看到一篇关于D1 RVV性能评测文,这性能什么水平?
-
转自嵌入式IoT公众号
https://mp.weixin.qq.com/s/N3bkMyJwc4HWI_M1DocghgD1 riscv芯片上运行rt-thread进行RVV性能评估
- 概述
- rt-thread在D1芯片上的移植
- 如何开启D1&&D1s的rvv扩展
- RVV性能对比评估
- RVV在RTOS如何使用的更好
概述
D1 && D1s(f133)采用的是平头哥C906的core,上面已经支持了RVV 0.7.1版本,虽然目前RVV1.0已经frozen,这就意味着上游编译器或者一些相关的生态软件将支持RVV1.0,但是作为性能评估RVV0.7.1与RVV1.0影响并不大。下面的文章主要描述如何在D1 && D1s芯片上运行rt-thread,并且描述如何开启RVV,同时对RVV性能进行一个简单的评估,最后讨论RVV如何与RTOS使用的问题。
rt-thread在D1芯片上的移植
目前D1s有64MB的内置DDR2,这非常适合运行RTOS,所以将rtos移植到D1s上是非常不错的选择。
其移植的细节不详细介绍,可以查看源代码
https://github.com/bigmagic123/d1-nezha-rtthread移植的难点在于:
1.启动,从芯片上电启动入口处跳转到rt-thread入口处的汇编代码
2.硬件串口的初始化,这里会涉及到时钟配置
3.tick时钟中断,目前采用的是riscv的通用timer,需要配置clic
4.任务切换和上下文的保存与恢复,这部分需要对入栈出栈的顺序十分的清晰
5.串口中断,这里需要弄清楚plic中断处理机制解决上述问题,移植rt-thread将非常的简单,当前的rt-thread运行在M-mode,具有比较高的权限,可以随意操作寄存器进行配置。
编译与运行在windows和Linux上均可操作,主要参考如下的文档:
https://github.com/bigmagic123/d1-nezha-rtthread/blob/main/README.md目前已经实现的功能有:
1.timer
2.uart
3.gpio
4.vector
5.FPU如何开启D1&&D1s的rvv扩展
想要使用RVV功能,需要开启VS标志位,该位位于
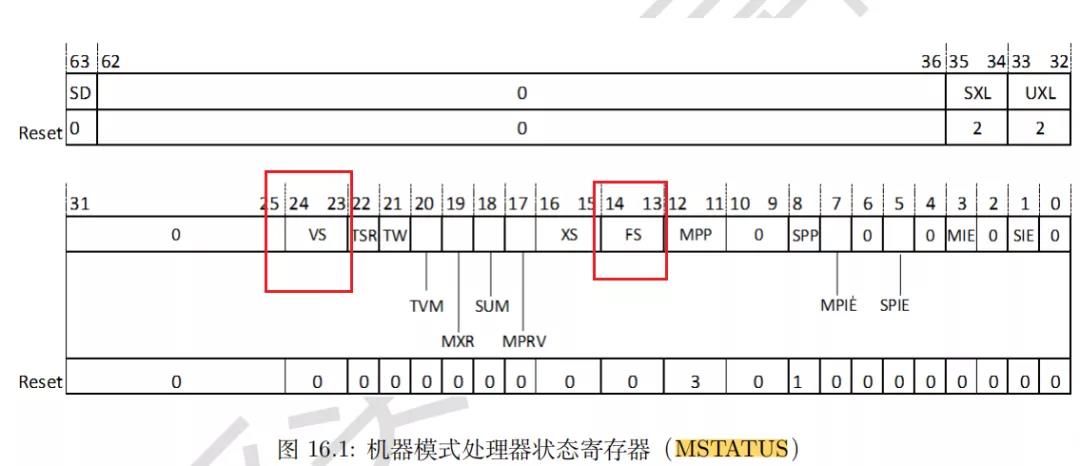
VS位于MSTATUS寄存器的23到24位。但是需要注意的是,当使用RVV时,需要开启浮点寄存器(FS),不然会报错。
这部分在rt-thread的体现是在上下文切换的时候,需要将使用RVV的线程的MSTATUS设置成开启VS的模式。

可以VS设置b01。
只有当使能该位,才能正常使用RVV指令,不然运行会直接报错。
接着,编译选项中还需要添加成如下选项
-march=rv64gcvxtheadc -mabi=lp64d -mtune=c906这样才能告诉编译器支持RVV指令。
RVV性能对比评估
riscv 的RVV其编程模型主要有两种方式,第一种采用rvv-intrinsic。这就是在编译器中进行intrinsic函数的构建,可以将相关的rvv操作变成编辑器的内置函数。采用类似下面的函数方式进行编程。
vint8mf8_t vcopy_v_i8mf8 (vint8mf8_t src); vint8mf4_t vcopy_v_i8mf4 (vint8mf4_t src); ...其操作详情可以参考:
https://github.com/riscv-non-isa/rvv-intrinsic-doc/本质上就是将复杂的汇编代码操作换成C语言函数的形式,这种方式可读性更强。rvv1.0后面也会提供这一种方式进行。
第二种就是采用汇编进行操作,裸写汇编代码的难度很大,但是可以实现比较好的优化,这特别是在关键耗时的操作上进行汇编级别的优化,可以很大程度上提升程序运行的性能。
在平头哥开源出来的GCC工具链中,并没有rvv-intrinsic功能,所以只能通过汇编函数的方式进行操作。
平头哥开源出来了一个神经网络的库,里面有C906的RVV底层操作。
https://github.com/T-head-Semi/csi-nn2实现了一些基本的操作,抽象了各种常用的网络层的接口,并且提供一系列已优化的二进制库。
其主要的使用类似于CMSIS,Tensorflow等等。有了这些抽象接口,在使用RVV进行特定优化的时候,难度也会有所降低。
下面主要从csi-nn2抽取出vertor add, vertor mul,memcpy,也就是加法计算,乘法计算和内存拷贝,三个方面,对其性能进行评估。
https://github.com/bigmagic123/d1-nezha-rtthread/blob/main/bsp/d1-nezha/applications/vector.c浮点数加法
采用向量操作
float a[10] = {1.2,1.3,1.4,1.5,1.6,1.7,1.8,2.0,2.1,2.2}; float b[10] = {1.2,1.3,1.4,1.5,1.6,1.7,1.8,2.0,2.1,2.2}; float c[10]; element_mul_f32(a, b, c, 10);一次性处理10个元素,采用RVV向量的操作。
普通的加法
for(ii = 0; ii < 10; ii++) { d[ii] = a[ii] + b[ii]; }单个元素相加。
分别计算30000次。
最后的结果如下:
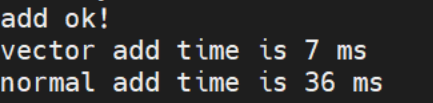
采用向量加法只需要7ms,而直接相加,则消耗了36ms,性能相差5倍左右。
浮点数相乘
与加法操作类似,也是一次性处理10个元素
float a[10] = {1.2,1.3,1.4,1.5,1.6,1.7,1.8,2.0,2.1,2.2}; float b[10] = {1.2,1.3,1.4,1.5,1.6,1.7,1.8,2.0,2.1,2.2}; float c[10]; element_mul_f32(a, b, c, 10);普通的乘法
for(ii = 0; ii < 10; ii++) { d[ii] = a[ii] * b[ii]; }两者性能对比
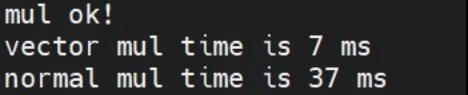
向量乘法也比普通的乘法性能强大一些,接近5倍的差别。内存拷贝
内存拷贝的测试方法是测试rt_memcpy,memcpy,csi_c906_memcpy。分别代表rt-thread内置的内存拷贝函数,采用C语言进行实现,memcpy是newlib库函数的实现,里面会对riscv架构进行优化处理,csi_c906_memcpy则是采用向量操作,进行内存拷贝。
测试是先申请1MB的目标内存,1MB的源内存,往源内存中写随机数。
拷贝源内存中的数据到目标内存,拷贝100次,也就是100M的内存拷贝数据量。
结果如下:

显然,内存拷贝操作newlib中的memcpy性能是最佳的,而向量操作的memcpy反而其次,最差的是rt-thread的rt_memcpy。这里的原因是newlib的memcpy的是经过优化后的,而vector memcpy也可能是优化的不好导致性能与newlib的memcpy相当。rt-thread采用纯C语言实现,其通用性比较好,但是性能不佳。
RVV在RTOS如何使用的更好
这是一个关于更好的在RTOS上使用RVV的问题,由于RTOS是为了追求实时性,一般来说,开启了FPU和RVV后,其寄存器的数量会非常的多,每次入栈和出栈的操作,如果每次都将全部的寄存器压入和弹出,将会让切换任务的时间变长,影响了系统的实时性。对于这种情况,其实可以利用mstatus中的VS和FS的标志位进行判断。


在切换任务时,可以通过这些标识,选择是否压栈和出栈,这样保证了一部分性能实时性的情况下,也可以很好的处理FPU和RVV。
-
Referenced by
 q1215200171
q1215200171 -
Referenced by q1215200171
Copyright © 2024 深圳全志在线有限公司 粤ICP备2021084185号 粤公网安备44030502007680号