大佬们,我又来求助了。
主要有三个问题:
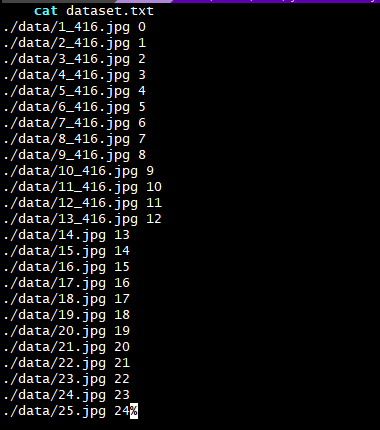
1.yolov3转化模型时量化未使用全部data图片
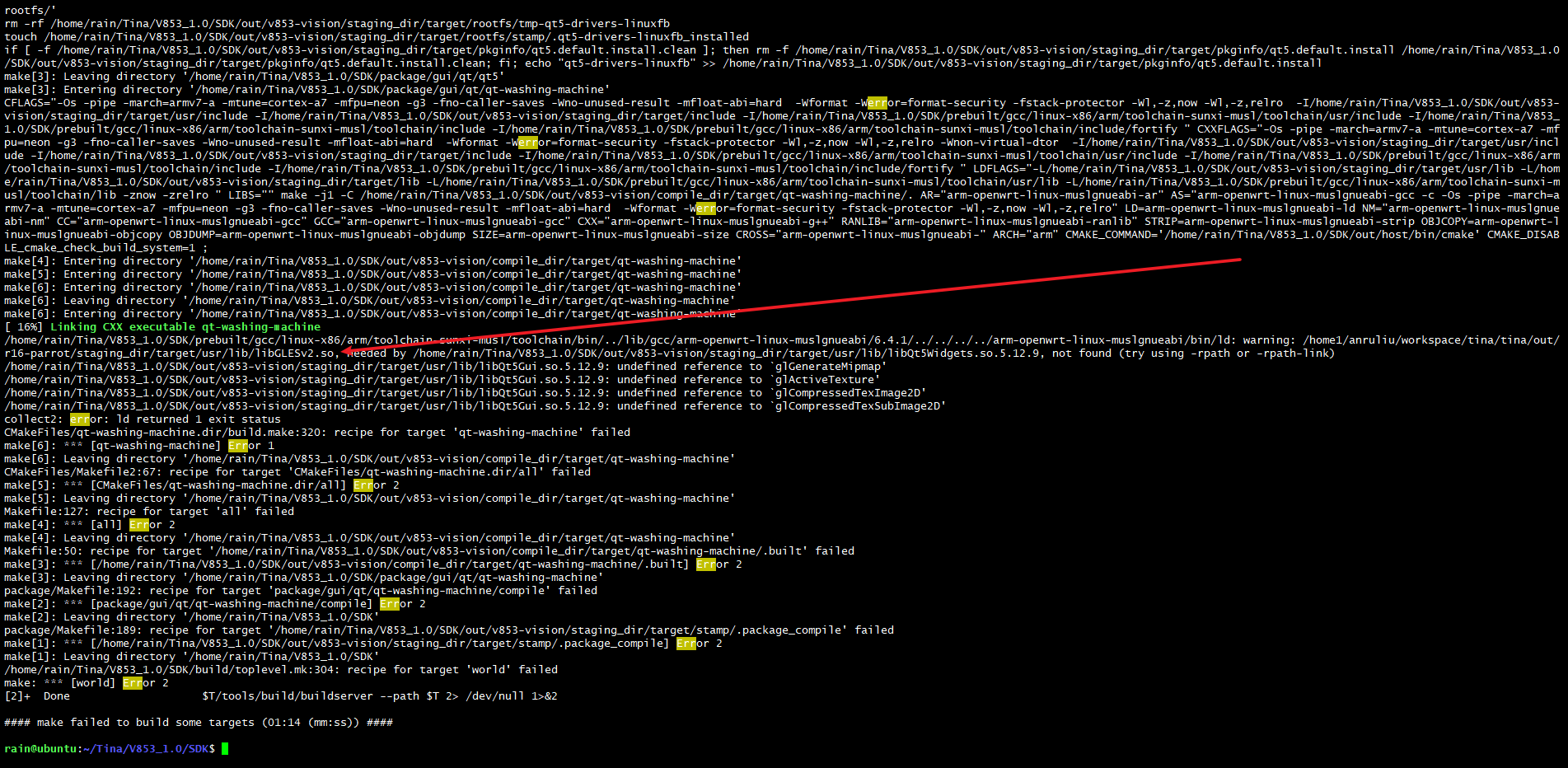
过程是这样的,在用 sample_odet_demo 使用自己训练模型后,同样的模型对比海思平台,实际检测效果不是特别好。检查了下过程,发现量化时 不管放了多少张图片,但实际只使用了一张图片。怀疑是这里影响了检测效果?
验证1如下:
在2个文件夹文件内容完全一样的基础上,第二个文件夹将 2_416.jpg 图片删掉,dataset.txt 不修改 依然包含此图片。
 :
:
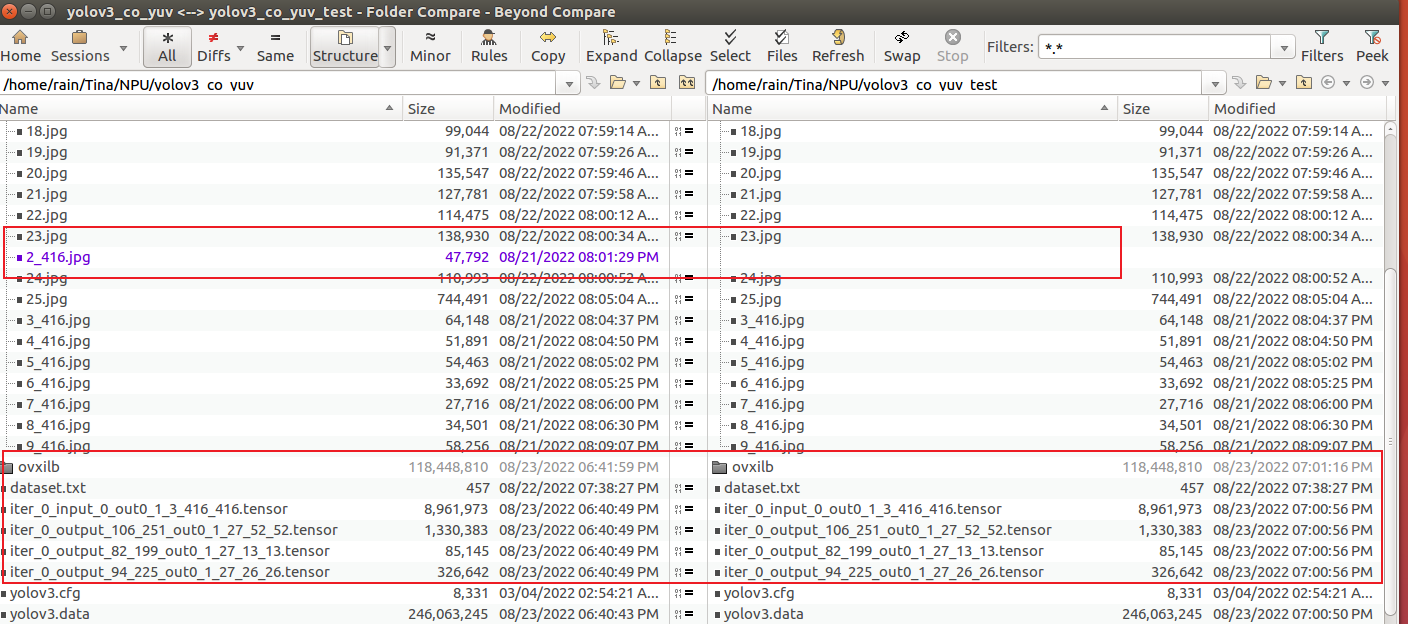
在同样步骤转换后,对比两个文件夹内容发现:少了一张图片的文件夹模型转换过程中 没有报错,此外输入输出Tensor 一模一样,以及 ovxilb/yolov3_nbg_unify/network_binary.nb 都一样。
验证2如下:
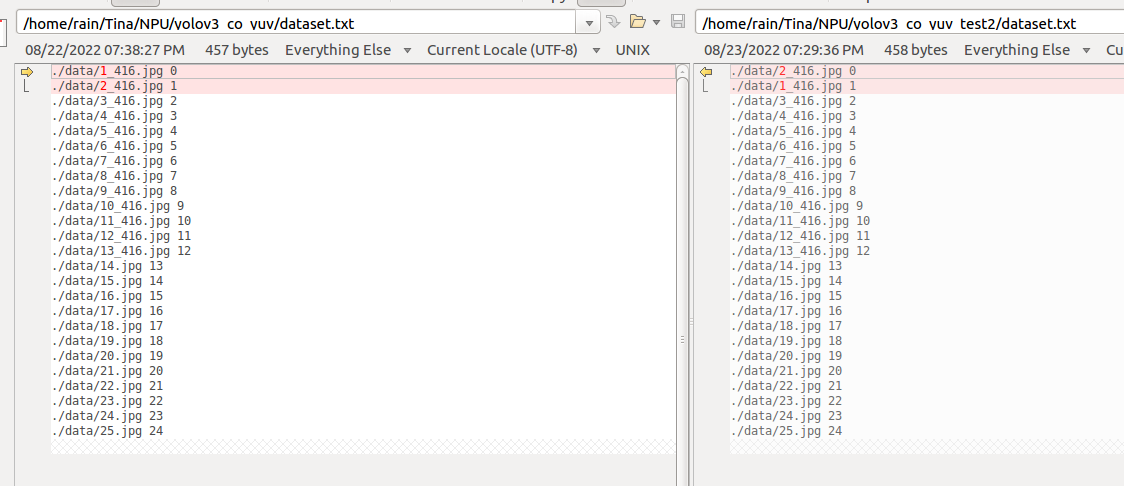
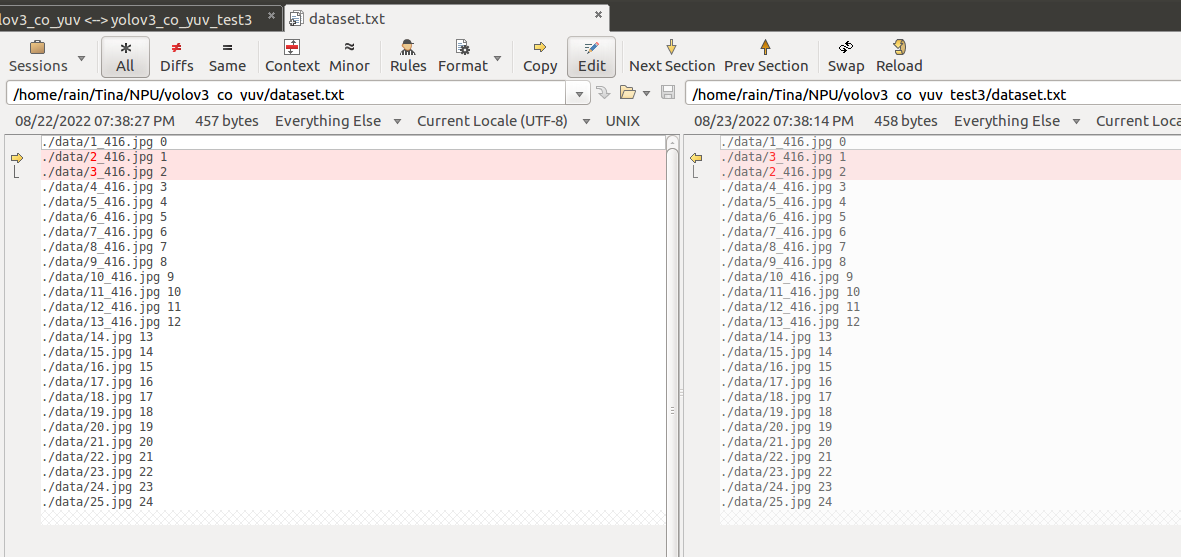
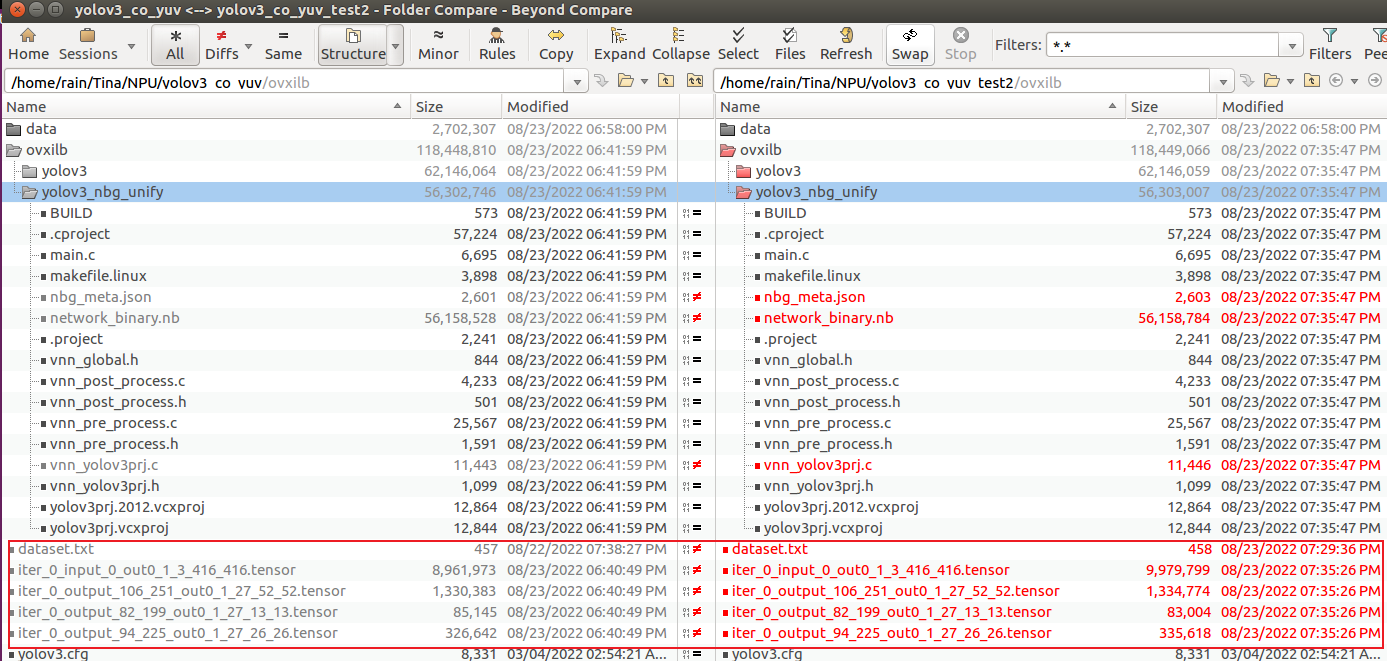
在3个文件夹文件内容完全一样的基础上,修改 ②号文件夹 dataset.txt 将第二行与第一行交换, 修改 ③号文件夹 将第三行与第二行交换。
① ②对比
① ③ 对比
转换后:
① ②对比
① ③ 对比
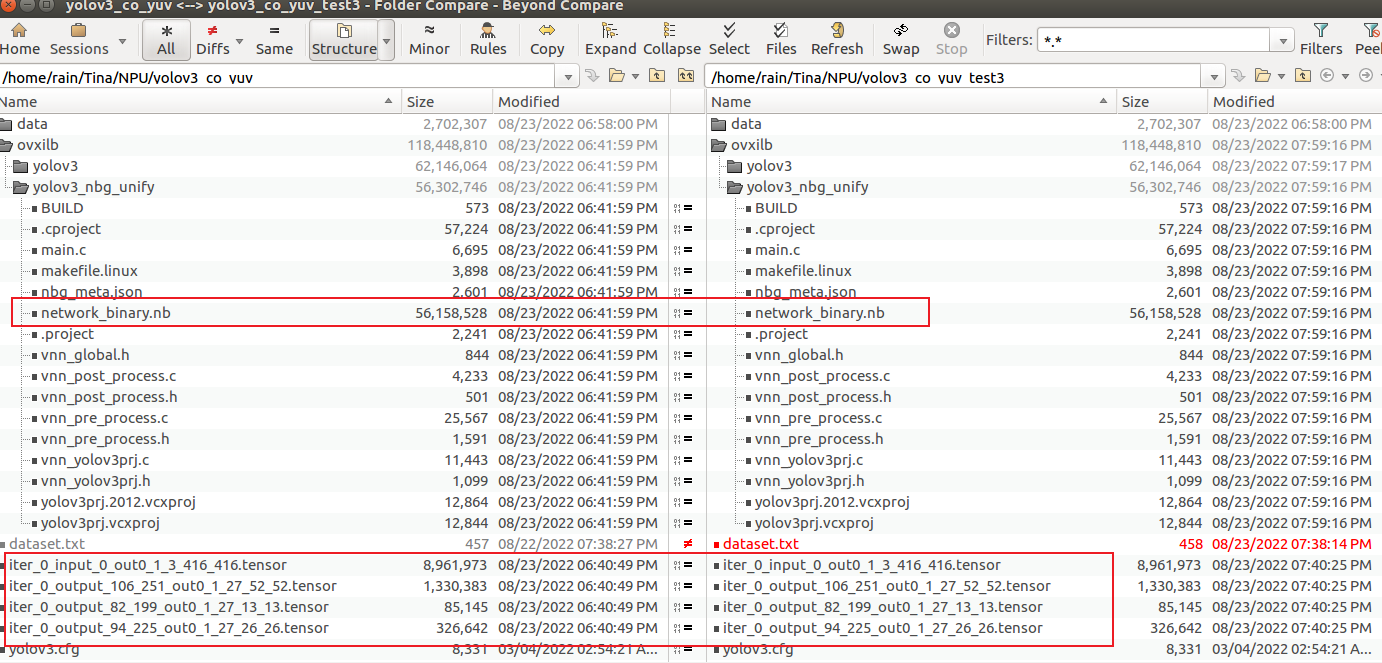
这里发现,①② tensor 以及 nbg 有明显差异,①③tensor 以及 nbg 相同,故怀疑量化时 只使用了第一张图片。这是为什么呢?
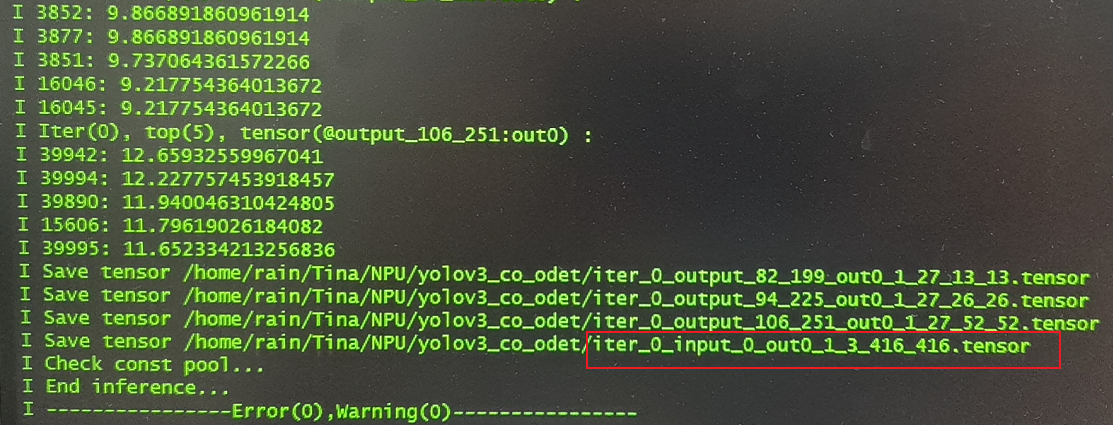
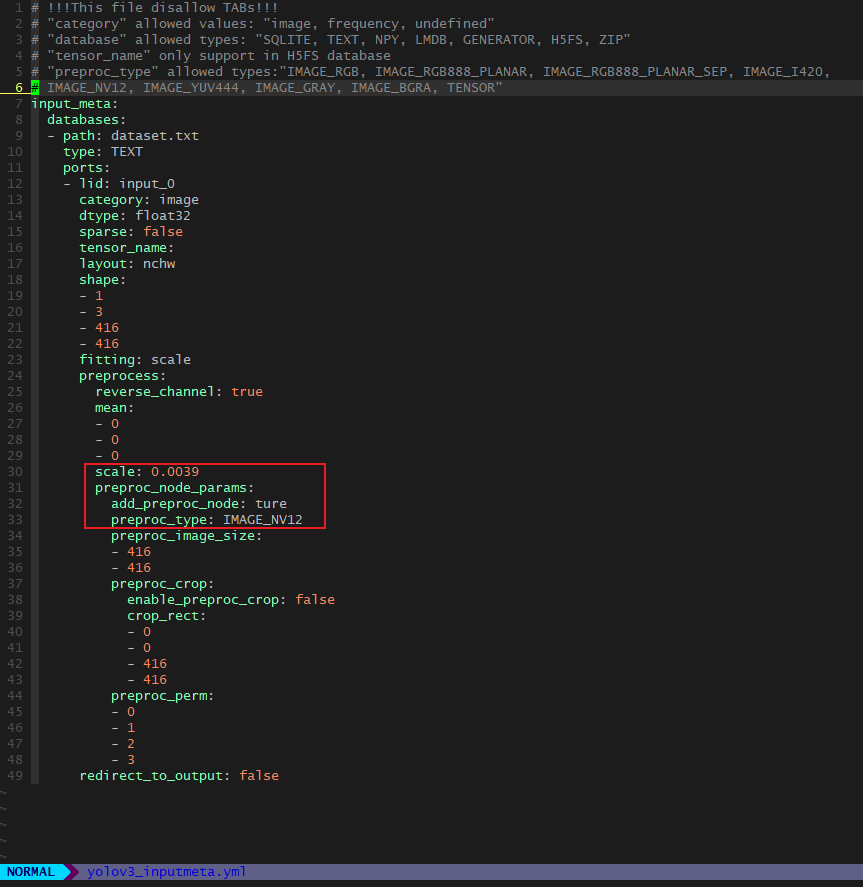
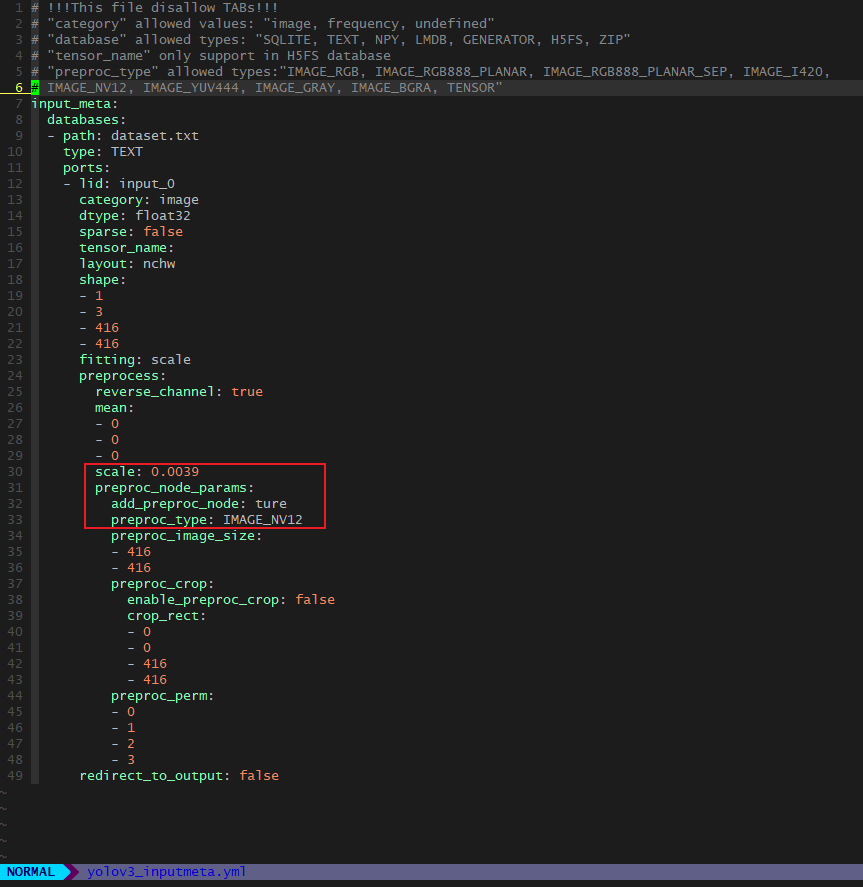
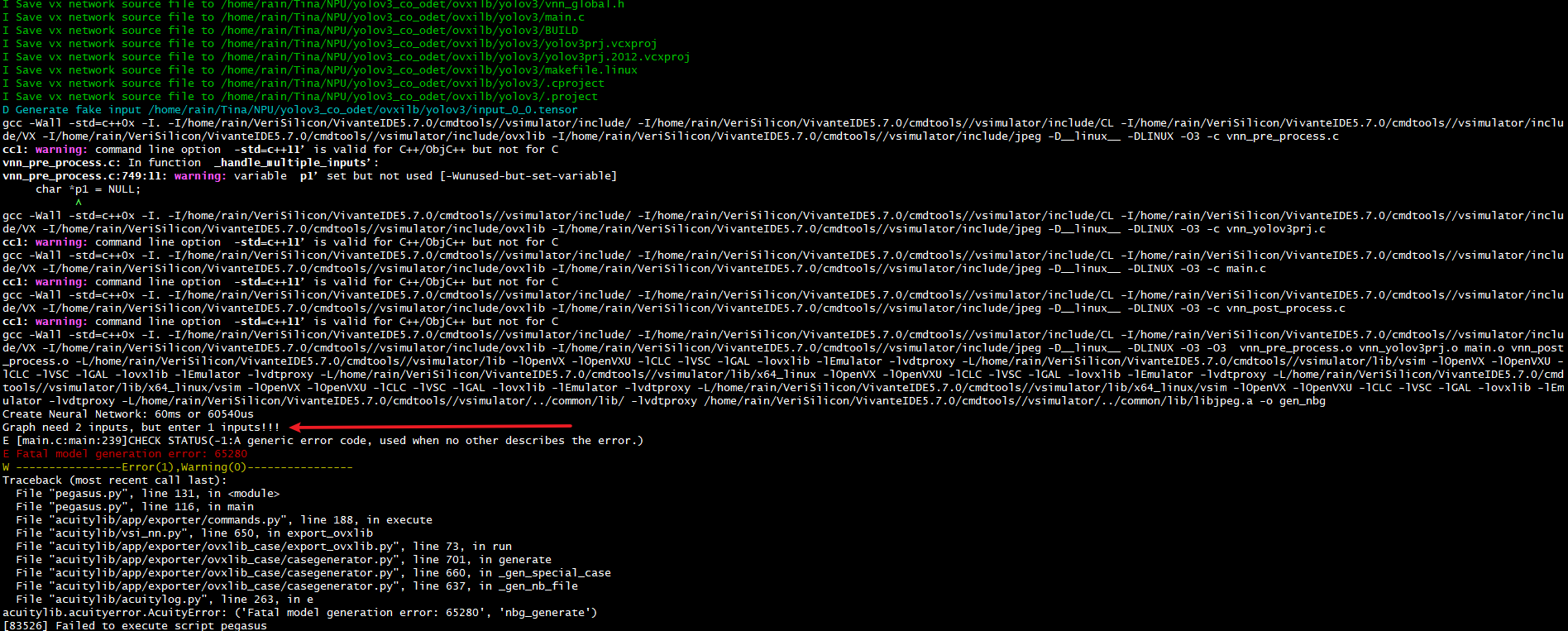
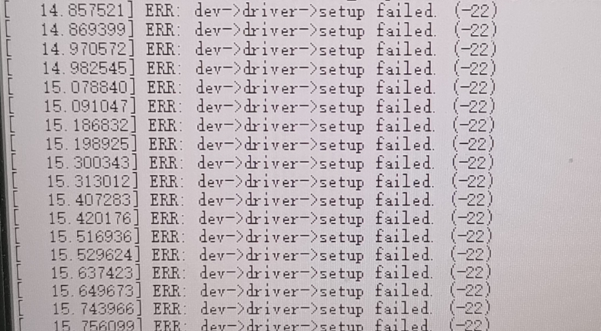
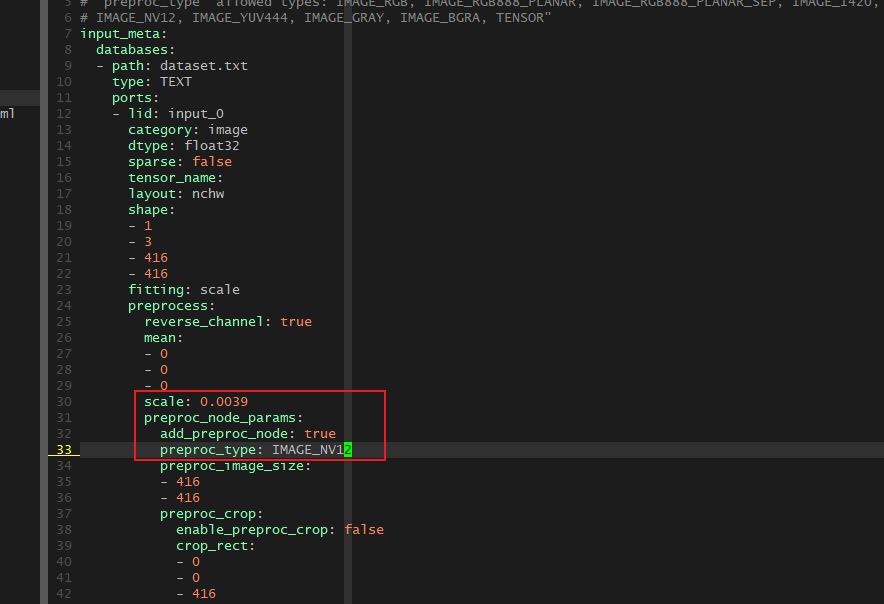
2.转化模型时候,中间在 量化 /预推理 有这个输出log,是否有影响或有问题?
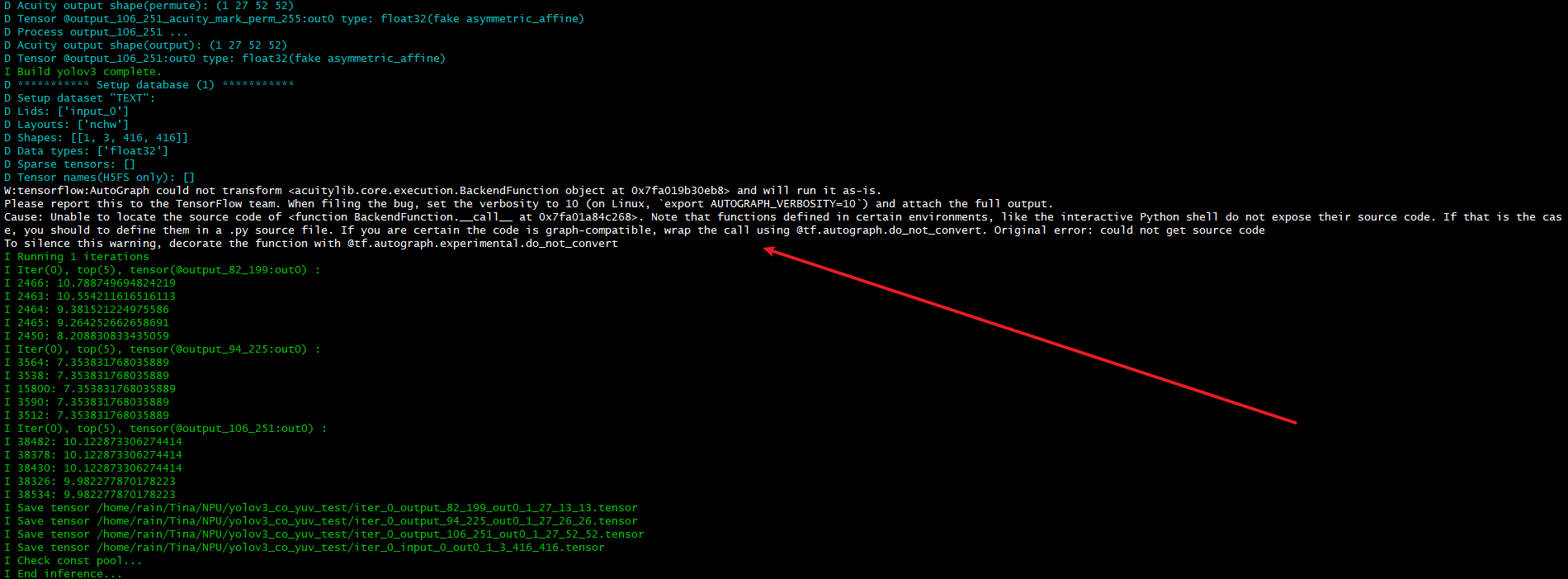
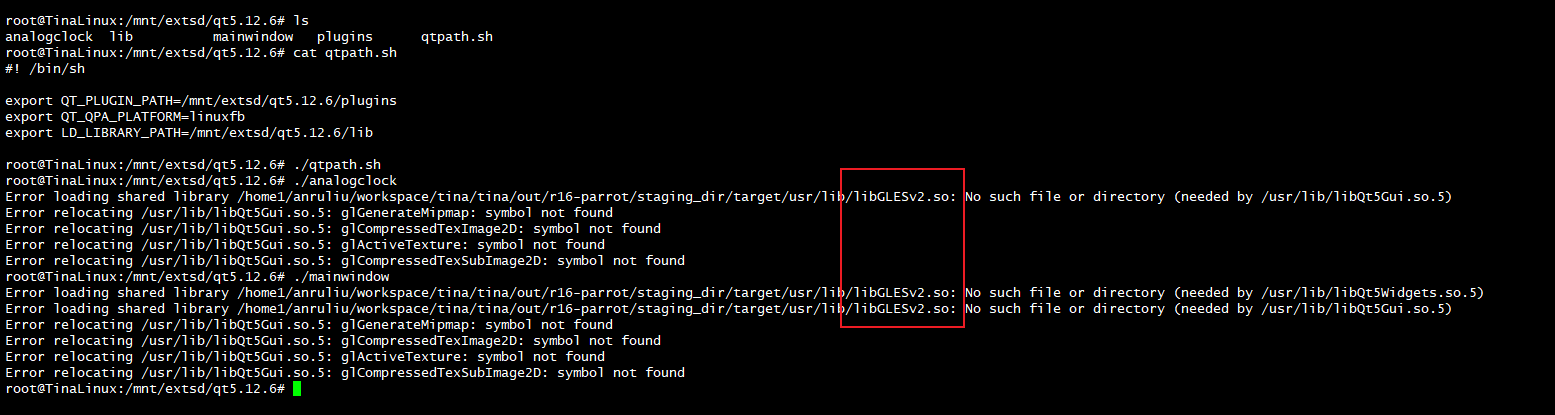
3. 使用sample_odet_demo 使用自己训练转化的yolov3模型,图像实时显示标框有点卡顿现象,该怎么调高时钟让其顺畅?



 还真的是,data里面再放一张图片就可以了。做测试,没太在意这个细节,谢谢大佬。
还真的是,data里面再放一张图片就可以了。做测试,没太在意这个细节,谢谢大佬。