说明,可以使用c906 工具链编译ncnn ,同时在Linux 中的编译及ncnn 工具的编译,在另一个帖子中。https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-linux
需要 同时搭建使用 protobuf 否则 tools 中的工具不能加入编译使用。
开发过程
大概看了一下,需要些自己的程序读入模型,然后在程序中进行处理。ncnn使用的编译方式为cmake。
在yoloV5 github 的最新版本中,默认没有模型转换的工具。如果使用曾经的版本的模型转换工具就会出现错误且不报具体的错误是什么。
Converting Frontend ==> MIL Ops: 87%|████████████████████████████████████████████████████▎ | 603/691 [00:00<00:00, 1492.99 ops/s] CoreML export failure:就是这样。我看 CoreML 错误在 Github 上找了许久的问题。我是用的都是最新的python 第三方库尝试过的解决方法有:
-
GitHub上有降低torch版本可以解决的先例。
尝试过安装 annaconda 从而安装 torch1.6 然后 把所依赖的其他版本的第三方库都进行了降级。中间出现了多次第三方包冲突的问题。成功解决后。。。将本来不报错的转换,改成了有报错。 -
然后又解决报错问题,直到后面,,错误又是版本太低!。。。
直到晚上,我将环境版本不停的切换,然后就发现自己在套娃,我就看看别人是怎么出现这些问题的,为什么又能直接成功。才回想起我下载的yolov5 在 github上直接克隆的不是relase 版本,原本clone 的就没有官方的模型转换工具,我是使用了旧的版本中的模型转换代码。
那我直接切换成旧的版本?最终我使用了 Relase 版本直接模型转换成功!!!!

-
-
模型部署!
模型转换成功后的下一步当然是要在哪吒上部署起来啦!

因为用的是哪吒,目前在哪吒上推理框架优化最好的当属使用上RVV特性的ncnn啦。关于ncnn的使用,转github:https://github.com/Tencent/ncnn
README文档中有编译及指北教程。细数一下踩过的坑:
- 模仿nihui进行yolov5的模型部署。转化的过程中出现,除输入节点出错以外的错误。
解决:使用使用onnxsim将模型进行简化就没有问题了。 - 因为使用yolo版本不同,所以和nihui的方法略有出入,主要是转换后的模型的表现不同。
解决:根据这个仓库方法:https://github.com/midasklr/yolov5ncnn
需要注意几点:文中主要列出和nihui的不同,真正的过程还是需要看:https://zhuanlan.zhihu.com/p/275989233?utm_source=qq
直接修改 param 文件。 - 将模型 push 到小机端运行发现推理报错。
Usage: ./yolov5 [imagepath] root@TinaLinux:~# ./yolov5 bus.jpg find_blob_index_by_name 781 failed Try ex.extract("output", out0); ex.extract("417", out1); ex.extract("437", out2); find_blob_index_by_name 801 failed Try ex.extract("output", out0); ex.extract("417", out1); ex.extract("437", out2);发现是输出节点和模型没有匹配上,打开param查看了一下,将example中输出节点,更改为模型输出节点编号即可。
- 程序正常运行后,推理依然没有输出。
发现是因为模型将输出大小写死了,将0=-1输出改为自动适应即可。
然后就可以看到推理结果
obgect size : 6 0 = 0.87957 at 54.80 395.07 170.30 x 483.04 0 = 0.87637 at 670.32 400.49 138.68 x 476.75 0 = 0.86621 at 220.33 408.09 125.97 x 452.91 5 = 0.78794 at 16.63 217.35 782.06 x 521.62 0 = 0.65959 at 0.25 552.21 76.04 x 333.33 10 = 0.29877 at 656.58 625.15 32.50 x 91.10 ▒(▒▒person 88.0%▒(▒▒person 87.6%▒(▒▒person 86.6%▒(▒▒bus 78.8%▒(▒▒person 66.0%▒(▒▒fire hydrant 29.9%注意事项:nihui将模型修改为fp16的格式,可以缩小模型的体积。但我不知道对推理有没有什么影响。
其他:目前推理的速度还是比较慢,整个程序运行的结果在10s左右。

以上用的都是ncnn中的sample直接进行的修改。下面自己构建编译脚本(目前还是比较疑惑)
在github上nihui发了一个部署在自己的项目中的方案:使用cmake和动态库的方案。
我找了一下,没有像windows一样的动态库的方案,在我编译出install目录,有一个ncnn.o的静态库。
最开始使用 cmake 来包含头文件和静态库的方法,编译的过程中出现了函数找不到的问题。
然后使用命令包含头文件和静态库的方式,编译也出现了找不到的问题。
这个问题目前没有解决。
但是使用构建脚本中cmake 方案包含两个路径给变量即可。(这个方法有点懵,并不是很懂包含一个路径给变量的作用,但是这个方法没有问题,可以成功编译出来)下面构建项目有两种方案:
一、解决编译时静态链接找不到函数的问题。
二、搞懂cmake在包含过程中的关系,并能够使用cmake来构建项目。(感觉这个比较难)在使用cmake构建整个项目的过程中,因为目前需要显示的框架,LVGL目前使用makefile来构建,且makefile使用自动推断,目前没有修改的切入点,cmake构建也要重新将这些加进来(也不是很会)。-————所以:一个一个啃,两个我都要!


- 模仿nihui进行yolov5的模型部署。转化的过程中出现,除输入节点出错以外的错误。
-
从上次模型部署到现在已经经过了一周的时间,这一周呢完成了显示demo的移植。使用开源的LVGL显示框架进行显示界面的开发。关于LVGL官方已经推出到了第8个版本,并且官方开发了相关的不同设备之间移植的驱动、显示例程example。见下链接:
LVGL: https://github.com/lvgl/lvgl
LVGL_DEMO: https://github.com/lvgl/lv_demos
LVGL_Device: https://github.com/lvgl/lv_drivers
这三个包缺一不可!!!具体的移植呢也是参考韦东山老师的教程:http://lvgl.100ask.net/7.11/documentation/01_intro/intro.html
该教程是基于LCGL7.11,所以LVGL8还需要参考官方文档,鉴于目前是处于便开发边学习阶段,遇到问题需要从网上寻找解决方案,所以选择已经有相关介绍的7.11版本。关于移植,直接参考文档即可,说一些需要注意的:哪吒屏幕分辨率为 800*1280 。默认的SDK中哪吒的触摸屏幕的Y方向是相反的。需要在dts(目录:/d1-tina-open/lichee/linux-5.4)中更改两处:# 1、使能触摸 compatible = "allwinner,goodix"; device_type = "ctp"; reg = <0x14>; - status = "disabled"; + status = "okay"; 2、更改触摸方向 - ctp_revert_y_flag = <0x0>; + ctp_revert_y_flag = <0x1>; ctp_exchange_x_y_flag = <0x0>; ctp_int_port = <&pio PG 14 GPIO_ACTIVE_HIGH>; ctp_wakeup = <&pio PG 15 GPIO_ACTIVE_HIGH>;更改了上述文件此时屏幕就可以在哪吒上正常驱动了!

然后就是LVGL的官方移植了。需要注意更改编译之前的相关设置。。。细节就不过多站看,有问题可以评论一起交流哈。

当能够编译出来LVGL项目,之前ncnn项目是由cmake构建的。所以此时LVGL也需要使用Cmake来进行构建,那么两个demo才能整合到一起。来进行编译。
使用cmake构建项目由于个人比较生疏,所以学了许久。
解决了很多关于对插件的依赖和寻找,包含,编译相关的问题。 最开始使用 sunxi的fd驱动可以使用硬件刷新,屏幕的显示效果比较好。但是由于使用cmake 的过程中,无论如何也在链接的过程中找不到libuapi.so这个动态库文件,使用了手动链接,动态查找等 方法都不可以,直接使用-L 也不可以。编译不出来不能使用动态库(目前仍没有解决!! )
)因为不能使用这个,所以就只能使用官方的fddev,使用软件的刷新效率没有使用sunxi的块,但是仍然希望能够解决这个问题(*)
—————————————————————————————————————————
尝试过程:
1、包含头文件,添加动态库:
include_directories(/home/gaojies/workspace/d1-tina-open/out/d1-nezha/compile_dir/target/libuapi/ipkg-install/usr/include)
FIND_LIBRARY(RUNTIME_LIB uapi /home/gaojies/workspace/d1-tina-open/out/d1-nezha/compile_dir/target/libuapi/ipkg-install/usr/lib NO_DEFAULT_PATH)
2、 直接添加
link_libraries("/home/gaojies/workspace/d1-tina-open/out/d1-nezha//compile_dir/target/libuapi/src/libuapi.so")
link_directories("/home/gaojies/workspace/d1-tina-open/out/d1-nezha//compile_dir/target/libuapi/src/")
————————————————————————————————————————CMake构建过程注意:
- 相关的库文件需要依赖,直接模仿ncnn中写一个编译链rootfs的配置文件,在Cmake 中进行依赖。
- 头文件的包含过程。使用递归调用函数,将文件夹下所能发现的所有头文件全部包含进来,确保不会出现函数未定义错误。(函数见下:)
- 在添加源文件的时候要明白源文件的添加方法及规则。可以多次添加,但添加顺序要注意且不能嵌套!!!!
# 最开始将 源文件都添加到LVGL_SOURCES 中,发现LVGL_SOURCES 会被覆盖不会编译新添加的文件,所以就只能添加了一个变量来添加进来。 file(GLOB_RECURSE LVGL_SOURCES lvgl/src/*.c) file(GLOB_RECURSE LVGL_EXP_SOURCES2 lvgl/examples/*.c) file(GLOB LV_DRV_SOURCES lv_drivers/*.c lv_drivers/indev/*.c lv_drivers/gtkdrv/*.c lv_drivers/display/*.c ) # 但是后面的同一个变量又可以添加多次,且都能添加链接进来,这块不知道为什么(懂得dalao可以评论回复一下) file(GLOB_RECURSE LV_EXP_SOURCES lvgl/examples/*c) # file(GLOB_RECURSE LV_EXP_SOURCES lvgl/example/*c) file(GLOB_RECURSE LV_EXP_SOURCES lv_demos/src/*.c)确认自己的文件夹及文件全部添加完毕,就可以使用如下指令来进行编译了
export RISCV_ROOT_PATH=/home/nihui/osd/riscv64-linux-x86_64-20210512 cmake -DCMAKE_TOOLCHAIN_FILE=../toolchains/c906.toolchain.cmake ..如果添加没问题,那编译应该也没问题
如果能成功编译出来,那就可以放板子运行了,贴个图......

不足:
使用riscv最新的编译链和Tina 中的编译链编译demo会产生明显的 效率下降,专门开了一个帖子来讨论:https://bbs.aw-ol.com/topic/261/关于哪吒不同版本编译链的问题下一步:
LVGL(此插件中进行开发和使用了)
准备先使用小插件构建一个 app 列在显示器上,可以通过打开app来进行打开软件.
Cmake构建综合程序,LVGL的综合程序也没有使用Cmake 来进行构建 -
项目很有技术含量 想法很有意思 坐等更新

-
阅读了两天源码,加上参考LVGL手册,基本上搞明白了LVGL运行的机制和对象创建的方法,一些高级的控件目前还需要继续学习,由于我直接移植了100ask的应用程序综合例程,由于源码量比较多,不过还好,韦老师的代码 写的调理都比较清楚,容易找到代码对应的位置。
进入所有初始化后,进入函数:lv_100ask_printer()。
模仿该函数的写法,在下面添加了,我们自己的app和对应回调函数。
- 移植的过程中底部应用栏的位置不对,主要是原来的 屏幕偏移量和现在的屏幕偏移量不是匹配上的,通过调整偏移量可以达到完美显示桌面的效果。
- 同时连接网络,可以使用ntp服务器更新系统时间。桌面时间更新也会正确。
以上两个更改完成后此时的桌面如下:

然后,模模仿其app写法增加我自己的app。(目前没有构建好,比较丑)
但是app 的启动及退出的接口已经准备好了。app 内容正在构建(LVGL控件还不是很熟悉)
预计app具有如下内容。- 卡牌信息及其展示
- 识别的提示
- 卡牌属性展示及调整
- 动画解码播放(盲区)
目前测试卡牌识别情况来开,使用ncnn加速的的模型识别,一帧需要 10s 左右,所以做到实时识别是不太可能的。所以又三种方案(我觉得)
- 手动识别 按下按键进行识别
- 自动感应识别
- 全自动识别
本着好实现的原则,个人觉得第一种 比较好实现。大概的实现路径:
- 读取摄像头数据,手动拿取一帧,做识别
- 在界面上显示 卡牌的信息
- 并在屏幕中播放视频动画
上面说过需要使用cmake来构建项目,在cmake构建的过程中遇到的问题:
- sunxifb.c 没有找到(加速 后面优化的过程中再尝试)
- lib_png 库,添加一个新的变量包含这个库
- 运行时cpu段错误
开启了编译优化,使用和ncnn 同样的参数出现了这个问题,这个结果是不是注定了我不能把ncnn也一起编译进来?????????????
将优化去掉,删掉其他对应的库,可以运行了 - 自己写的界面刷不出来
发现在这个工程中,自己写的界面需要通过,lv_scr_act()获取当前显示界面,显示在当前页面中,否则就会被,其背景冲掉,而且需要关掉主界面的刷新。才能显示出来。 - 自己的回调函数不能使用
回调函数需要在前面进行注册,位置不对也不能用(我也不知道为什么)
-
大佬, 666呀
-
更新一下自己的app开发进展,由于LVGL框架的特殊性,图片的显示需要使用二进制文件的形式。先这里感谢百度词条收录的卡牌图片,让我能再网上直接下载到的卡牌的原图!
先上一张草图。。。(很草 勿怪
 )
)
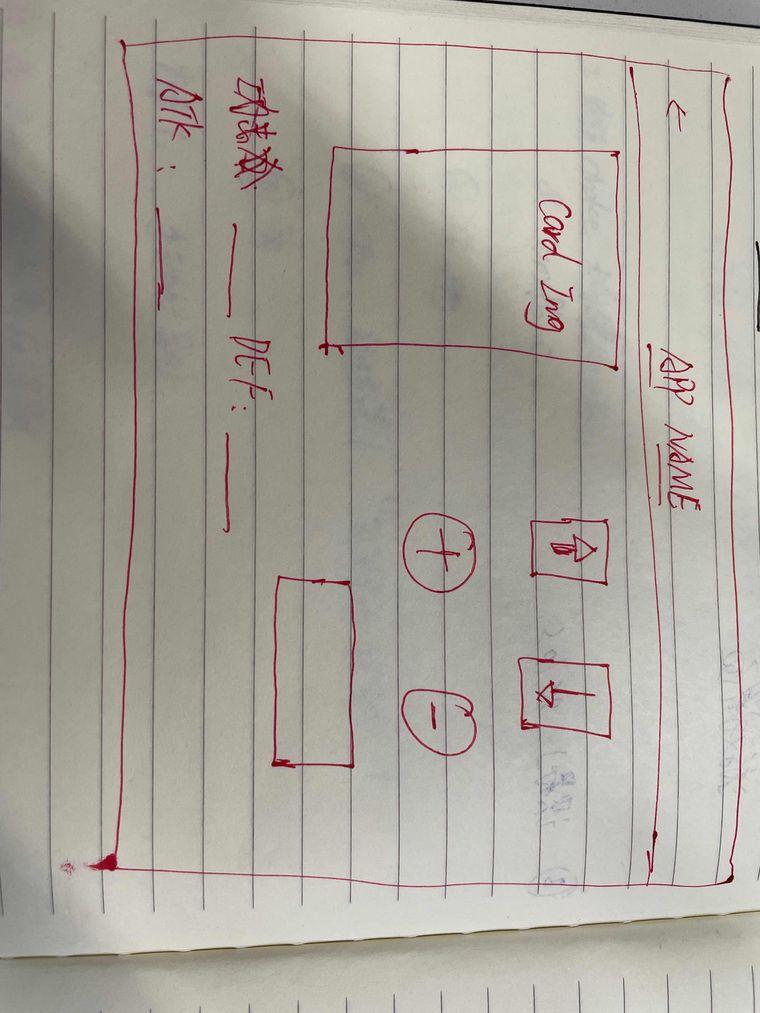
然后就是基本的 资源绘制了。。。。
使用图片在线转换工具:https://lvgl.io/tools/imageconverter
可以将图片转换为一个 .c 文件。在转换之前,需要将所有图片统一成一个大小。我使用windows 自带的 画图工具,取消比例绑定,将所有图片调整为 383*561 (因为我第一张图没处理,索性后面都按照这个比例的格式了)转换得到的C文件有点大,一个C文件为 11M大小 3K行的数组!着实吓了一跳!同时我的电脑不是很给力,修改这个文件难上加难,使用Windows 自带的记事本来修改! 打开 修改 保存 每次都需要花费20S,然后将文件加入文件夹包含LVGL头文件,因为只有这样使用宏才能找得到改图片数组!。
然后再将所有的图片通过加入数组的方法来索引,加上回调机制,再加一点细节,就得到了如下效果:
下一步就是:
- 调用ncnn 根据返回结果绑定 图片 就可以成功识别到了(仍然使用索引的方式)
- 利用索引查找,攻击力 生命值等属性 显示再屏幕上。
- 下一步播放动画(盲区)
- 还要先驱动HDMI 好像。。
-
@bedrock 视频不知道为什么上传后亮度看不清楚了。。。。

-
分享到游戏王群里,群友回复说:

*海马就是动画片里真正使用青眼白龙的角色 -
从网上找了两个箭头的Logo做按键,下载时还要收费,然后认证了一个企业号,下载了两个
 箭头。。。。哈哈哈
箭头。。。。哈哈哈
LVGL的img 无法直接应用 回调函数,需要使能 图片的 可以按下的属性,就能进行回调了
#define LV_EVENT_CB_DECLARE(name) static void name(lv_obj_t * obj, lv_event_t e)还有这个宏将回调的参数取消了,仅仅只用通过判断e的枚举,就可以确定当前控件的状态。
这个问题解决后,然后就开始考虑 LVGL 如何掉起 ncnn ,最开始想直接,使用system 函数 运行一个进程 就结束了,但是这样两个执行之间没有通讯的方法,然后搜索找到
popen函数可以将执行后的结果返回一个文件指针,可以读取文件指针中的值来获取指令的返回值。但是这种应用一般用于shell指令的返回值,检测的过程中需要比较长的时间,此时结果读取就会被阻塞,界面就会被卡住。其实理论上在这里开一个线程,让这条线程专门等待结果即可,其图片的识别传递参数通过shell 脚本参数实现。个人觉得这个方法不是很行。今天尝试了多进程通讯,最开始是打算用管道,但是管道的特殊性为单向传输。所以两边传输需要两个管道。然后我在调试两个管道阻塞同步传输数据的时候比较困难,调试不出来。

然后就继续找了方法
所以就又调试了基于Socket的多进程控制程序,由于数据量只有img 路径的字符串,而Socket监听本事就采用阻塞的方式,所以实现起来比较方便。现在就成功实现了ncnn检测作为客户端,然后服务器做服务端,向客户端发送img路径进行识别。下一步就是整合。绑定结果。调试。

-
@bedrock 在 【持续更新】用D1哪吒开发板做一个卡牌识别机,可以玩游戏王、狼人杀、三国杀、剧本杀 中说:
这里开一个线程,让这条线程专门等待结果即可,其图片的
可以去阿里矢量图库下,免费,还能调颜色
https://www.iconfont.cn/search/index?searchType=icon&q=箭头
字节也有一个一样的矢量图库
https://iconpark.oceanengine.com/official
-
APP基本功能已经实现啦,在这里庆祝!加祝贺!加感谢 @xiaowenge 还有论坛各位大神的的鼎立相助。看看识别同时显示的效果。

识别和APP为不同进程,采用Socket通信,传递 img_Path 和 识别结果。
由于Socket本身机制的问题,在监听和write的过程中为阻塞进程的方式,所以CPU占用率也很低。在识别的过程中CPU 会跑满。识别时间约为 5-6s 钟,因为模型加载需要2-3s,所以之前的重复运行且加载的方式很不OK!
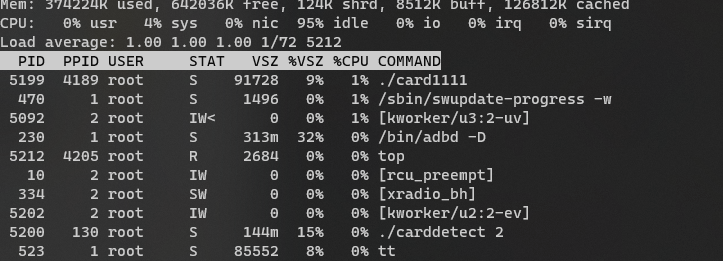
下面准备调试双屏显示。。。其他功能也在稳步完善中。。。。
上一个视频看看效果: -
强!这项目,我王多鱼投了!
-
此回复已被删除! -
Unpinned by System
-
Referenced by A A.I.Unicorn
-
Referenced by A A.I.Unicorn
Copyright © 2024 深圳全志在线有限公司 粤ICP备2021084185号 粤公网安备44030502007680号