@zhaodongyu
感觉它这里针对的是GEMM KERNEL加速核的设计而言的,PPT标题已经给出来了。对经典的CPU流水线来讲,计算阶段和访问阶段已经流水化了,由不同的硬件(ALU/BIU)完成,本身是可以做到并行的。而用计算来掩盖访存延迟一般是HPC计算加速器的做法,因为这种KERNEL 加速器不像CPU有丰富的L1/L2/L3缓存可以用,CPU访存延迟低。计算加速器只能通过大量计算掩盖访存延迟。所以我感觉它这里讲的可能不是RISC-V的特性,而是GEMM阵列的特性。
C
caozilong 发布的帖子
-
回复: 求证:riscv的计算与访存无法并行吗?发布在 MR Series
-
回复: 谁跑过D1a的core_mark分数吗,我这里有T113的跑分,想来对比下发布在 MR Series
A7 大概1.6个DMIPS/MHZ,平均下来每个clk执行1.6条指令,和谷歌标称的A7 1.9 DMIPS/Mhz差别不大,中间可能有编译器优化,运行环境不同引入的差别。
-
回复: 飞桨模型在“周易”NPU上的部署(基于R329开发板)发布在 A Series
@q1215200171 你好,看到你最后两步使用了两个不同的模型,而无需修改后处理代码,所以很好奇,想请教你,这里的用的两个算法模型是同一个么?如果不是,为何resetnet和aipu.bin无缝替换却不用修改后处理的?
谢谢指导~! -
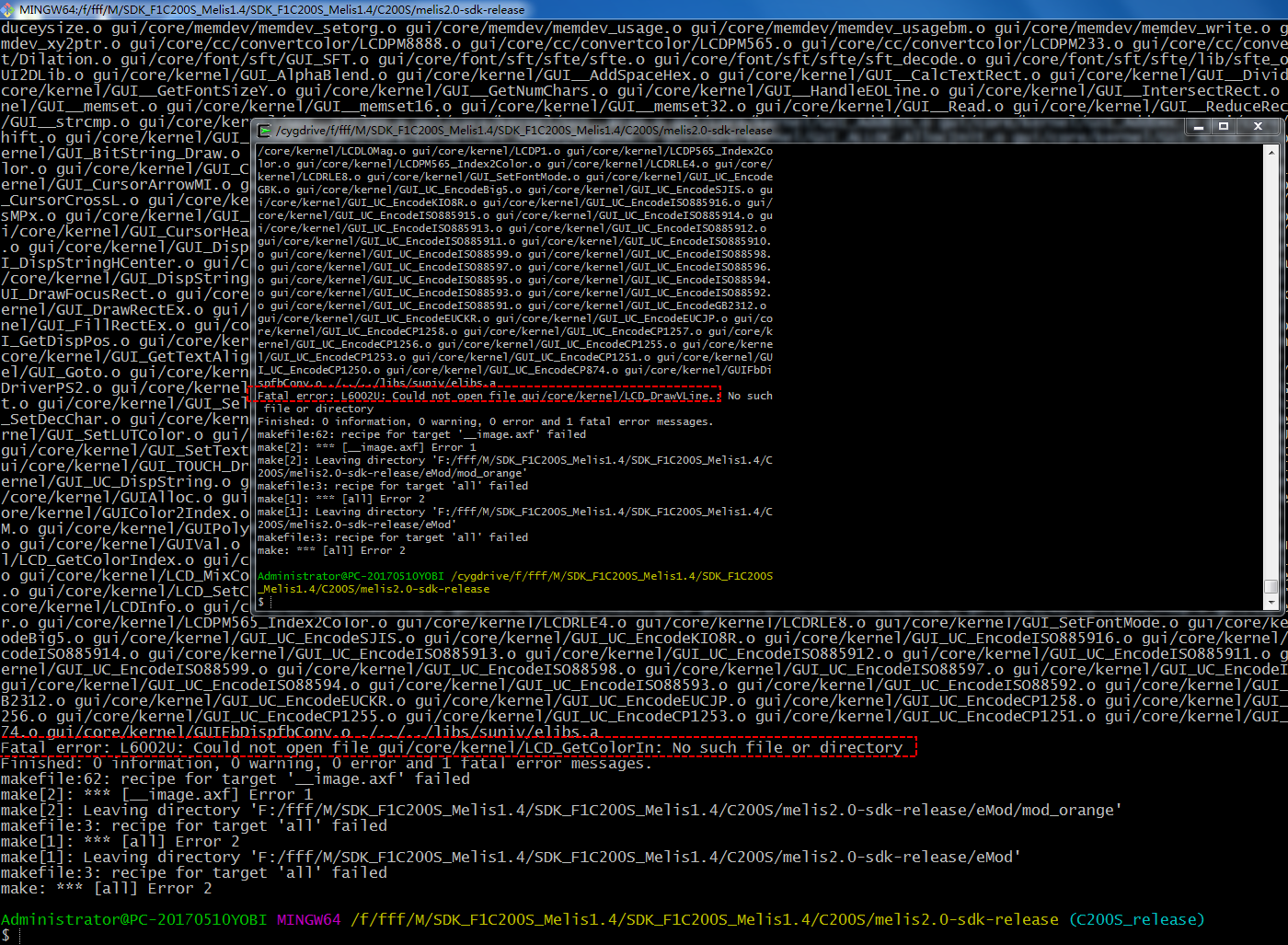
回复: melis4.0开启xr829WIFI驱动后编译报错发布在 RTOS
@honglingjin
调用abort表明这是一个异常处理case, sys_abort函数属于系统porting层。一般定义为调试指令,调试打印,这里定义成死循环也没有问题。至于头文件定义了却找不到,可能和同文件的依赖顺序有关,两个办法处理:
1.找到当前报错文件所在目录,在当前目录下有一个隐藏的 .cmd文件,里面包含了编译此文件的所有头文件依赖列表,看是否有你想要的头文件。
2.甚至你可以直接 在调用处直接while(1)死循环暴力解决,注意加入调试打印,否则出错了也不知道。 -
回复: melis中disp驱动问题发布在 MR Series
@geniusgogo 在 melis中disp驱动问题 中说:
例如:应用分配buffer A/B,第一次显示buffer A,第二次显示buffer B,第三次由于应用不知道前两次显示的是否完成,所以按照应用层交替使用A/B buffer的逻辑,此时又会使用A,而此时底层驱动可能正在刷A,这就导致应用也会同时修改A buffer的数据,造成不同步花屏。
有可能的。
buffer的指针在用户手里,用户如果不加考虑随便写,可能会导致写入正在显示的画面,导致撕裂。
以播放视频的场景为例,一般video framebuffer会有很多个,比如说10个吧,所以显示那边会有一个显示帧队列,比如有三个帧,一帧是刚刚获取的,一帧是正在显示的,还有一帧是刚刚显示完的,通过软件控制时序,是可以保证常态化如此的,你可以理解它有点类似于网络中的滑动窗口,队列中永远都有一个待显示帧,当前帧和已显示帧。并且已显示帧需要回帧后,解锁才能再次写入数据,这样就可以避免撕裂的情况。
如果是UI framebuffer,也可以参考类似的做法,多创建几个帧,并且创建回帧机制。
严谨的做法可能要用到fence机制了,如果你们有 tina sdk,在disp2驱动下有个composoer_init函数,里面的逻辑就是实现fence的,安卓上用的就是这套机制。所以,你说的情况是存在的,但是如果你隔足够安全的时间去送帧,自然每次都是成功的,这也是melis上的做法。
-
回复: melis中disp驱动问题发布在 MR Series
@bookos buffer是零拷贝,驱动内部记录是乒乓指针,buffer由应用去分配。
所以,站在这个层面看显示驱动,你不能只分配一个静态framebuffer,而是至少分配两个,然后传指针进去. -
回复: melis中disp驱动问题发布在 MR Series
@geniusgogo 不会的,驱动内部对显示图层分配了两个buffer,你可以认为是一个pingpong buffer机制,当前写的不是正在显示的那片buffer,两个buffer依赖TCON中断进行同步。
虽然不存在花屏的问题,但是可能存在覆盖的问题,如果你送帧的帧率和TCON刷新率不匹配(太快),可能会覆盖上次还没显示出来的帧。
比如你的帧率要控制在30fps,你就需要通过某种机制保证在这个范围内送帧,误差不要太大, 这方面RTOS做的要比linux 好很多。 -
回复: melis中disp驱动问题发布在 MR Series
@geniusgogo 在 melis中disp驱动问题 中说:
disp驱动要显示一帧图像就是调用disp_ioctl(DISP_LAYER_SET_CONFIG, (void *)arg); ,请问上层如何知道显示一帧结束从而继续显示下一帧并释放资源?
1.依赖TCON中断,TCON终端频率就是通常我们玩游戏的时候理解的刷新率。
2.这是由软件决定的,软件控制的叫帧率,也就是产生图像的频率,图像来源可以是GPU绘制合成的,也可以是来自于VPU解码送过来的,总之,这个帧率是方案决定的。
上层不知道一帧何时开始,何时结束的,上层只需要送帧.由TCON负责同步。你送的帧不一定马上显示出来,要等TCON中断过来,才会真正显示到屏幕上的。
所以你要结合刷新率考虑帧率,帧率上去了,刷新率越大越好,帧率不能超过刷新率,图不变,同样的图刷新多少次,效果是一样的,用户感知不到,自己要有一个帧率的预估,帧率一般由片源决定的,比如30FPS,60FPS等等,帧率要小于刷新率,大于刷新率的帧率是没有意义的。
3.搞清楚这两个”率",帧率和刷新率要配合,而这个配合,是你要觉察的。 -
回复: 在D1上面如何跑melis的D1版本?发布在 MR Series
是否生成了melis_d1-evb-board_uart0_8Mnor.img? 用最新APST上的phinuxsuilt烧录工具去烧录,不要用卡启动固件试一试.
-
回复: 在D1开发板上运行Dahdi和Asterisk IPPBX发布在 MR Series
@xiaowen 绿色子板上的接口是电话线接口吗? RJ11?
普通电话连接到Asterisk后,asterisk通过什么方式实现和电话间的通话? -
回复: 请问哪吒 D1 开发板拔插 HDMI 显示器, 提示sink do not support this mode 是什么问题? 换了两台显示器了.发布在 MR Series
@tigger
哈,有点像是EDID读取到的VID 不支持,每个VID应该对应一种制式,这里可能有两种情况
要么HDMI线的I2C通道异常,读取不到正确的EDID,要么是运气太差,用的两台显示器默认制式不包含在支持列表之内。 -
回复: 围观 D1s EVB发布在 MR Series
@nideyida 在 围观 F133 EVB 中说:
我想用F133做一个语音小电视,接mipi屏幕(要触控),再加一个2+1的麦克风阵列,请问是否可行?会不会出现引脚复用的情况?
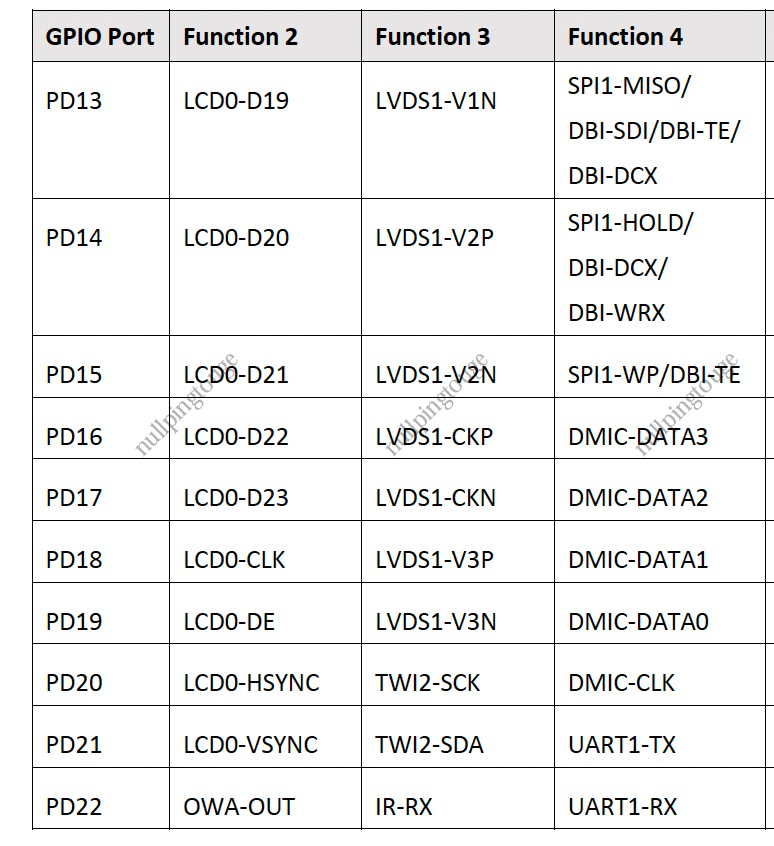
按道理一个dmic data的引脚,可以接两个dmic对吧?时钟我用同一个就可以了吧?好问题,我也想知道,顶你上头条。
-
一条普遍存在于嵌入式实时系统(RTOS)中的嵌套使用互斥量的bug分析发布在 RTOS
这篇文章尝试阐明一条普遍存在于嵌入式实时系统(RTOS)中的bug, 包括ucosii, rt-thread, nuttx在内的大多数RTOS系统中都存在本文要说的问题.虽说是一条bug,但是在实际的项目应用中,只有很小概率会造成严重的后果,因为只有在比较苛刻的几个条件同时满足的时候,它才会表现的比较致命.但伟人墨菲曾经曰过 “如果觉得事件有可能发生,那它就一定会发生”,所以呢,为了保证有不幸遇到这个问题的同学能跨过这个坎儿,或者让大家装X的时候有货,我们就来分析一下这个问题。
首先从优先级反转讲起.
优先级反转
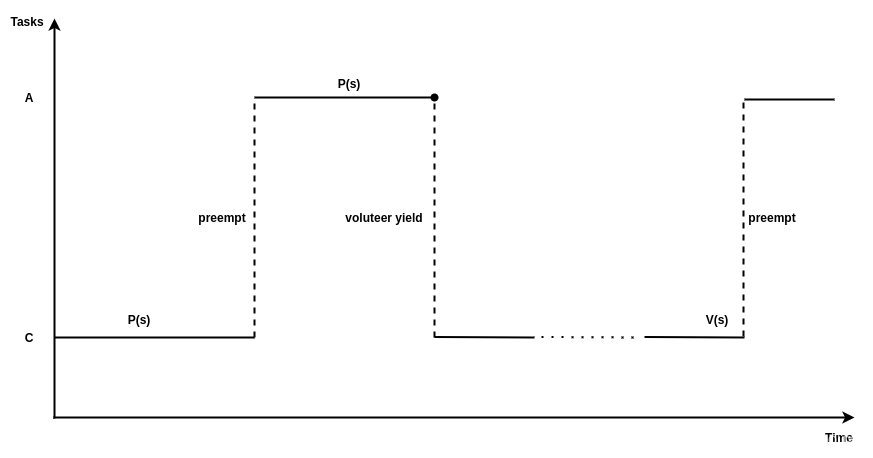
这个世界中,有些东西只属于某一个人,或者说在某一个时间段只能属于某个人,映射到多任务系统中,不同任务之间存在共享资源,操作系统一般会提供mutex等同步机制来保证数据同步.有时候低优先级的任务已经持有了某个共享资源,因此,如果一个高优先级的任务想要访问该共享资源,需要等待低优先级的任务释放该资源,这种高优先级等待低优先级完成后才可以执行的现象被称为优先级翻转(Priority Inversion).下图是一个发生优先级反转的例子,系统一开始任务 C 执行 P(S) 申请访问共享资源 S 并获得 S 的占有权,然后高优先级任务 A 被创建并调度执行,此时任务 A 也需要访问资源 S,但是因为 C 已经占有了资源 S,所以 A 被迫等待资源 S 直到任务 C执行 V(S) 释放资源 S。除非能保证所有任务在访问共享资源时,共享资源都未被其他低优先级的任务占有,否则为了保证数据同步,优先级反转的现象很难避免。一般能够接受系统出现下图中所示的情况,因为任务对共享资源的访问一般都会在较短时间结束,下图中任务 A 虽然在等待一个低优先级的任务 C,但等待的时间是有限的。因为我们基于这样一个前提,所有持有锁的任务对系统来说是有责任的,它必须保证创建的临界区最小,资源使用完毕,立即释放,如果线程没有意识到这种责任,比如在持有阻塞高优先级资源的锁临界区内去睡眠,这就是设计者的责任了.另外关于这个责任的问题,值得一讲的是,互斥量(mutex)和信号量(semaphore)的责任是不一样的,mutex具有属主属性,所以对它的要求更高,拥有mutex的任务更倾向于在尽可能短的时间内释放锁。而semaphore由于没有属主特性,释放锁的时限要求没有那么高。
下图给出了一个更糟糕的优先级反转的例子,假设任务优先级 A>B>C,一开始任务 C 执行 P(S) 申请访问共享资源 S 并获得 S 的占有权;然后任务 A 被创建并调度执行,此时任务 A 也需要访问资源 S,但是因为 C 已经占有了资源S,所以 A 被迫等待资源 S 直到任务 C 执行 V(S) 释放资源 S;但是 C 在执行时,任务 B 被创建并调度执行,此时任务 A 不仅仅需要等待任务 C 还需要等待任务 B,但任务 B 不在临界区中,所以执行时间是不确定的。这种情况对于实时系统来说是致命的,因为高优先级的任务 A 可能永远无法被调度执行,这种高优先级任务可能无限期等待低优先级任务执行的现象被称为无边界优先级反转(unbounded-priority-inversion)。

上面第一幅图是有边界的优先级反转,下面一幅图是无边界优先级反转.当面对更多任务的场景,优先级反转情况会更复杂,更难于辨别,下图中任意一处的task mid 任务都可以反转系统的优先级:
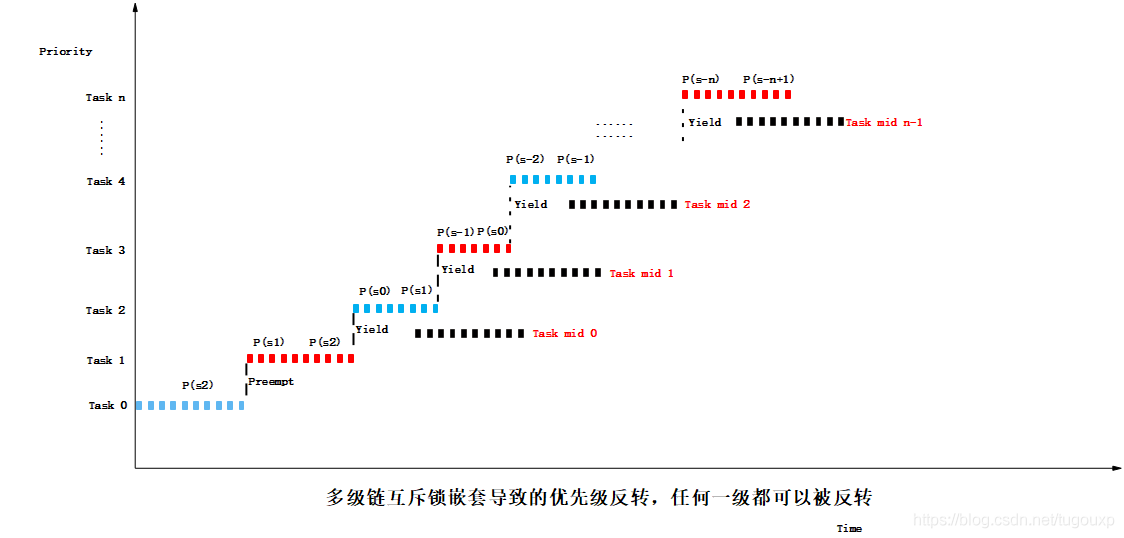
有些同学可能觉得,只要保证任务B能够自觉的每隔一段时间释放处理器(对应任务中周期性的调用sleep)就可以避免无边界的优先级反转,或者让B也拿一个锁,保证它可以在一段时间内释放处理机,但这无疑又让高优先级的任务A多了一层时序依赖,从一开始的依赖C ,到后面又增加了对B的时序依赖。最重要的是,后者不满足硬实时的截止时间要求. 由于C的临界区指令数目一定是固定的,所以执行时间必然固定,所以P对C的时序依赖是可控的,不会超过某个固定值。但B的横插一杠就不同了,首先是给执行时间引入不确定性,其次是,如果放开限制,如果系统存在中级优先级任务B,那是否还有可能存在另一个中等优先级任务序列B1,B2,...,来使依赖链增长? 最终造成总的截至时间不确定。或许还有同学要问,如果优先级最高的任务不止有一个,该怎么办? 其实这个问题本身就已经给出了答案,既然是 “最” 高,就一定只有一个,多于一个就不叫最了,哪怕几个任务都很致命,你也要选出一个来作为肯綮,去解决与其它任务之间的逻辑依赖,具体操作就和应用场景有关了。
如果说你非要有两个“最”高优先级的任务需要处理怎么办?它们是如此紧急以至于哪怕有一个处理不及时你就要完蛋。 那对不起了,真不行,这个世界上,不是所有问题都有答案的不是么?在这种情况下,单核的CPU救不了你,你需要多核SMP或者AMP了,有几个“最”,给几个核,单核只能有一个"最“存在,在单核上,还要啥自行车!
而且,选择“最”重要的任务,本身就带有主观色彩. 重要与不重要,是相对于具体的场景来说的,和平年代,一点皮外伤都要去医院包扎一下,还要打破伤风,防感染。但如果换做在战场上,可能缺胳膊断腿都不算什么了,只有保住脑袋才算是最高优先级的任务,所以这就是优先级的相对性,它是人定义的,三观不同,定义也不同,选择面前,有的人舍生取义,有的人卖国求荣,并没有人逼迫他们.
不要以为这种case很难遇到,实际上,现代很多消费电子中都存在这种场景,音频视频的偶然卡顿,某些事件响应的偶然不及时,可能都是后台发生了优先级反转,只是这种事故即便对最苛刻的用户来讲,也是无关痛痒(你可能会因为视频卡顿而错过某粒进球,但是绝对不会为此而跳楼),所以根本就不会去重视。但是换一种场景就截然不同了。最著名的优先级反转事件,当属美国的好奇号火星车(用的还是大名鼎鼎的VxWorks),大家可以网上搜一下,简直可以作为无边界优先级反转的经典案例写入教科书。下图就是火星车上发生的情况,它只不过是把上面的图用其它工具重绘了一遍。
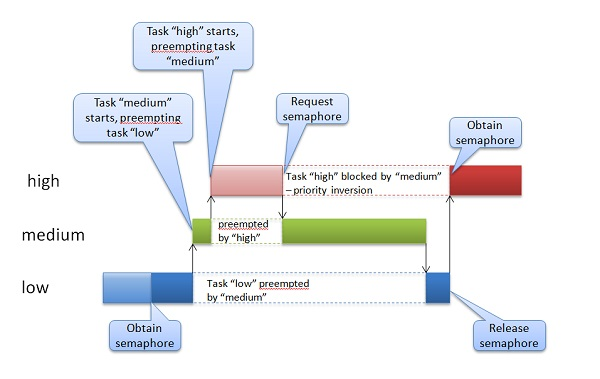
避免优先级反转的两种常见方法是:优先级继承协议(Priority Inheritance Protocol, PIP)和优先级上限协议(Priority Ceiling Protocol, PCP),其中优先级上限协议又被称为优先级天花板协议。两种方法的前提都是优先级可改变,而且是可以动态改变的。优先级上限协议:
为每个mutex设置一个“优先级顶”,“优先级顶”定义为要调用该mutex的所有任务中最高优先级, 一个任务要想对共享资源操作开始一个新的临界区时,它的优先级必须严格高于当前其他试图获取该mutex的任务的“优先级顶”,否则它将被具有中等优先级的任务所阻塞。每个信号量的“优先级顶”是在任务集执行之前通过预分析得到的。优先级继承(也叫优先级捐赠)协议:
优先级继承协议(Priority Inheritance Protocol, PIP)的基本思想是当更高优先级的进程A被进程B阻塞时,B暂时继承A的优先级,这将防止中间优先级的进程抢占进程B使高优先级进程A的阻塞时间延长。优先级继承协议应对优先级反转

优先级天花板协议应对优先级反转

优先级天花板和优先级继承的异同
区别:优先级继承需要将资源owner任务的低优先级提升为和试图获取资源的任务的同样的高优先级,所以,对于实现优先级继承的系统来说,支持任务的同等优先级是必要条件.
所以,在不支持同等优先级的系统中,无法实现优先级继承,只能实现优先级天花板机制.这样的系统有ucosii等等.
所以,区别1,优先级继承只能实现在支持同等优先级的系统中,而且优先级天花板则与系统能否支持同等优先级无关.
联系:
优先级继承是优先级天花板的特殊情况,当天花板优先级和owner任务的优先级相同时,优先级天花板就变成了优先级继承.
Musl库中对优先级天花板和优先级继承的支持
musl的支持策略貌似是不支持!")



UCOSII优先级天花板的实现:
OS_EVENT *OSMutexCreate (INT8U prio, INT8U *perr);
OS_EVENT *OSMutexDel (OS_EVENT *pevent, INT8U opt, INT8U *perr);
void OSMutexPend (OS_EVENT *pevent, INT16U timeout, INT8U *perr);
INT8U OSMutexPost (OS_EVENT *pevent);
INT8U OSMutexQuery (OS_EVENT *pevent, OS_MUTEX_DATA *p_mutex_data);
static void OSMutex_RdyAtPrio (OS_TCB *ptcb, INT8U prio);
BOOLEAN OSMutexAccept (OS_EVENT *pevent, INT8U perr)
OS_EVENT结构体定义:
388 #if (OS_EVENT_EN) && (OS_MAX_EVENTS > 0)
389 typedef struct os_event {
390 INT8U OSEventType; / Type of event control block (see OS_EVENT_TYPE_xxxx) */
391 void OSEventPtr; / Pointer to message or queue structure /
392 INT16U OSEventCnt; / Semaphore Count (not used if other EVENT type) /
393 #if OS_LOWEST_PRIO <= 63
394 INT8U OSEventGrp; / Group corresponding to tasks waiting for event to occur /
395 INT8U OSEventTbl[OS_EVENT_TBL_SIZE]; / List of tasks waiting for event to occur /
396 #else
397 INT16U OSEventGrp; / Group corresponding to tasks waiting for event to occur /
398 INT16U OSEventTbl[OS_EVENT_TBL_SIZE]; / List of tasks waiting for event to occur */
399 #endif
400
401 #if OS_EVENT_NAME_SIZE > 1
402 INT8U OSEventName[OS_EVENT_NAME_SIZE];
403 #endif
404 } OS_EVENT;
405 #endif
OS_EVENT *OSMutexCreate (INT8U prio, INT8U *perr)中,第一个参数prio表示的访问互斥量时使用的优先级。换句话说,当信号量被获取时,一个更高优先级的任务尝试获取该信号量,那么拥有该信号量的任务的优先级将被提升到该优先级。这里需要指定一个优先级,其优先级高于任何竞争互斥锁的任务。其值被记录再pevent->OSEventCnt中.
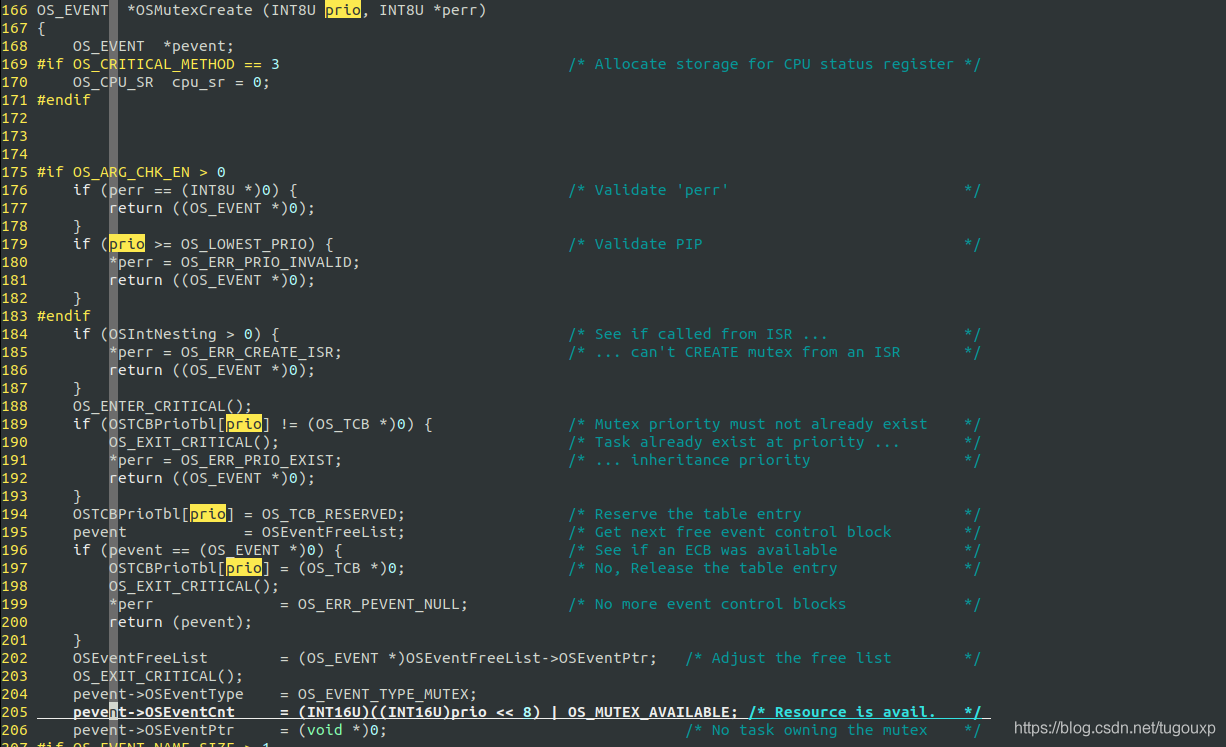
void OSMutexPend (OS_EVENT *pevent, INT16U timeout, INT8U *perr)函数中,如果mutex当前处于有资源的状态,则无论任务的优先级是高还是低,都不改变当前优先级(因为不存在其它优先级的竞争,优先级天花板协议就可以推迟生效,假如竞争不存在,优先级提升就没有必要了).获取后,将owner线程记录再pevent->OSEventPtr中.并且抹去avaliable状态,变为owner任务的优先级.这里还要进行一项检查,确保PIP优先级是所有会竞争mutex的任务中最高的.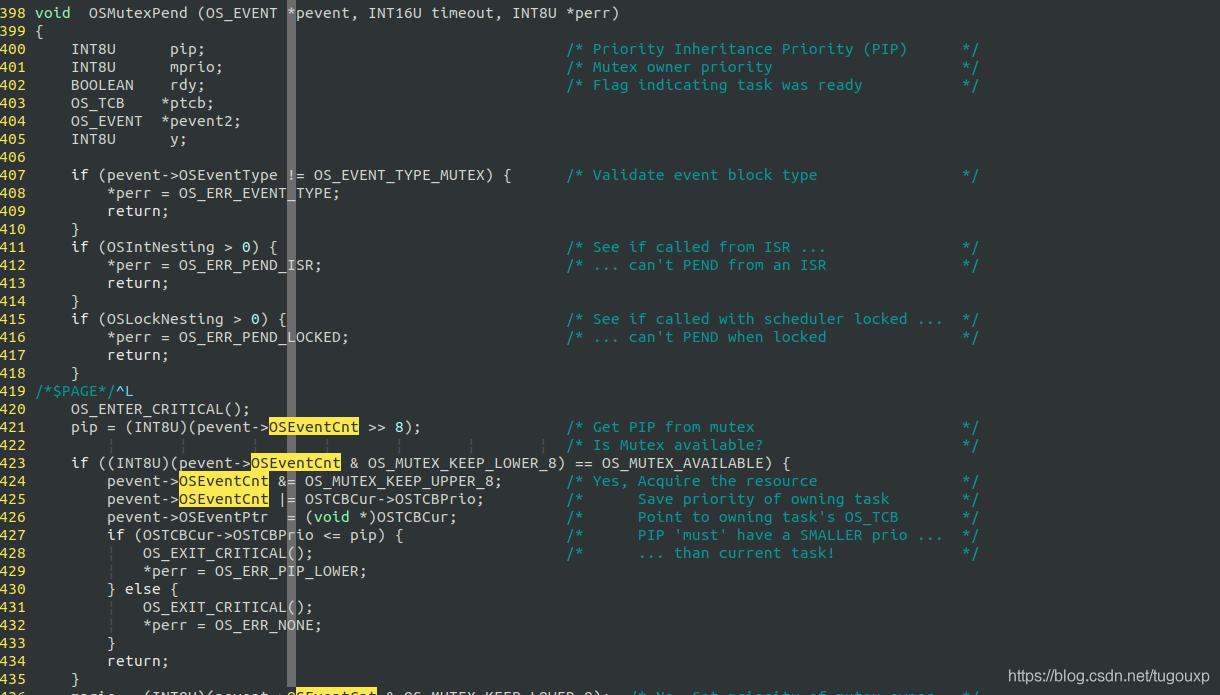
如果mutex当前无资源,则调整owner的优先级到pip级.

这是ucosii的做法,看似没有问题,实际上,这里存在一个bug.
UCOSII Mutex嵌套使用时出现的 bug
下图展示了一个UCOSII Mutex在嵌套使用时出现的Bug,连PIP机制都救不了.
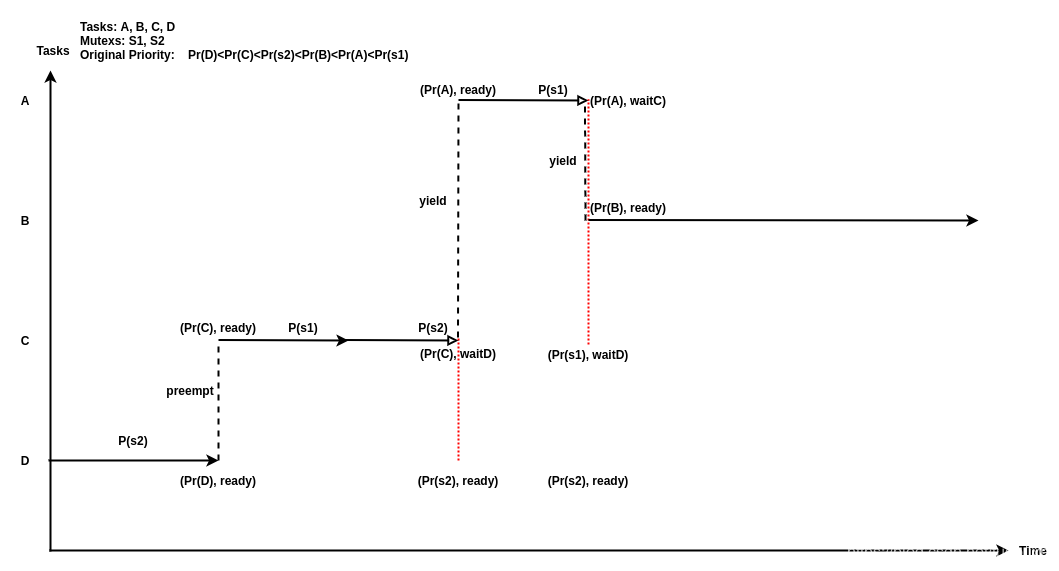
图中包含 4 个任务 A、B、C、D 以及两个互斥信号量 S1、S2。用户设置的原始优先级满足下述关系:PrD < PrC < PrS2 < PrB < PrA < PrS1。假设一开始任务 A、B、C 被延迟并且正在等待时钟中断唤醒,D 是唯一正在运行的任务。首先任务 D 获取信号量S2,然后 C 被唤醒并抢占了 D。C 接着获取了信号量 S1, 然后尝试获取 S2,但因为 S2 已经被 D 占有,所以 C 会被阻塞,因为 PrD < PrC,所以根据协议将D 的优先级提升到 PrS2,并且 D 被调度执行。然后任务 A 被唤醒,因为 A 的优先级最高,所以 A 抢占了 D。此时 A 尝试获取被 C 占有的 S1 ,所以 A 被阻塞,并且 C 的优先级被提升到 PrS1。最后任务 B 被唤醒并执行,但此时已经发生了无边界优先级反转,因为任务 A 可能无限期等待任务 B。并且从图中可以看出,此时任务 B 不占有任何资源,并且原始优先级低于 A。前者何时出让处理器,不可预期。图中括号内的二元组表示该任务当前优先级和状态.从就绪队列的角度看,最高优先级的任务A的优先级,并没有传染给就绪队列的其他任务,因为虽然任务C受到了A的影响,被提升了优先级,但是由于任务C睡眠在了S2上.S1的优先级并没有间接影响到S2的owner任务,也就是D.导致无边界优先级反转的情况再次出现.
这个bug,在rt-thread操作系统中同样存在, 口说无凭,程序为证,下面这段程序没有用法上面的问题,但却可以把一个活活的RTT系统跑死(同样的逻辑我在Nuttx和UCOSII中都跑过,同样有问题,所以这个例子不能说明RTT有问题,只能说它follow的是通常的设计实现,RTT仍然是我向大家首推的系统).
#include <typedef.h> #include <rtthread.h> #include <waitqueue.h> #include <rthw.h> #include <arch.h> #include <log.h> void udelay(unsigned int us); static rt_mutex_t mutex_s1, mutex_s2; static void pri_task_a(void *ARG_UNUSED(para)) { while (1) { rt_thread_delay(2000); __log("before got s1"); rt_mutex_take(mutex_s1, RT_WAITING_FOREVER); __log("got s1"); udelay(100 * 1000 * 1000); __log("after delay 100s"); rt_mutex_release(mutex_s1); __log("release s1"); } } static void pri_task_b(void *ARG_UNUSED(para)) { rt_thread_delay(5000); while (1) { udelay(1); } } static void pri_task_c(void *ARG_UNUSED(para)) { while (1) { rt_thread_delay(1000); __log("before got s1"); rt_mutex_take(mutex_s1, RT_WAITING_FOREVER); __log("got s1"); rt_mutex_take(mutex_s2, RT_WAITING_FOREVER); __log("got s2"); udelay(100 * 1000 * 1000); __log("delay 100s"); rt_mutex_release(mutex_s2); __log("release s2"); rt_mutex_release(mutex_s1); __log("release s1"); } } static void pri_task_d(void *ARG_UNUSED(para)) { while (1) { __log("before got s2"); rt_mutex_take(mutex_s2, RT_WAITING_FOREVER); __log("got s2"); udelay(100 * 1000 * 1000); __log("after delay 100s."); rt_mutex_release(mutex_s2); __log("release s2."); } } /* ----------------------------------------------------------------------------*/ /* * @brief schedule_in_irqlock <test pattern, Thread swith out when iterrupt * disable> */ /* ----------------------------------------------------------------------------*/ void priority_entry(void) { rt_thread_t thread; mutex_s1 = rt_mutex_create("mutexs1", RT_IPC_FLAG_PRIO /*RT_IPC_FLAG_FIFO*/); mutex_s2 = rt_mutex_create("mutexs2", RT_IPC_FLAG_PRIO /*RT_IPC_FLAG_FIFO*/); if (mutex_s1 == RT_NULL || mutex_s2 == RT_NULL) { __err("fatal error"); return; } thread = rt_thread_create("pri_a", pri_task_a, RT_NULL, 0x1000, 0, 10); rt_thread_startup(thread); thread = rt_thread_create("pri_b", pri_task_b, RT_NULL, 0x1000, 1, 10); rt_thread_startup(thread); thread = rt_thread_create("pri_c", pri_task_c, RT_NULL, 0x1000, 2, 10); rt_thread_startup(thread); thread = rt_thread_create("pri_d", pri_task_d, RT_NULL, 0x1000, 3, 10); rt_thread_startup(thread); return; }————————————————
版权声明:本文为CSDN博主「tugouxp」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/tugouxp/article/details/116428458 -
回复: 想请问怎么在d1开发板上通过摄像头实时输出图像到显示器上发布在 MR Series
@whycan 在 想请问怎么在d1开发板上通过摄像头实时输出图像到显示器上 中说:
你是想用 显示屏实时显示摄像头信号吗?
可以通过V4L2获取摄像头数据并显示,可连接UVC/CSI/DVP摄像头等等。一切正常的话,会出现/dev/videoX节点,没有的话就要先解决这个问题了,一般是配置问题,比如UVC设备的话,看一下配置UVC Host 功能有无打开。
/dev/videoX节点是一切功能的基础,先把它搞定,显示的话,可以按照@whycan 晕哥的做法直接投到fb0上看效果(不过fb0只能接受RGB格式,UVC出来的数据要首先做一下格式转换)。
Tina是支持gstrmear框架的,并且适配了各类videosink设备,如果有gstremer加持,直接敲命令
gst-launch-1.0 v4l2src ! videoconvert ! ximagesink
gst-launch-1.0 v4l2src ! videoconvert ! xvimagesink
gst-launch-1.0 v4l2src ! videoconvert ! glimagesink
gst-launch-1.0 v4l2src ! videoconvert ! waylandsink
即可。
当然gst也需要配置一下,默认是没有安装的。 -
回复: V833@Melis4.0 开发QuickStart发布在 RTOS
@pcmxz 在 V833@Melis4.0 开发QuckStart 中说:
终于把melis上支持ap6212/ap6181的驱动搞稳定咯,melis什么时候把自带的ap6203开源啊?
 望分享模组集成的过程,让坛主给你加鸡腿
望分享模组集成的过程,让坛主给你加鸡腿
-
回复: 基于D1,使用opencv调用显示摄像头的图像数据出现问题发布在 MR Series
@xushengrui opencv linux上抓图走的是v4l2框架,可以先单独跑个v4l2抓图用例看是否可行,缩小排查范围.
另外把问题描述清楚,问题就解决了一半,你的描述是比较含糊的. -
回复: V833@Melis4.0 开发QuickStart发布在 RTOS
@whycan 晕哥
 开放会的,可能需要一些时间.
开放会的,可能需要一些时间.
现在通过NDA官方发布或者代理商可以有,具体渠道可以咨询我们的业务人员.
-
V833@Melis4.0 开发QuickStart发布在 RTOS
- Melis4.0简介
Melis3.0及之前的版本过于严格的模块化设计,增加了系统不必要的复杂性,有过分设计之嫌,随着新的特性和问题fix补丁的不断引入,系统出现了僵化,顽固,粘滞,重复的问题, 使设计难以改变,难以重用,难以做正确的事情,八股文式的模块封装机制,产生了大量重复的代码,不但增加了系统运行时负载,还限制了系统的开放能力和方案容量。有鉴于此,Melis4.0是在Melis3.0的基础上,对系统架构进行了重新设计,去除了全系统模块化,混合内核等复杂的内核机制,淡化模块化,采用大内核小模块,弱化混合内核,增强宏内核特性等措施。增加了对Posix, V4L2,OpenMax,MPP, Debug子系统,Linux style的设备管理以及抽象Hardware层的支持,整体向Linux风格靠拢,不但使系统更容易使用, 而且在多媒体处理能力上得到了增强。Melis4.0整体架构如下图所示,其中浅色的ffmpeg/gstreamer组件是未来计划引入的部分,之所以引用gstreamer是因为相对于其它的多媒体框架,Gstreamer整体框架调度性能更优秀,而FFMPEG的跨平台性性能和软编性能够好,可以作为核心编解码组件,两者相辅相成,并不冲突.内核仍然基于熊大的rt-thread进行拓展,作为一款有高度的高性能内核,RT-Thread不但可以适配MCU级的应用方案,更可以支撑Linux级的大型应用方案,这是zephyr, freeRTOS等内核无法比拟的,另外,pthread, shell,以及网络组件等部分也是从熊大社区直接拿来用的,在这里向熊大表示深深的感谢 @熊大.https://www.rt-thread.org/
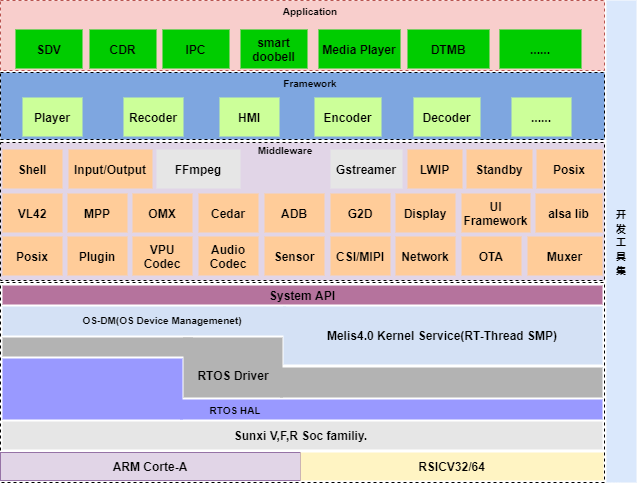
V4L2,OMX, MPP的引入增强的了系统对多媒体的扩展能力和兼容能力,不但可以降低sensor移植时的难度,而且能够有效利用既有Linux上的方案成果,使用户能够快速从Linux向小成本的Melis4.0方案上迁移。
- 环境配置:
sdk目录下 source melis-env.sh,初始化环境变量

选择工程,公版工程为:v833-smart-doorbell

如果需要进行自定义配置,可以在lunch基础上执行make menuconfig,比如选择新的sensor类型等操作可以在这里进行。
当然,如果默认的lunch配置已经满足要求,PASS掉这一步即可。- 编译:
执行make -j4,启动多线程编译:
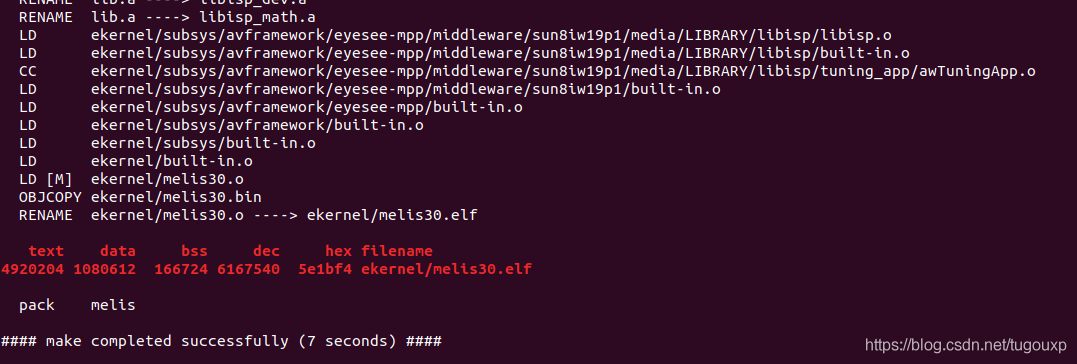
- 打包:
和tina类似,执行pack命令,进行打包。
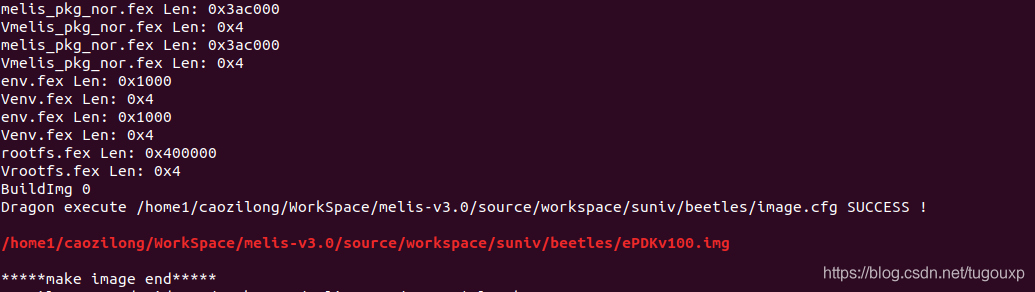
图中用红色字体输出的文件即是打包结果镜像。 - 烧录:
这一步操作和tina完全一致,windows系统使用phinuxsuilt进行烧录:
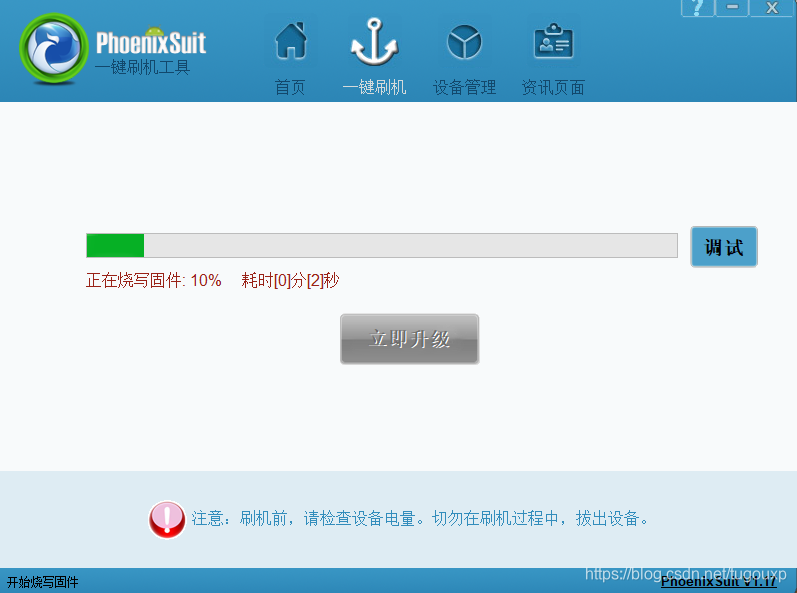
烧录完成后,系统自动启动进入串口终端,等待用户输入命令。 - 验证:
在终端下,输入vin_preview,即可从屏幕端观察到图像输出。

Sensor->CSI->ISP->V4L2->VIPP->DISPLAY的通路用例:

传统上,Melis系统的强项是多媒体处理,主要侧重点是解码,4.0在3.0基础上加强了对编码的支持能力。
今后Melis的发展方向目前想到的有三点:
1.图形图显增强:支持用户界面设计工具,增强用户GUI界面的设计体验。
2.网络:melis虽然移植了各种各样的协议栈,但支持的模组却不多,这方面有待加强。
3.开源:至于方式和形式,等老板们决定。
最后,重点来了,Melis4.0,D1也完美支持!
- 环境配置:
-
回复: 请问D1 Tina可以支持网络流视频播放吗?发布在 MR Series
@nideyida 在 请问D1 Tina可以支持网络流视频播放吗? 中说:
@caozilong 感谢您的回复!我指的是后者,拿到网络流后播放。我看到FFMPEG在源码种有,位置为tina/package/multimedia/ffmpeg,但是选中后不能直接用起来,我理解这个应该是Tina以前的平台支持的吧,现在我针对D1开发板还要做一些对接硬解的适配,是这样的吧?
由于当前的tina没有针对ffmpg做VPU硬解的适配,所以移植FFMPEG的话默认还是使用的软解(适配技术可行性没问题,比如树莓派就适配了mmal用它的GPU来加速硬解,就是开发时间了).
FFMPEG编译原生openwrt就支持,tina基于openwrt,自然也支持。你当前可能是某个开关没打开。
一句话总结,如果你用FFMPEG的话,目前只能享用到RISCV处理器软解的待遇。但是如果你使用我们原生的tplayer, awplayer,或者gstreamer(我们有针对gsteramer适配我们自己的OMX VPU插件)这些,用的就是D1 VPU的硬解。 -
回复: 请问D1 Tina可以支持网络流视频播放吗?发布在 MR Series
@nideyida
你说的直播小电视,是类似于DVB/DTMB直播功能吗?其实都是类似的,DVB/DTMB的话前端需要接tuner,芯片内部还需要集成电视基带IP和一个demux解复用IP,这个D1中没有集成对应IP,所以无法做到数字电视那样的处理。如果是网络流的话就好说了,其实不管是DVB直播流还是网络流媒体,本地都需要开辟一个buffer做缓冲平滑用的,从播放器的角度讲,都是从本地buffer取数据,区别在于数据的来源方式不同罢了,播放器将这部分委托给其他模块处理,播放器本身不感知。
前面说了,Tina播放器是有支持RTSP模块负责stream传递的,所以是支持的。退一步讲,开源的RTSP组件是有的,比如FFMPEG中,自己都可以移植。
或者你可以尝试编译移植一把ffmpeg到RV上,本地搭建流媒体服务和流媒体客户端,实现流媒体的播放,这些都是可以的。